 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum entropy exploration in contextual bandits with neural networks and energy based models
Paper and Code
Oct 12, 2022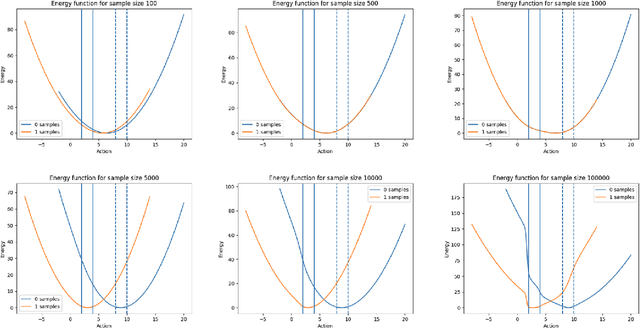

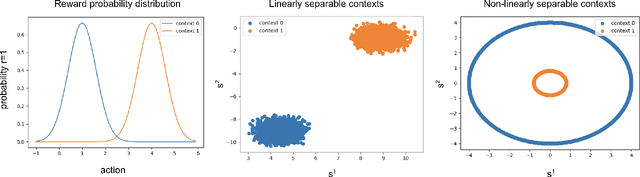
Contextual bandits can solve a huge range of real-world problems. However, current popular algorithms to solve them either rely on linear models, or unreliable uncertainty estimation in non-linear models, which are required to deal with the exploration-exploitation trade-off. Inspired by theories of human cognition, we introduce novel techniques that use maximum entropy exploration, relying on neural networks to find optimal policies in settings with both continuous and discrete action spaces. We present two classes of models, one with neural networks as reward estimators, and the other with energy based models, which model the probability of obtaining an optimal reward given an action. We evaluate the performance of these models in static and dynamic contextual bandit simulation environments. We show that both techniques outperform well-known standard algorithms, where energy based models have the best overall performance. This provides practitioners with new techniques that perform well in static and dynamic settings, and are particularly well suited to non-linear scenarios with continuous action spaces.