 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based Neural Network Models with Multiple Self-Supervised Auxiliary Tasks
Dec 04, 2020

Self-supervised learning is currently gaining a lot of attention, as it allows neural networks to learn robust representations from large quantities of unlabeled data. Additionally, multi-task learning can further improve representation learning by training networks simultaneously on related tasks, leading to significant performance improvements. In this paper, we propose three novel self-supervised auxiliary tasks to train graph-based neural network models in a multi-task fashion. Since Graph Convolutional Networks are among the most promising approaches for capturing relationships among structured data points, we use them as a building block to achieve competitive results on standard semi-supervised graph classification tasks.
Learning Combinations of Activation Functions
Jan 29, 2018



In the last decade, an active area of research has been devoted to design novel activation functions that are able to help deep neural networks to converge, obtaining better performance. The training procedure of these architectures usually involves optimization of the weights of their layers only, while non-linearities are generally pre-specified and their (possible) parameters are usually considered as hyper-parameters to be tuned manually. In this paper, we introduce two approaches to automatically learn different combinations of base activation functions (such as the identity function, ReLU, and tanh) during the training phase. We present a thorough comparison of our novel approaches with well-known architectures (such as LeNet-5, AlexNet, and ResNet-56) on three standard datasets (Fashion-MNIST, CIFAR-10, and ILSVRC-2012), showing substantial improvements in the overall performance, such as an increase in the top-1 accuracy for AlexNet on ILSVRC-2012 of 3.01 percentage points.
Automated Pruning for Deep Neural Network Compression
Dec 05, 2017



In this work we present a method to improve the pruning step of the current state-of-the-art methodology to compress neural networks. The novelty of the proposed pruning technique is in its differentiability, which allows pruning to be performed during the backpropagation phase of the network training. This enables an end-to-end learning and strongly reduces the training time. The technique is based on a family of differentiable pruning functions and a new regularizer specifically designed to enforce pruning. The experimental results show that the joint optimization of both the thresholds and the network weights permits to reach a higher compression rate, reducing the number of weights of the pruned network by a further 14% to 33% with respect to the current state-of-the-art. Furthermore, we believe that this is the first study where the generalization capabilities in transfer learning tasks of the features extracted by a pruned network are analyzed. To achieve this goal, we show that the representations learned using the proposed pruning methodology maintain the same effectiveness and generality of those learned by the corresponding non-compressed network on a set of different recognition tasks.
Dynamic Graph Convolutional Networks
Apr 20, 2017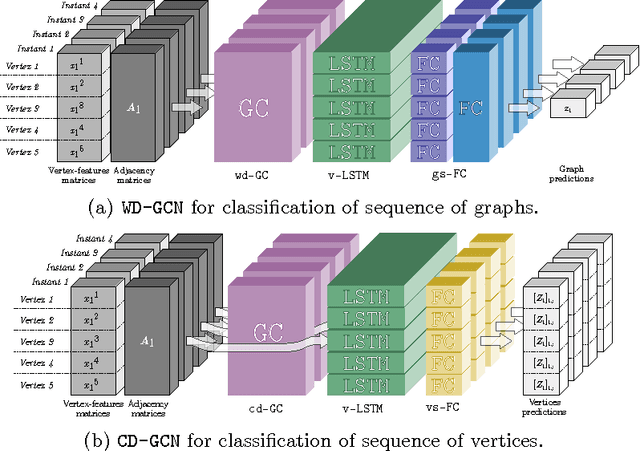
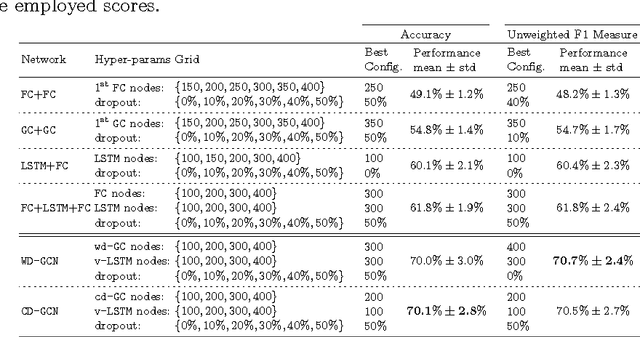
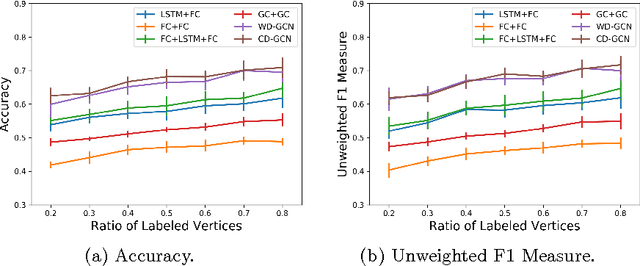
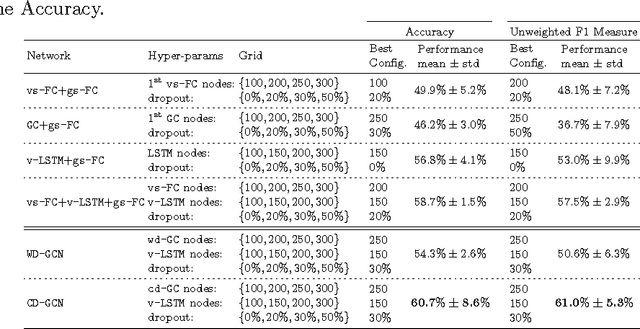
Many different classification tasks need to manage structured data, which are usually modeled as graphs. Moreover, these graphs can be dynamic, meaning that the vertices/edges of each graph may change during time. Our goal is to jointly exploit structured data and temporal information through the use of a neural network model. To the best of our knowledge, this task has not been addressed using these kind of architectures. For this reason, we propose two novel approaches, which combine Long Short-Term Memory networks and Graph Convolutional Networks to learn long short-term dependencies together with graph structure. The quality of our methods is confirmed by the promising results achieved.