 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross-Entropy-based Method to Perform Information-based Feature Selection
Paper and Code
May 22, 2017
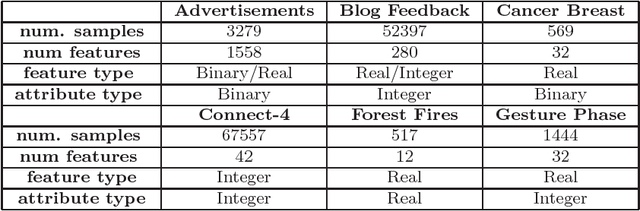
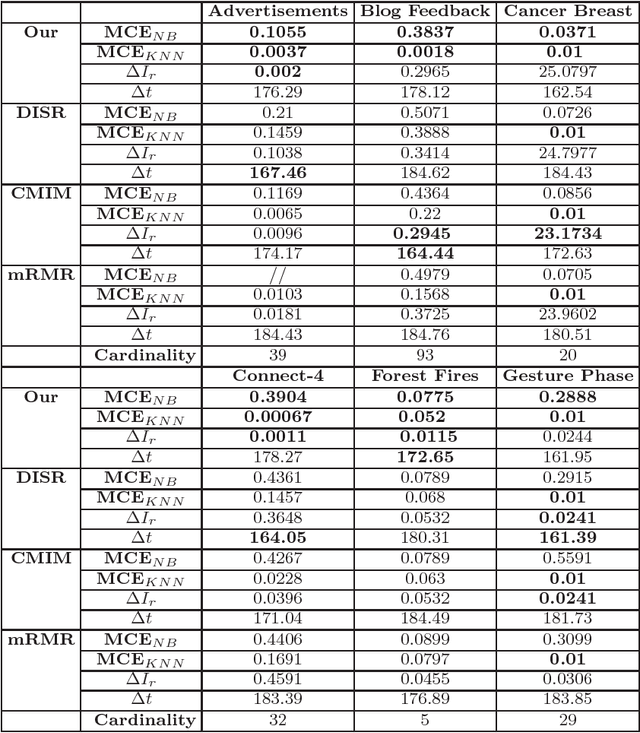
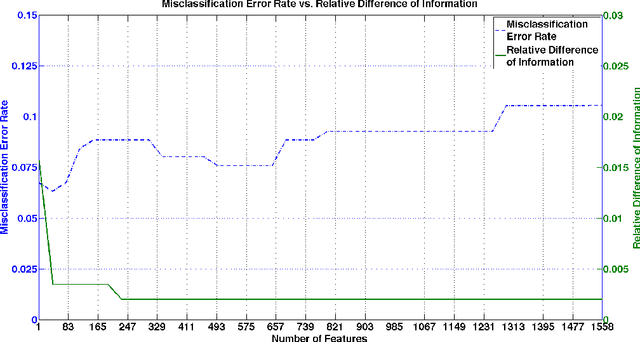
From a machine learning point of view, identifying a subset of relevant features from a real data set can be useful to improve the results achieved by classification methods and to reduce their time and space complexity. To achieve this goal, feature selection methods are usually employed. These approaches assume that the data contains redundant or irrelevant attributes that can be eliminated. In this work, we propose a novel algorithm to manage the optimization problem that is at the foundation of the Mutual Information feature selection methods. Furthermore, our novel approach is able to estimate automatically the number of dimensions to retain. The quality of our method is confirmed by the promising results achieved on standard real data sets.