 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruncating Trajectories in Monte Carlo Policy Evaluation: an Adaptive Approach
Paper and Code



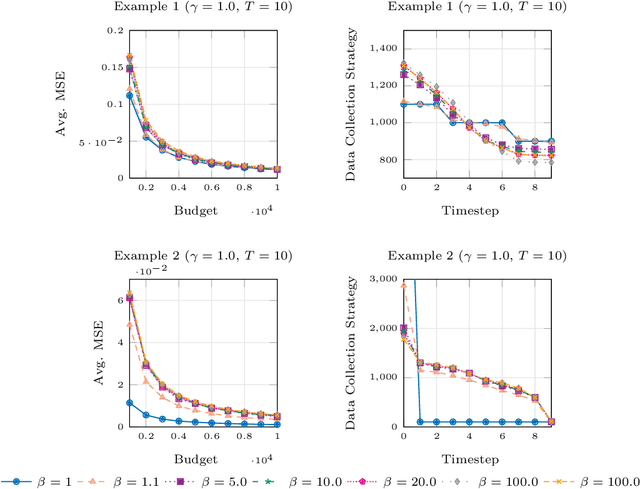
Policy evaluation via Monte Carlo (MC) simulation is at the core of many MC Reinforcement Learning (RL) algorithms (e.g., policy gradient methods). In this context, the designer of the learning system specifies an interaction budget that the agent usually spends by collecting trajectories of fixed length within a simulator. However, is this data collection strategy the best option? To answer this question, in this paper, we propose as a quality index a surrogate of the mean squared error of a return estimator that uses trajectories of different lengths, i.e., \emph{truncated}. Specifically, this surrogate shows the sub-optimality of the fixed-length trajectory schedule. Furthermore, it suggests that adaptive data collection strategies that spend the available budget sequentially can allocate a larger portion of transitions in timesteps in which more accurate sampling is required to reduce the error of the final estimate. Building on these findings, we present an adaptive algorithm called Robust and Iterative Data collection strategy Optimization (RIDO). The main intuition behind RIDO is to split the available interaction budget into mini-batches. At each round, the agent determines the most convenient schedule of trajectories that minimizes an empirical and robust version of the surrogate of the estimator's error. After discussing the theoretical properties of our method, we conclude by assessing its performance across multiple domains. Our results show that RIDO can adapt its trajectory schedule toward timesteps where more sampling is required to increase the quality of the final estimation.