 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Search with High-Dimensional Context Variables
Paper and Code
Nov 10, 2016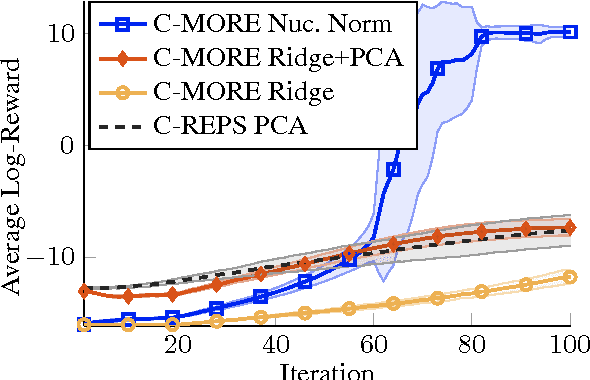
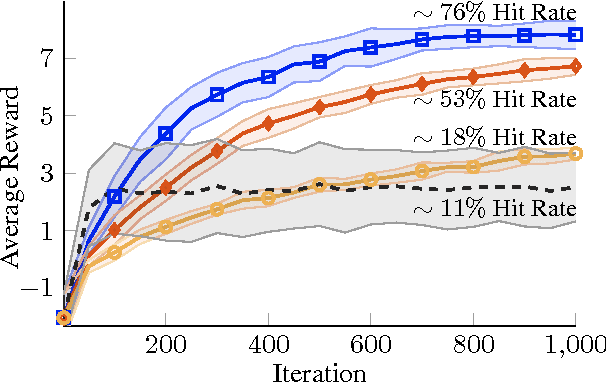

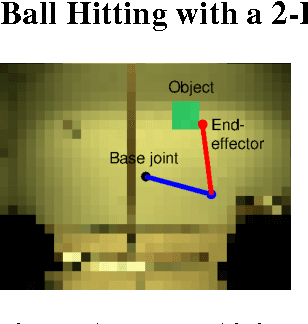
Direct contextual policy search methods learn to improve policy parameters and simultaneously generalize these parameters to different context or task variables. However, learning from high-dimensional context variables, such as camera images, is still a prominent problem in many real-world tasks. A naive application of unsupervised dimensionality reduction methods to the context variables, such as principal component analysis, is insufficient as task-relevant input may be ignored. In this paper, we propose a contextual policy search method in the model-based relative entropy stochastic search framework with integrated dimensionality reduction. We learn a model of the reward that is locally quadratic in both the policy parameters and the context variables. Furthermore, we perform supervised linear dimensionality reduction on the context variables by nuclear norm regularization. The experimental results show that the proposed method outperforms naive dimensionality reduction via principal component analysis and a state-of-the-art contextual policy search method.