 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible image analysis for law enforcement agencies with deep neural networks to determine: where, who and what
May 15, 2024Due to the increasing need for effective security measures and the integration of cameras in commercial products, a hugeamount of visual data is created today. Law enforcement agencies (LEAs) are inspecting images and videos to findradicalization, propaganda for terrorist organizations and illegal products on darknet markets. This is time consuming.Instead of an undirected search, LEAs would like to adapt to new crimes and threats, and focus only on data from specificlocations, persons or objects, which requires flexible interpretation of image content. Visual concept detection with deepconvolutional neural networks (CNNs) is a crucial component to understand the image content. This paper has fivecontributions. The first contribution allows image-based geo-localization to estimate the origin of an image. CNNs andgeotagged images are used to create a model that determines the location of an image by its pixel values. The secondcontribution enables analysis of fine-grained concepts to distinguish sub-categories in a generic concept. The proposedmethod encompasses data acquisition and cleaning and concept hierarchies. The third contribution is the recognition ofperson attributes (e.g., glasses or moustache) to enable query by textual description for a person. The person-attributeproblem is treated as a specific sub-task of concept classification. The fourth contribution is an intuitive image annotationtool based on active learning. Active learning allows users to define novel concepts flexibly and train CNNs with minimalannotation effort. The fifth contribution increases the flexibility for LEAs in the query definition by using query expansion.Query expansion maps user queries to known and detectable concepts. Therefore, no prior knowledge of the detectableconcepts is required for the users. The methods are validated on data with varying locations (popular and non-touristiclocations), varying person attributes (CelebA dataset), and varying number of annotations.
Real-Time Resource Allocation for Tracking Systems
Sep 21, 2020
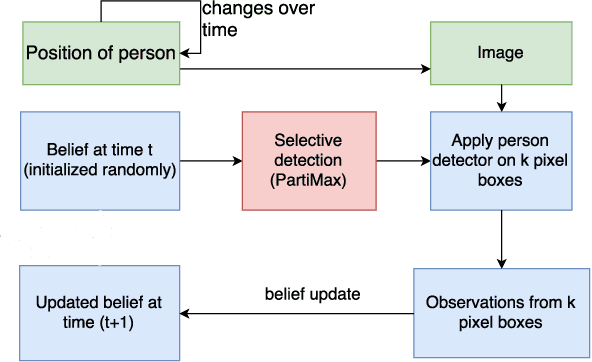

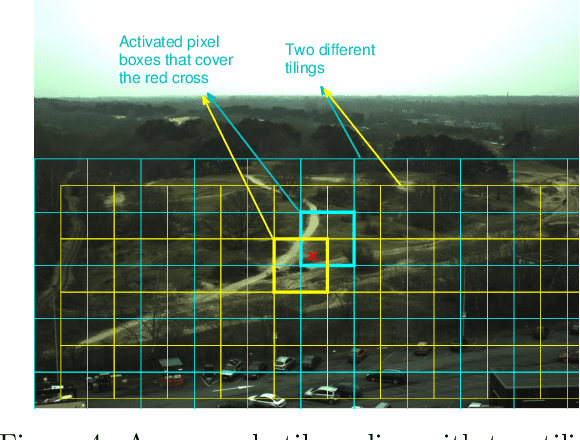
Automated tracking is key to many computer vision applications. However, many tracking systems struggle to perform in real-time due to the high computational cost of detecting people, especially in ultra high resolution images. We propose a new algorithm called \emph{PartiMax} that greatly reduces this cost by applying the person detector only to the relevant parts of the image. PartiMax exploits information in the particle filter to select $k$ of the $n$ candidate \emph{pixel boxes} in the image. We prove that PartiMax is guaranteed to make a near-optimal selection with error bounds that are independent of the problem size. Furthermore, empirical results on a real-life dataset show that our system runs in real-time by processing only 10\% of the pixel boxes in the image while still retaining 80\% of the original tracking performance achieved when processing all pixel boxes.
* http://auai.org/uai2017/proceedings/papers/130.pdf
Deception Detection by 2D-to-3D Face Reconstruction from Videos
Dec 26, 2018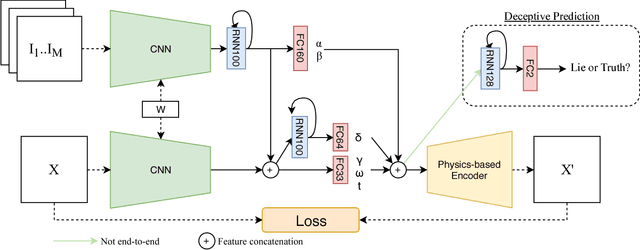


Lies and deception are common phenomena in society, both in our private and professional lives. However, humans are notoriously bad at accurate deception detection. Based on the literature, human accuracy of distinguishing between lies and truthful statements is 54% on average, in other words it is slightly better than a random guess. While people do not much care about this issue, in high-stakes situations such as interrogations for series crimes and for evaluating the testimonies in court cases, accurate deception detection methods are highly desirable. To achieve a reliable, covert, and non-invasive deception detection, we propose a novel method that jointly extracts reliable low- and high-level facial features namely, 3D facial geometry, skin reflectance, expression, head pose, and scene illumination in a video sequence. Then these features are modeled using a Recurrent Neural Network to learn temporal characteristics of deceptive and honest behavior. We evaluate the proposed method on the Real-Life Trial (RLT) dataset that contains high-stake deceptive and honest videos recorded in courtrooms. Our results show that the proposed method (with an accuracy of 72.8%) improves the state of the art as well as outperforming the use of manually coded facial attributes 67.6%) in deception detection.