 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Submodular Value Functions For Scaling Up Active Perception
Paper and Code
Sep 21, 2020
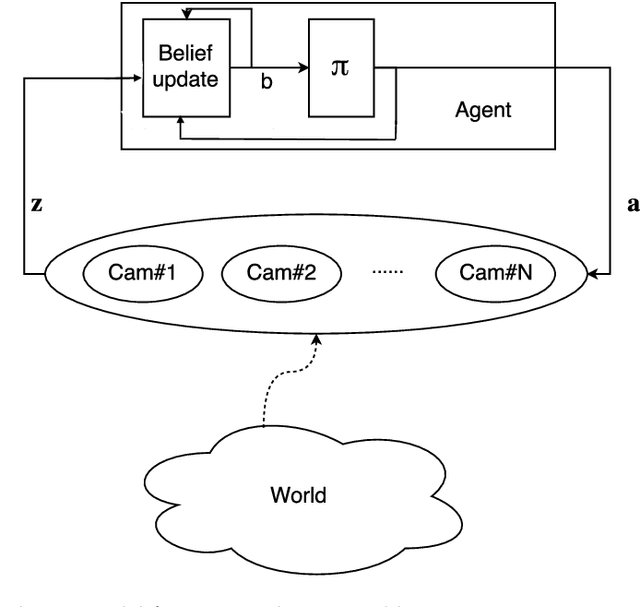
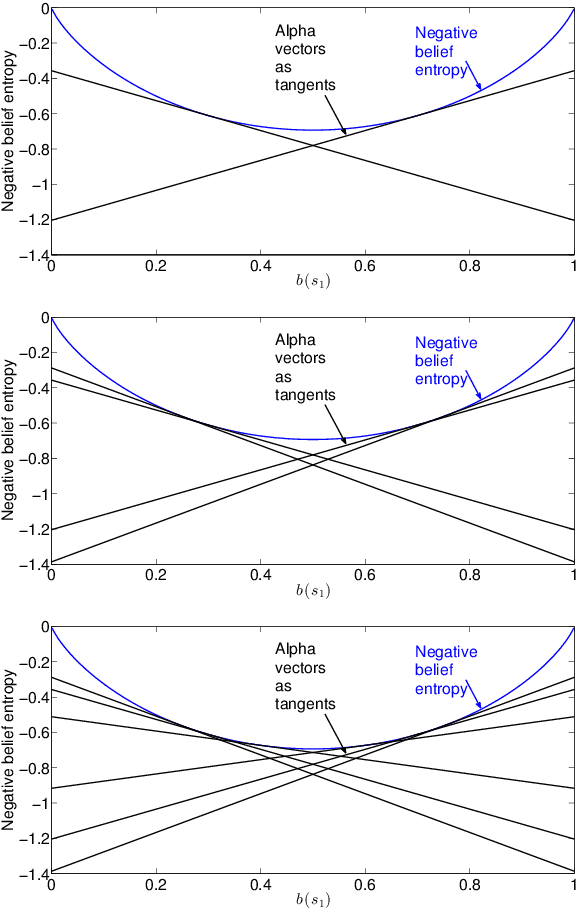
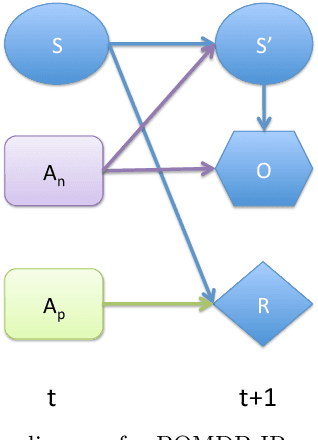
In active perception tasks, an agent aims to select sensory actions that reduce its uncertainty about one or more hidden variables. While partially observable Markov decision processes (POMDPs) provide a natural model for such problems, reward functions that directly penalize uncertainty in the agent's belief can remove the piecewise-linear and convex property of the value function required by most POMDP planners. Furthermore, as the number of sensors available to the agent grows, the computational cost of POMDP planning grows exponentially with it, making POMDP planning infeasible with traditional methods. In this article, we address a twofold challenge of modeling and planning for active perception tasks. We show the mathematical equivalence of $\rho$POMDP and POMDP-IR, two frameworks for modeling active perception tasks, that restore the PWLC property of the value function. To efficiently plan for active perception tasks, we identify and exploit the independence properties of POMDP-IR to reduce the computational cost of solving POMDP-IR (and $\rho$POMDP). We propose greedy point-based value iteration (PBVI), a new POMDP planning method that uses greedy maximization to greatly improve scalability in the action space of an active perception POMDP. Furthermore, we show that, under certain conditions, including submodularity, the value function computed using greedy PBVI is guaranteed to have bounded error with respect to the optimal value function. We establish the conditions under which the value function of an active perception POMDP is guaranteed to be submodular. Finally, we present a detailed empirical analysis on a dataset collected from a multi-camera tracking system employed in a shopping mall. Our method achieves similar performance to existing methods but at a fraction of the computational cost leading to better scalability for solving active perception tasks.