 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-processing Private Synthetic Data for Improving Utility on Selected Measures
May 24, 2023



Existing private synthetic data generation algorithms are agnostic to downstream tasks. However, end users may have specific requirements that the synthetic data must satisfy. Failure to meet these requirements could significantly reduce the utility of the data for downstream use. We introduce a post-processing technique that improves the utility of the synthetic data with respect to measures selected by the end user, while preserving strong privacy guarantees and dataset quality. Our technique involves resampling from the synthetic data to filter out samples that do not meet the selected utility measures, using an efficient stochastic first-order algorithm to find optimal resampling weights. Through comprehensive numerical experiments, we demonstrate that our approach consistently improves the utility of synthetic data across multiple benchmark datasets and state-of-the-art synthetic data generation algorithms.
Rapid Development of Compositional AI
Feb 12, 2023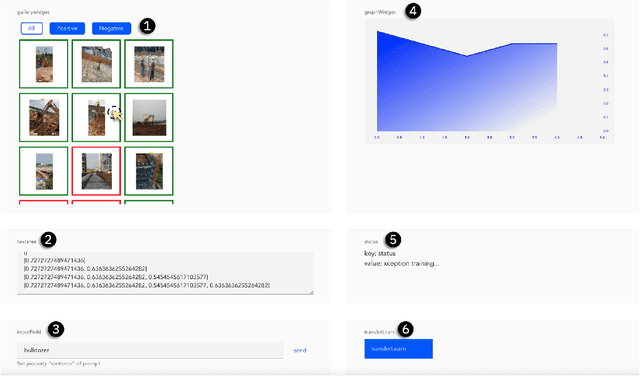
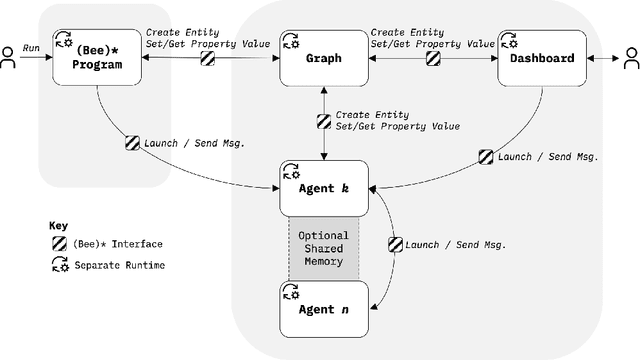
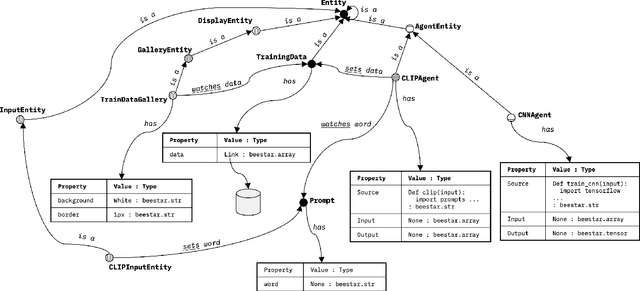

Compositional AI systems, which combine multiple artificial intelligence components together with other application components to solve a larger problem, have no known pattern of development and are often approached in a bespoke and ad hoc style. This makes development slower and harder to reuse for future applications. To support the full rapid development cycle of compositional AI applications, we have developed a novel framework called (Bee)* (written as a regular expression and pronounced as "beestar"). We illustrate how (Bee)* supports building integrated, scalable, and interactive compositional AI applications with a simplified developer experience.
* Accepted to ICSE 2023, NIER track