 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Deformation Meta-Networks for One-Shot Learning
Paper and Code


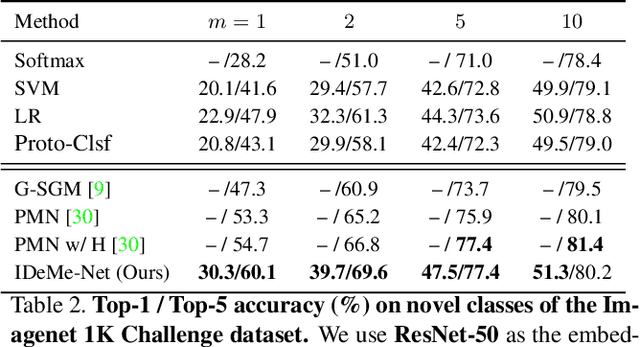

Humans can robustly learn novel visual concepts even when images undergo various deformations and loose certain information. Mimicking the same behavior and synthesizing deformed instances of new concepts may help visual recognition systems perform better one-shot learning, i.e., learning concepts from one or few examples. Our key insight is that, while the deformed images may not be visually realistic, they still maintain critical semantic information and contribute significantly to formulating classifier decision boundaries. Inspired by the recent progress of meta-learning, we combine a meta-learner with an image deformation sub-network that produces additional training examples, and optimize both models in an end-to-end manner. The deformation sub-network learns to deform images by fusing a pair of images -- a probe image that keeps the visual content and a gallery image that diversifies the deformations. We demonstrate results on the widely used one-shot learning benchmarks (miniImageNet and ImageNet 1K Challenge datasets), which significantly outperform state-of-the-art approaches.