 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSplain: Sparse and Smooth Explainer for Retinopathy of Prematurity Classification
Dec 08, 2025Neural networks are frequently used in medical diagnosis. However, due to their black-box nature, model explainers are used to help clinicians understand better and trust model outputs. This paper introduces an explainer method for classifying Retinopathy of Prematurity (ROP) from fundus images. Previous methods fail to generate explanations that preserve input image structures such as smoothness and sparsity. We introduce Sparse and Smooth Explainer (SSplain), a method that generates pixel-wise explanations while preserving image structures by enforcing smoothness and sparsity. This results in realistic explanations to enhance the understanding of the given black-box model. To achieve this goal, we define an optimization problem with combinatorial constraints and solve it using the Alternating Direction Method of Multipliers (ADMM). Experimental results show that SSplain outperforms commonly used explainers in terms of both post-hoc accuracy and smoothness analyses. Additionally, SSplain identifies features that are consistent with domain-understandable features that clinicians consider as discriminative factors for ROP. We also show SSplain's generalization by applying it to additional publicly available datasets. Code is available at https://github.com/neu-spiral/SSplain.
Recursive Deep Inverse Reinforcement Learning
Apr 21, 2025Inferring an adversary's goals from exhibited behavior is crucial for counterplanning and non-cooperative multi-agent systems in domains like cybersecurity, military, and strategy games. Deep Inverse Reinforcement Learning (IRL) methods based on maximum entropy principles show promise in recovering adversaries' goals but are typically offline, require large batch sizes with gradient descent, and rely on first-order updates, limiting their applicability in real-time scenarios. We propose an online Recursive Deep Inverse Reinforcement Learning (RDIRL) approach to recover the cost function governing the adversary actions and goals. Specifically, we minimize an upper bound on the standard Guided Cost Learning (GCL) objective using sequential second-order Newton updates, akin to the Extended Kalman Filter (EKF), leading to a fast (in terms of convergence) learning algorithm. We demonstrate that RDIRL is able to recover cost and reward functions of expert agents in standard and adversarial benchmark tasks. Experiments on benchmark tasks show that our proposed approach outperforms several leading IRL algorithms.
Dependency-aware Maximum Likelihood Estimation for Active Learning
Mar 07, 2025Active learning aims to efficiently build a labeled training set by strategically selecting samples to query labels from annotators. In this sequential process, each sample acquisition influences subsequent selections, causing dependencies among samples in the labeled set. However, these dependencies are overlooked during the model parameter estimation stage when updating the model using Maximum Likelihood Estimation (MLE), a conventional method that assumes independent and identically distributed (i.i.d.) data. We propose Dependency-aware MLE (DMLE), which corrects MLE within the active learning framework by addressing sample dependencies typically neglected due to the i.i.d. assumption, ensuring consistency with active learning principles in the model parameter estimation process. This improved method achieves superior performance across multiple benchmark datasets, reaching higher performance in earlier cycles compared to conventional MLE. Specifically, we observe average accuracy improvements of 6\%, 8.6\%, and 10.5\% for $k=1$, $k=5$, and $k=10$ respectively, after collecting the first 100 samples, where entropy is the acquisition function and $k$ is the query batch size acquired at every active learning cycle.
MarkovType: A Markov Decision Process Strategy for Non-Invasive Brain-Computer Interfaces Typing Systems
Dec 20, 2024Brain-Computer Interfaces (BCIs) help people with severe speech and motor disabilities communicate and interact with their environment using neural activity. This work focuses on the Rapid Serial Visual Presentation (RSVP) paradigm of BCIs using noninvasive electroencephalography (EEG). The RSVP typing task is a recursive task with multiple sequences, where users see only a subset of symbols in each sequence. Extensive research has been conducted to improve classification in the RSVP typing task, achieving fast classification. However, these methods struggle to achieve high accuracy and do not consider the typing mechanism in the learning procedure. They apply binary target and non-target classification without including recursive training. To improve performance in the classification of symbols while controlling the classification speed, we incorporate the typing setup into training by proposing a Partially Observable Markov Decision Process (POMDP) approach. To the best of our knowledge, this is the first work to formulate the RSVP typing task as a POMDP for recursive classification. Experiments show that the proposed approach, MarkovType, results in a more accurate typing system compared to competitors. Additionally, our experiments demonstrate that while there is a trade-off between accuracy and speed, MarkovType achieves the optimal balance between these factors compared to other methods.
Learning Physics Informed Neural ODEs With Partial Measurements
Dec 11, 2024



Learning dynamics governing physical and spatiotemporal processes is a challenging problem, especially in scenarios where states are partially measured. In this work, we tackle the problem of learning dynamics governing these systems when parts of the system's states are not measured, specifically when the dynamics generating the non-measured states are unknown. Inspired by state estimation theory and Physics Informed Neural ODEs, we present a sequential optimization framework in which dynamics governing unmeasured processes can be learned. We demonstrate the performance of the proposed approach leveraging numerical simulations and a real dataset extracted from an electro-mechanical positioning system. We show how the underlying equations fit into our formalism and demonstrate the improved performance of the proposed method when compared with baselines.
KODA: A Data-Driven Recursive Model for Time Series Forecasting and Data Assimilation using Koopman Operators
Sep 29, 2024



Approaches based on Koopman operators have shown great promise in forecasting time series data generated by complex nonlinear dynamical systems (NLDS). Although such approaches are able to capture the latent state representation of a NLDS, they still face difficulty in long term forecasting when applied to real world data. Specifically many real-world NLDS exhibit time-varying behavior, leading to nonstationarity that is hard to capture with such models. Furthermore they lack a systematic data-driven approach to perform data assimilation, that is, exploiting noisy measurements on the fly in the forecasting task. To alleviate the above issues, we propose a Koopman operator-based approach (named KODA - Koopman Operator with Data Assimilation) that integrates forecasting and data assimilation in NLDS. In particular we use a Fourier domain filter to disentangle the data into a physical component whose dynamics can be accurately represented by a Koopman operator, and residual dynamics that represents the local or time varying behavior that are captured by a flexible and learnable recursive model. We carefully design an architecture and training criterion that ensures this decomposition lead to stable and long-term forecasts. Moreover, we introduce a course correction strategy to perform data assimilation with new measurements at inference time. The proposed approach is completely data-driven and can be learned end-to-end. Through extensive experimental comparisons we show that KODA outperforms existing state of the art methods on multiple time series benchmarks such as electricity, temperature, weather, lorenz 63 and duffing oscillator demonstrating its superior performance and efficacy along the three tasks a) forecasting, b) data assimilation and c) state prediction.
Continuously Optimizing Radar Placement with Model Predictive Path Integrals
May 30, 2024Continuously optimizing sensor placement is essential for precise target localization in various military and civilian applications. While information theory has shown promise in optimizing sensor placement, many studies oversimplify sensor measurement models or neglect dynamic constraints of mobile sensors. To address these challenges, we employ a range measurement model that incorporates radar parameters and radar-target distance, coupled with Model Predictive Path Integral (MPPI) control to manage complex environmental obstacles and dynamic constraints. We compare the proposed approach against stationary radars or simplified range measurement models based on the root mean squared error (RMSE) of the Cubature Kalman Filter (CKF) estimator for the targets' state. Additionally, we visualize the evolving geometry of radars and targets over time, highlighting areas of highest measurement information gain, demonstrating the strengths of the approach. The proposed strategy outperforms stationary radars and simplified range measurement models in target localization, achieving a 38-74% reduction in mean RMSE and a 33-79% reduction in the upper tail of the 90% Highest Density Interval (HDI) over 500 Monte Carl (MC) trials across all time steps. Code will be made publicly available upon acceptance.
Multistatic-Radar RCS-Signature Recognition of Aerial Vehicles: A Bayesian Fusion Approach
Mar 08, 2024



Radar Automated Target Recognition (RATR) for Unmanned Aerial Vehicles (UAVs) involves transmitting Electromagnetic Waves (EMWs) and performing target type recognition on the received radar echo, crucial for defense and aerospace applications. Previous studies highlighted the advantages of multistatic radar configurations over monostatic ones in RATR. However, fusion methods in multistatic radar configurations often suboptimally combine classification vectors from individual radars probabilistically. To address this, we propose a fully Bayesian RATR framework employing Optimal Bayesian Fusion (OBF) to aggregate classification probability vectors from multiple radars. OBF, based on expected 0-1 loss, updates a Recursive Bayesian Classification (RBC) posterior distribution for target UAV type, conditioned on historical observations across multiple time steps. We evaluate the approach using simulated random walk trajectories for seven drones, correlating target aspect angles to Radar Cross Section (RCS) measurements in an anechoic chamber. Comparing against single radar Automated Target Recognition (ATR) systems and suboptimal fusion methods, our empirical results demonstrate that the OBF method integrated with RBC significantly enhances classification accuracy compared to other fusion methods and single radar configurations.
Learning Semilinear Neural Operators : A Unified Recursive Framework For Prediction And Data Assimilation
Feb 24, 2024
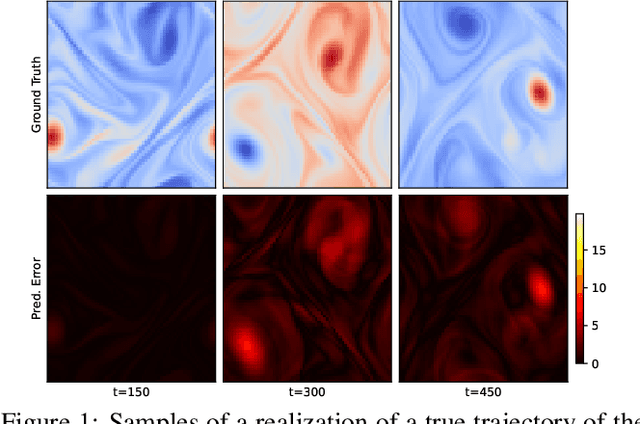
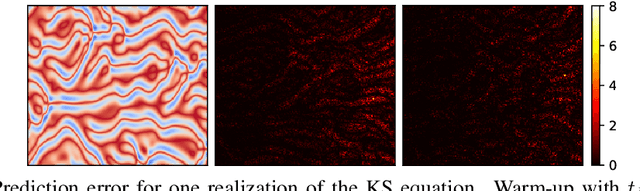
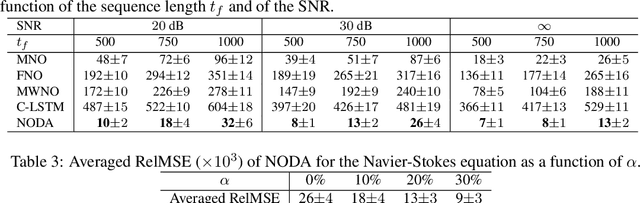
Recent advances in the theory of Neural Operators (NOs) have enabled fast and accurate computation of the solutions to complex systems described by partial differential equations (PDEs). Despite their great success, current NO-based solutions face important challenges when dealing with spatio-temporal PDEs over long time scales. Specifically, the current theory of NOs does not present a systematic framework to perform data assimilation and efficiently correct the evolution of PDE solutions over time based on sparsely sampled noisy measurements. In this paper, we propose a learning-based state-space approach to compute the solution operators to infinite-dimensional semilinear PDEs. Exploiting the structure of semilinear PDEs and the theory of nonlinear observers in function spaces, we develop a flexible recursive method that allows for both prediction and data assimilation by combining prediction and correction operations. The proposed framework is capable of producing fast and accurate predictions over long time horizons, dealing with irregularly sampled noisy measurements to correct the solution, and benefits from the decoupling between the spatial and temporal dynamics of this class of PDEs. We show through experiments on the Kuramoto-Sivashinsky, Navier-Stokes and Korteweg-de Vries equations that the proposed model is robust to noise and can leverage arbitrary amounts of measurements to correct its prediction over a long time horizon with little computational overhead.
Tubular Curvature Filter: Implicit Pointwise Curvature Calculation Method for Tubular Objects
Nov 20, 2023



Curvature estimation methods are important as they capture salient features for various applications in image processing, especially within medical domains where tortuosity of vascular structures is of significant interest. Existing methods based on centerline or skeleton curvature fail to capture curvature gradients across a rotating tubular structure. This paper presents a Tubular Curvature Filter method that locally calculates the acceleration of bundles of curves that traverse along the tubular object parallel to the centerline. This is achieved by examining the directional rate of change in the eigenvectors of the Hessian matrix of a tubular intensity function in space. This method implicitly calculates the local tubular curvature without the need to explicitly segment the tubular object. Experimental results demonstrate that the Tubular Curvature Filter method provides accurate estimates of local curvature at any point inside tubular structures.