 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explicit Surrogate for Gaussian Mixture Flow Matching with Wasserstein Gap Bounds
Mar 30, 2026We study training-free flow matching between two Gaussian mixture models (GMMs) using explicit velocity fields that transport one mixture into the other over time. Our baseline approach constructs component-wise Gaussian paths with affine velocity fields satisfying the continuity equation, which yields to a closed-form surrogate for the pairwise kinetic transport cost. In contrast to the exact Gaussian Wasserstein cost, which relies on matrix square-root computations, the surrogate admits a simple analytic expression derived from the kinetic energy of the induced flow. We then analyze how closely this surrogate approximates the exact cost. We prove second-order agreement in a local commuting regime and derive an explicit cubic error bound in the local commuting regime. To handle nonlocal regimes, we introduce a path-splitting strategy that localizes the covariance evolution and enables piecewise application of the bound. We finally compare the surrogate with an exact construction based on the Gaussian Wasserstein geodesic and summarize the results in a practical regime map showing when the surrogate is accurate and the exact method is preferable.
Holonorm
Nov 13, 2025Normalization is a key point in transformer training . In Dynamic Tanh (DyT), the author demonstrated that Tanh can be used as an alternative layer normalization (LN) and confirmed the effectiveness of the idea. But Tanh itself faces orthogonality, linearity and distortion problems. Due to that, his proposition cannot be reliable. So we propose a Holonorm (hn) which has residual connections and nonlinearity. Holonorm is suitable for replacing Tanh in the context of normalization. Although the HoloNorm expression could be similar to the softsign function in dimension one, softsign is a componentwise function which is not good for tensors and vectors of great dimension. Holonorm preserves the orthogonality, the direction, the invertibility of the signal. Holonorm is also a suitable metric, maps all vectors into the open unit ball. This prevents exploding activations and improves stability in deep Transformer models. In this work, we have meticulously examined the normalization in transformers and say that Holonorm, a generalized form of softsign function suited as a normalization function first.Second, defined between 0 and 1 hn serves as a percentage, and $1 - \text{Holonorm}$ is its complement, making it better understandable in evaluating a model.
Machine Intelligence in Africa: a survey
Feb 03, 2024In the last 5 years, the availability of large audio datasets in African countries has opened unlimited opportunities to build machine intelligence (MI) technologies that are closer to the people and speak, learn, understand, and do businesses in local languages, including for those who cannot read and write. Unfortunately, these audio datasets are not fully exploited by current MI tools, leaving several Africans out of MI business opportunities. Additionally, many state-of-the-art MI models are not culture-aware, and the ethics of their adoption indexes are questionable. The lack thereof is a major drawback in many applications in Africa. This paper summarizes recent developments in machine intelligence in Africa from a multi-layer multiscale and culture-aware ethics perspective, showcasing MI use cases in 54 African countries through 400 articles on MI research, industry, government actions, as well as uses in art, music, the informal economy, and small businesses in Africa. The survey also opens discussions on the reliability of MI rankings and indexes in the African continent as well as algorithmic definitions of unclear terms used in MI.
Nonparallel Emotional Speech Conversion
Nov 03, 2018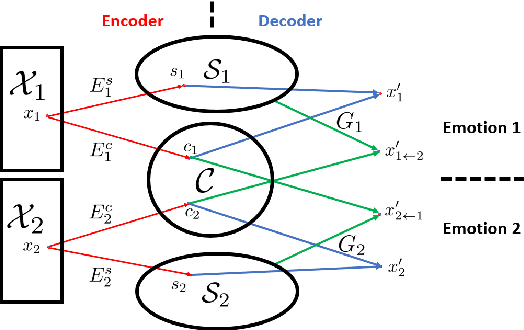
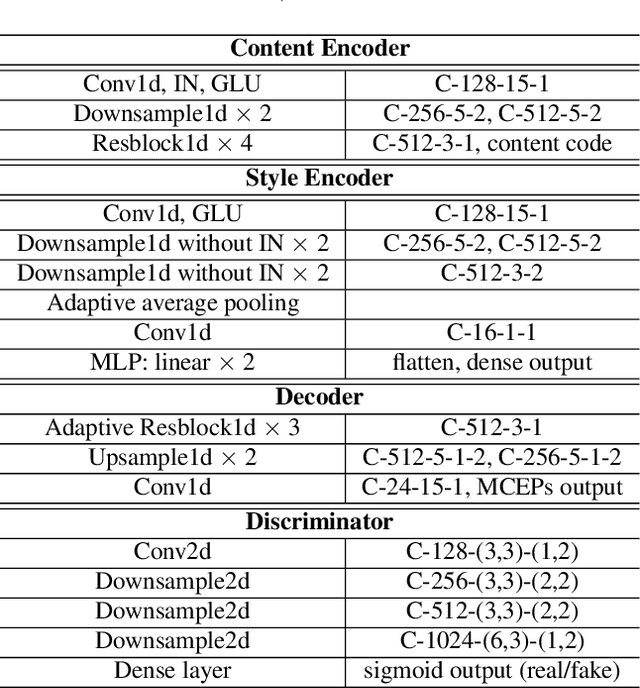
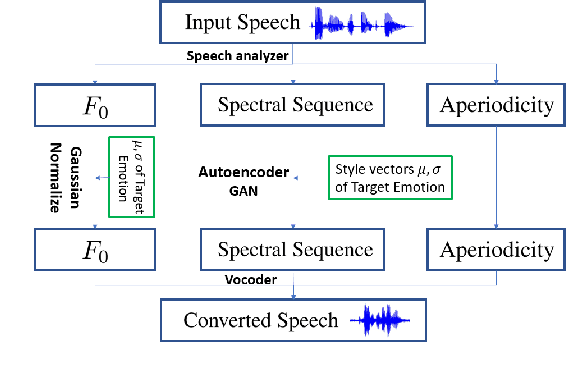
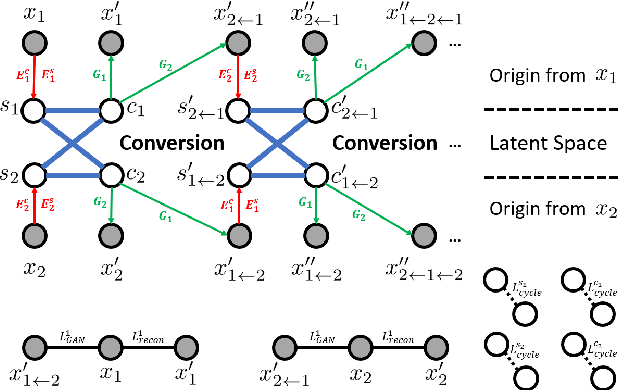
We propose a nonparallel data-driven emotional speech conversion method. It enables the transfer of emotion-related characteristics of a speech signal while preserving the speaker's identity and linguistic content. Most existing approaches require parallel data and time alignment, which is not available in most real applications. We achieve nonparallel training based on an unsupervised style transfer technique, which learns a translation model between two distributions instead of a deterministic one-to-one mapping between paired examples. The conversion model consists of an encoder and a decoder for each emotion domain. We assume that the speech signal can be decomposed into an emotion-invariant content code and an emotion-related style code in latent space. Emotion conversion is performed by extracting and recombining the content code of the source speech and the style code of the target emotion. We tested our method on a nonparallel corpora with four emotions. Both subjective and objective evaluations show the effectiveness of our approach.
Empathy in Bimatrix Games
Aug 06, 2017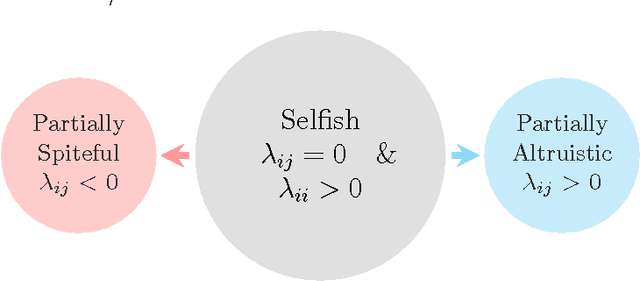
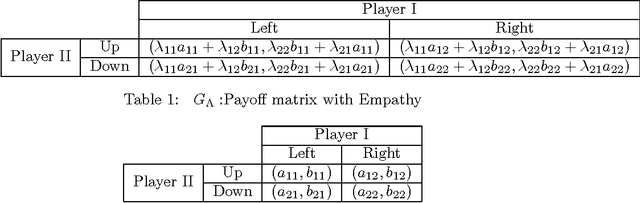
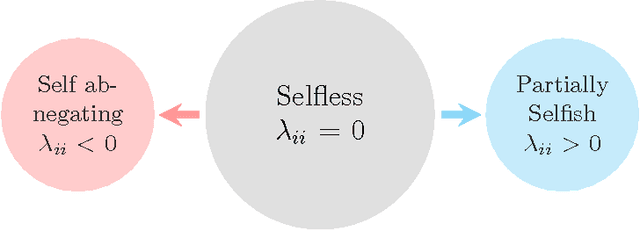

Although the definition of what empathetic preferences exactly are is still evolving, there is a general consensus in the psychology, science and engineering communities that the evolution toward players' behaviors in interactive decision-making problems will be accompanied by the exploitation of their empathy, sympathy, compassion, antipathy, spitefulness, selfishness, altruism, and self-abnegating states in the payoffs. In this article, we study one-shot bimatrix games from a psychological game theory viewpoint. A new empathetic payoff model is calculated to fit empirical observations and both pure and mixed equilibria are investigated. For a realized empathy structure, the bimatrix game is categorized among four generic class of games. Number of interesting results are derived. A notable level of involvement can be observed in the empathetic one-shot game compared the non-empathetic one and this holds even for games with dominated strategies. Partial altruism can help in breaking symmetry, in reducing payoff-inequality and in selecting social welfare and more efficient outcomes. By contrast, partial spite and self-abnegating may worsen payoff equity. Empathetic evolutionary game dynamics are introduced to capture the resulting empathetic evolutionarily stable strategies under wide range of revision protocols including Brown-von Neumann-Nash, Smith, imitation, replicator, and hybrid dynamics. Finally, mutual support and Berge solution are investigated and their connection with empathetic preferences are established. We show that pure altruism is logically inconsistent, only by balancing it with some partial selfishness does it create a consistent psychology.
Mean-Field Learning: a Survey
Oct 17, 2012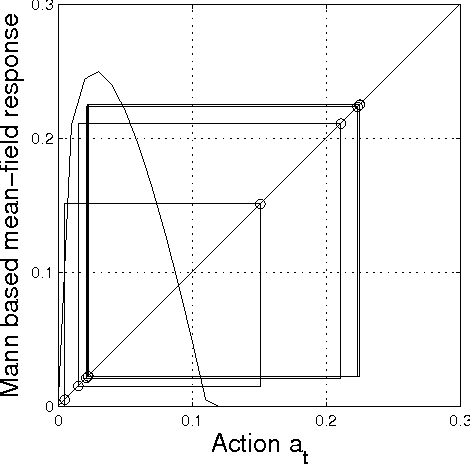
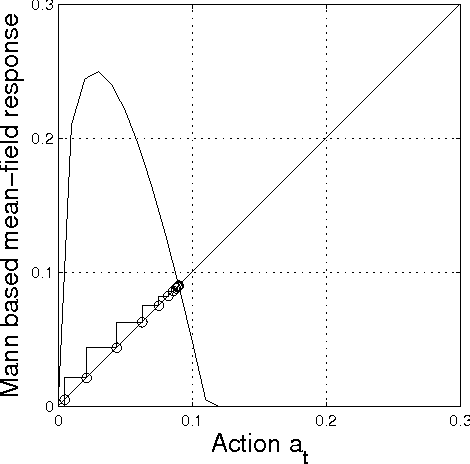
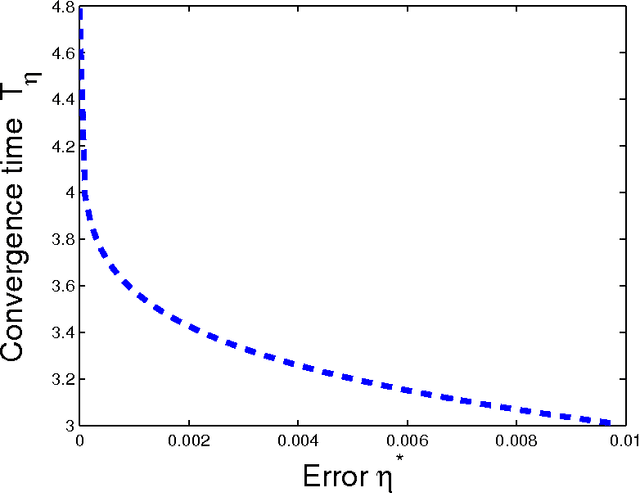

In this paper we study iterative procedures for stationary equilibria in games with large number of players. Most of learning algorithms for games with continuous action spaces are limited to strict contraction best reply maps in which the Banach-Picard iteration converges with geometrical convergence rate. When the best reply map is not a contraction, Ishikawa-based learning is proposed. The algorithm is shown to behave well for Lipschitz continuous and pseudo-contractive maps. However, the convergence rate is still unsatisfactory. Several acceleration techniques are presented. We explain how cognitive users can improve the convergence rate based only on few number of measurements. The methodology provides nice properties in mean field games where the payoff function depends only on own-action and the mean of the mean-field (first moment mean-field games). A learning framework that exploits the structure of such games, called, mean-field learning, is proposed. The proposed mean-field learning framework is suitable not only for games but also for non-convex global optimization problems. Then, we introduce mean-field learning without feedback and examine the convergence to equilibria in beauty contest games, which have interesting applications in financial markets. Finally, we provide a fully distributed mean-field learning and its speedup versions for satisfactory solution in wireless networks. We illustrate the convergence rate improvement with numerical examples.
Heterogeneous Learning in Zero-Sum Stochastic Games with Incomplete Information
Mar 13, 2011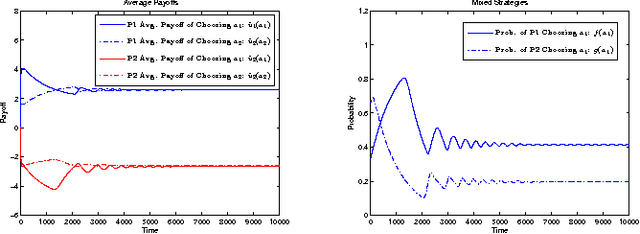
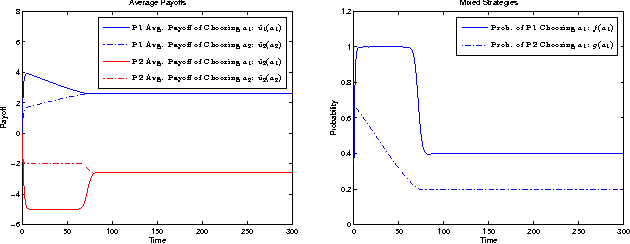
Learning algorithms are essential for the applications of game theory in a networking environment. In dynamic and decentralized settings where the traffic, topology and channel states may vary over time and the communication between agents is impractical, it is important to formulate and study games of incomplete information and fully distributed learning algorithms which for each agent requires a minimal amount of information regarding the remaining agents. In this paper, we address this major challenge and introduce heterogeneous learning schemes in which each agent adopts a distinct learning pattern in the context of games with incomplete information. We use stochastic approximation techniques to show that the heterogeneous learning schemes can be studied in terms of their deterministic ordinary differential equation (ODE) counterparts. Depending on the learning rates of the players, these ODEs could be different from the standard replicator dynamics, (myopic) best response (BR) dynamics, logit dynamics, and fictitious play dynamics. We apply the results to a class of security games in which the attacker and the defender adopt different learning schemes due to differences in their rationality levels and the information they acquire.