 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpathy in Bimatrix Games
Aug 06, 2017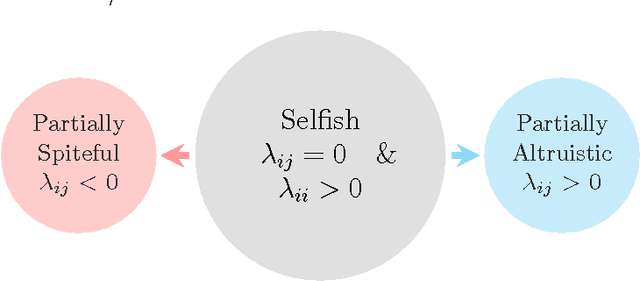
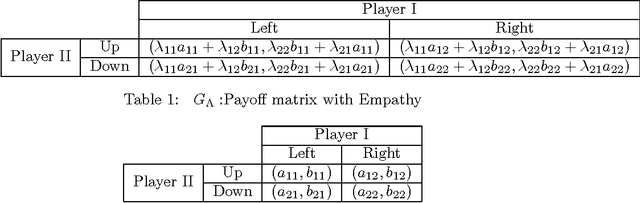
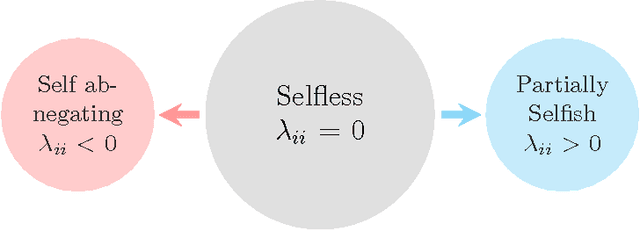

Although the definition of what empathetic preferences exactly are is still evolving, there is a general consensus in the psychology, science and engineering communities that the evolution toward players' behaviors in interactive decision-making problems will be accompanied by the exploitation of their empathy, sympathy, compassion, antipathy, spitefulness, selfishness, altruism, and self-abnegating states in the payoffs. In this article, we study one-shot bimatrix games from a psychological game theory viewpoint. A new empathetic payoff model is calculated to fit empirical observations and both pure and mixed equilibria are investigated. For a realized empathy structure, the bimatrix game is categorized among four generic class of games. Number of interesting results are derived. A notable level of involvement can be observed in the empathetic one-shot game compared the non-empathetic one and this holds even for games with dominated strategies. Partial altruism can help in breaking symmetry, in reducing payoff-inequality and in selecting social welfare and more efficient outcomes. By contrast, partial spite and self-abnegating may worsen payoff equity. Empathetic evolutionary game dynamics are introduced to capture the resulting empathetic evolutionarily stable strategies under wide range of revision protocols including Brown-von Neumann-Nash, Smith, imitation, replicator, and hybrid dynamics. Finally, mutual support and Berge solution are investigated and their connection with empathetic preferences are established. We show that pure altruism is logically inconsistent, only by balancing it with some partial selfishness does it create a consistent psychology.
Collision Avoidance of Two Autonomous Quadcopters
Mar 17, 2016


Traffic collision avoidance systems (TCAS) are used in order to avoid incidences of mid-air collisions between aircraft. We present a game-theoretic approach of a TCAS designed for autonomous unmanned aerial vehicles (UAVs). A variant of the canonical example of game-theoretic learning, fictitious play, is used as a coordination mechanism between the UAVs, that should choose between the alternative altitudes to fly and avoid collision. We present the implementation results of the proposed coordination mechanism in two quad-copters flying in opposite directions.
Multi-agent learning using Fictitious Play and Extended Kalman Filter
Jan 15, 2013



Decentralised optimisation tasks are important components of multi-agent systems. These tasks can be interpreted as n-player potential games: therefore game-theoretic learning algorithms can be used to solve decentralised optimisation tasks. Fictitious play is the canonical example of these algorithms. Nevertheless fictitious play implicitly assumes that players have stationary strategies. We present a novel variant of fictitious play where players predict their opponents' strategies using Extended Kalman filters and use their predictions to update their strategies. We show that in 2 by 2 games with at least one pure Nash equilibrium and in potential games where players have two available actions, the proposed algorithm converges to the pure Nash equilibrium. The performance of the proposed algorithm was empirically tested, in two strategic form games and an ad-hoc sensor network surveillance problem. The proposed algorithm performs better than the classic fictitious play algorithm in these games and therefore improves the performance of game-theoretical learning in decentralised optimisation.
Adaptive Forgetting Factor Fictitious Play
Dec 11, 2011



It is now well known that decentralised optimisation can be formulated as a potential game, and game-theoretical learning algorithms can be used to find an optimum. One of the most common learning techniques in game theory is fictitious play. However fictitious play is founded on an implicit assumption that opponents' strategies are stationary. We present a novel variation of fictitious play that allows the use of a more realistic model of opponent strategy. It uses a heuristic approach, from the online streaming data literature, to adaptively update the weights assigned to recently observed actions. We compare the results of the proposed algorithm with those of stochastic and geometric fictitious play in a simple strategic form game, a vehicle target assignment game and a disaster management problem. In all the tests the rate of convergence of the proposed algorithm was similar or better than the variations of fictitious play we compared it with. The new algorithm therefore improves the performance of game-theoretical learning in decentralised optimisation.