 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated $\mathcal{X}$-armed Bandit with Flexible Personalisation
Sep 11, 2024This paper introduces a novel approach to personalised federated learning within the $\mathcal{X}$-armed bandit framework, addressing the challenge of optimising both local and global objectives in a highly heterogeneous environment. Our method employs a surrogate objective function that combines individual client preferences with aggregated global knowledge, allowing for a flexible trade-off between personalisation and collective learning. We propose a phase-based elimination algorithm that achieves sublinear regret with logarithmic communication overhead, making it well-suited for federated settings. Theoretical analysis and empirical evaluations demonstrate the effectiveness of our approach compared to existing methods. Potential applications of this work span various domains, including healthcare, smart home devices, and e-commerce, where balancing personalisation with global insights is crucial.
FINN.no Slates Dataset: A new Sequential Dataset Logging Interactions, allViewed Items and Click Responses/No-Click for Recommender Systems Research
Nov 05, 2021

We present a novel recommender systems dataset that records the sequential interactions between users and an online marketplace. The users are sequentially presented with both recommendations and search results in the form of ranked lists of items, called slates, from the marketplace. The dataset includes the presented slates at each round, whether the user clicked on any of these items and which item the user clicked on. Although the usage of exposure data in recommender systems is growing, to our knowledge there is no open large-scale recommender systems dataset that includes the slates of items presented to the users at each interaction. As a result, most articles on recommender systems do not utilize this exposure information. Instead, the proposed models only depend on the user's click responses, and assume that the user is exposed to all the items in the item universe at each step, often called uniform candidate sampling. This is an incomplete assumption, as it takes into account items the user might not have been exposed to. This way items might be incorrectly considered as not of interest to the user. Taking into account the actually shown slates allows the models to use a more natural likelihood, based on the click probability given the exposure set of items, as is prevalent in the bandit and reinforcement learning literature. \cite{Eide2021DynamicSampling} shows that likelihoods based on uniform candidate sampling (and similar assumptions) are implicitly assuming that the platform only shows the most relevant items to the user. This causes the recommender system to implicitly reinforce feedback loops and to be biased towards previously exposed items to the user.
Apple Tasting Revisited: Bayesian Approaches to Partially Monitored Online Binary Classification
Sep 29, 2021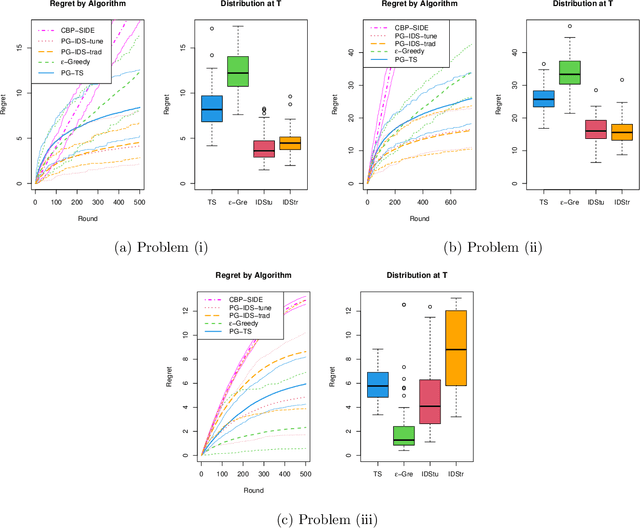
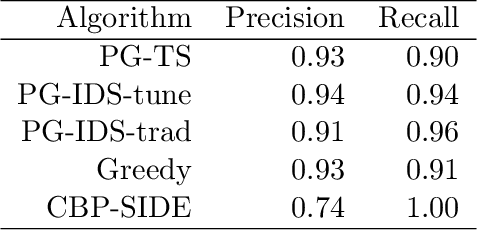
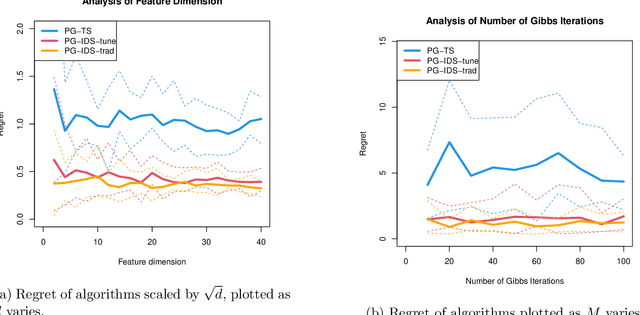
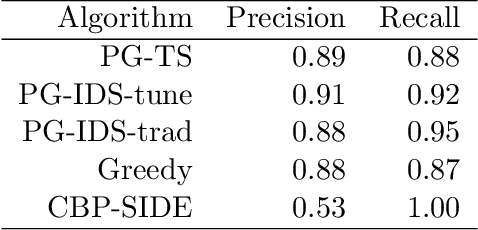
We consider a variant of online binary classification where a learner sequentially assigns labels ($0$ or $1$) to items with unknown true class. If, but only if, the learner chooses label $1$ they immediately observe the true label of the item. The learner faces a trade-off between short-term classification accuracy and long-term information gain. This problem has previously been studied under the name of the `apple tasting' problem. We revisit this problem as a partial monitoring problem with side information, and focus on the case where item features are linked to true classes via a logistic regression model. Our principal contribution is a study of the performance of Thompson Sampling (TS) for this problem. Using recently developed information-theoretic tools, we show that TS achieves a Bayesian regret bound of an improved order to previous approaches. Further, we experimentally verify that efficient approximations to TS and Information Directed Sampling via P\'{o}lya-Gamma augmentation have superior empirical performance to existing methods.
Decentralized Q-Learning in Zero-sum Markov Games
Jun 04, 2021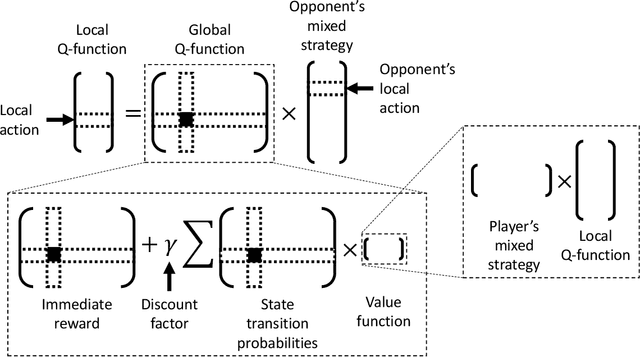
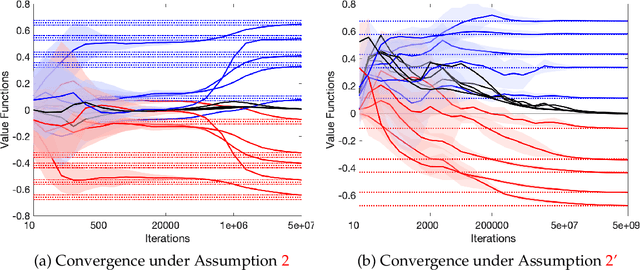
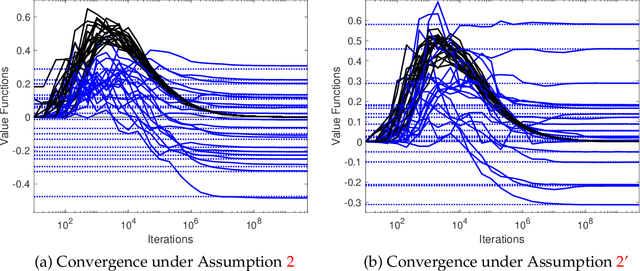
We study multi-agent reinforcement learning (MARL) in infinite-horizon discounted zero-sum Markov games. We focus on the practical but challenging setting of decentralized MARL, where agents make decisions without coordination by a centralized controller, but only based on their own payoffs and local actions executed. The agents need not observe the opponent's actions or payoffs, possibly being even oblivious to the presence of the opponent, nor be aware of the zero-sum structure of the underlying game, a setting also referred to as radically uncoupled in the literature of learning in games. In this paper, we develop for the first time a radically uncoupled Q-learning dynamics that is both rational and convergent: the learning dynamics converges to the best response to the opponent's strategy when the opponent follows an asymptotically stationary strategy; the value function estimates converge to the payoffs at a Nash equilibrium when both agents adopt the dynamics. The key challenge in this decentralized setting is the non-stationarity of the learning environment from an agent's perspective, since both her own payoffs and the system evolution depend on the actions of other agents, and each agent adapts their policies simultaneously and independently. To address this issue, we develop a two-timescale learning dynamics where each agent updates her local Q-function and value function estimates concurrently, with the latter happening at a slower timescale.
Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling
Apr 30, 2021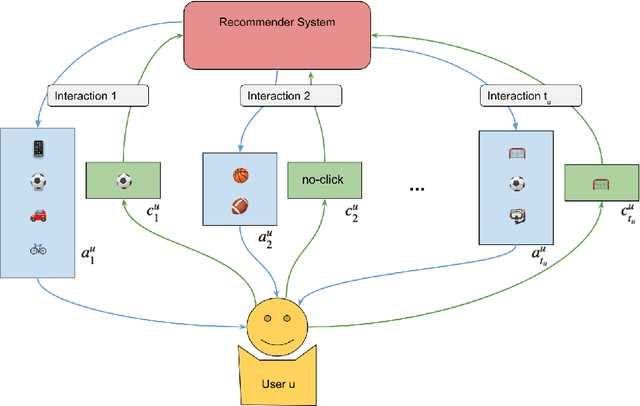

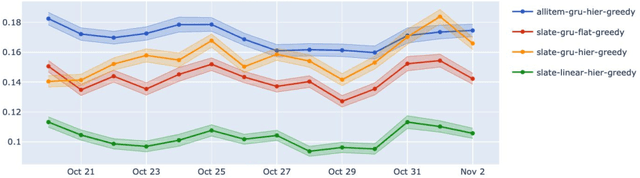

We consider the problem of recommending relevant content to users of an internet platform in the form of lists of items, called slates. We introduce a variational Bayesian Recurrent Neural Net recommender system that acts on time series of interactions between the internet platform and the user, and which scales to real world industrial situations. The recommender system is tested both online on real users, and on an offline dataset collected from a Norwegian web-based marketplace, FINN.no, that is made public for research. This is one of the first publicly available datasets which includes all the slates that are presented to users as well as which items (if any) in the slates were clicked on. Such a data set allows us to move beyond the common assumption that implicitly assumes that users are considering all possible items at each interaction. Instead we build our likelihood using the items that are actually in the slate, and evaluate the strengths and weaknesses of both approaches theoretically and in experiments. We also introduce a hierarchical prior for the item parameters based on group memberships. Both item parameters and user preferences are learned probabilistically. Furthermore, we combine our model with bandit strategies to ensure learning, and introduce `in-slate Thompson Sampling' which makes use of the slates to maximise explorative opportunities. We show experimentally that explorative recommender strategies perform on par or above their greedy counterparts. Even without making use of exploration to learn more effectively, click rates increase simply because of improved diversity in the recommended slates.
GIBBON: General-purpose Information-Based Bayesian OptimisatioN
Feb 05, 2021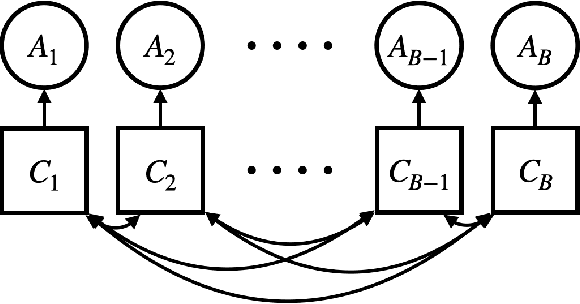

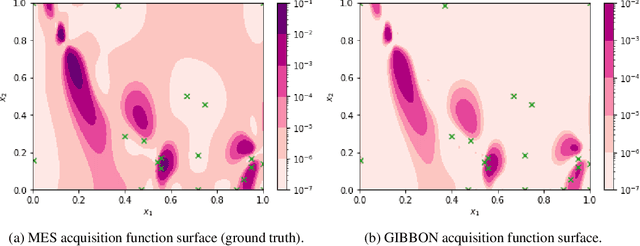
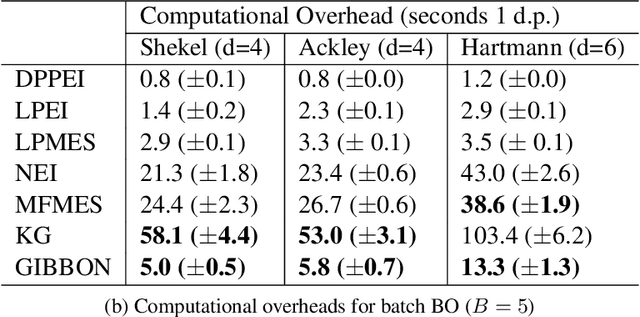
This paper describes a general-purpose extension of max-value entropy search, a popular approach for Bayesian Optimisation (BO). A novel approximation is proposed for the information gain -- an information-theoretic quantity central to solving a range of BO problems, including noisy, multi-fidelity and batch optimisations across both continuous and highly-structured discrete spaces. Previously, these problems have been tackled separately within information-theoretic BO, each requiring a different sophisticated approximation scheme, except for batch BO, for which no computationally-lightweight information-theoretic approach has previously been proposed. GIBBON (General-purpose Information-Based Bayesian OptimisatioN) provides a single principled framework suitable for all the above, out-performing existing approaches whilst incurring substantially lower computational overheads. In addition, GIBBON does not require the problem's search space to be Euclidean and so is the first high-performance yet computationally light-weight acquisition function that supports batch BO over general highly structured input spaces like molecular search and gene design. Moreover, our principled derivation of GIBBON yields a natural interpretation of a popular batch BO heuristic based on determinantal point processes. Finally, we analyse GIBBON across a suite of synthetic benchmark tasks, a molecular search loop, and as part of a challenging batch multi-fidelity framework for problems with controllable experimental noise.
BOSS: Bayesian Optimization over String Spaces
Oct 02, 2020
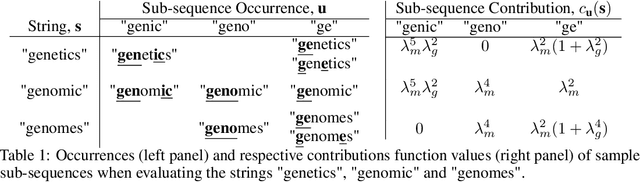
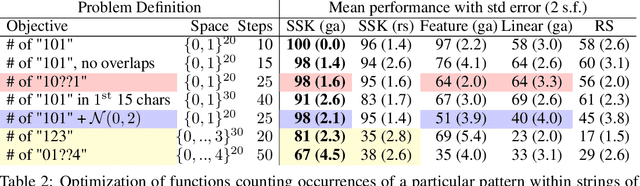
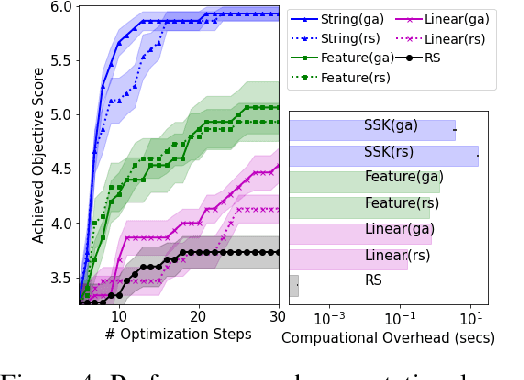
This article develops a Bayesian optimization (BO) method which acts directly over raw strings, proposing the first uses of string kernels and genetic algorithms within BO loops. Recent applications of BO over strings have been hindered by the need to map inputs into a smooth and unconstrained latent space. Learning this projection is computationally and data-intensive. Our approach instead builds a powerful Gaussian process surrogate model based on string kernels, naturally supporting variable length inputs, and performs efficient acquisition function maximization for spaces with syntactical constraints. Experiments demonstrate considerably improved optimization over existing approaches across a broad range of constraints, including the popular setting where syntax is governed by a context-free grammar.
Learning to Rank under Multinomial Logit Choice
Sep 07, 2020
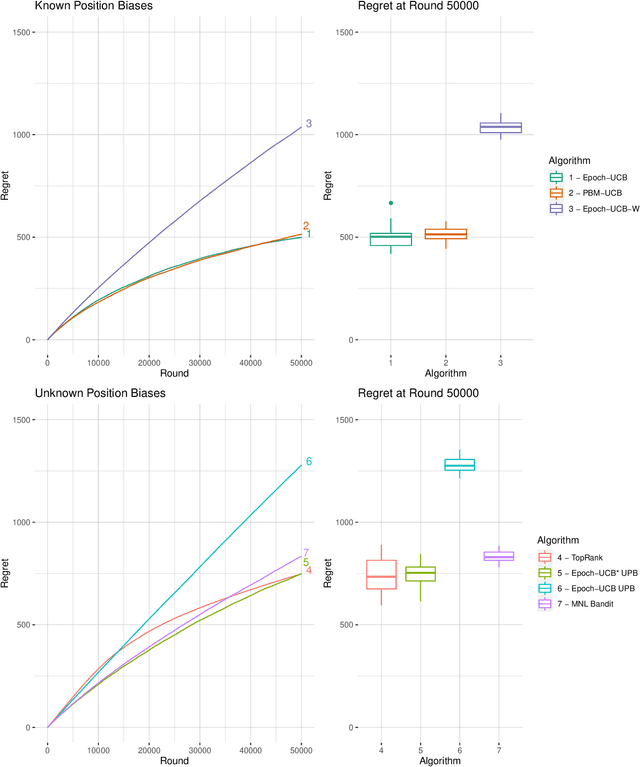
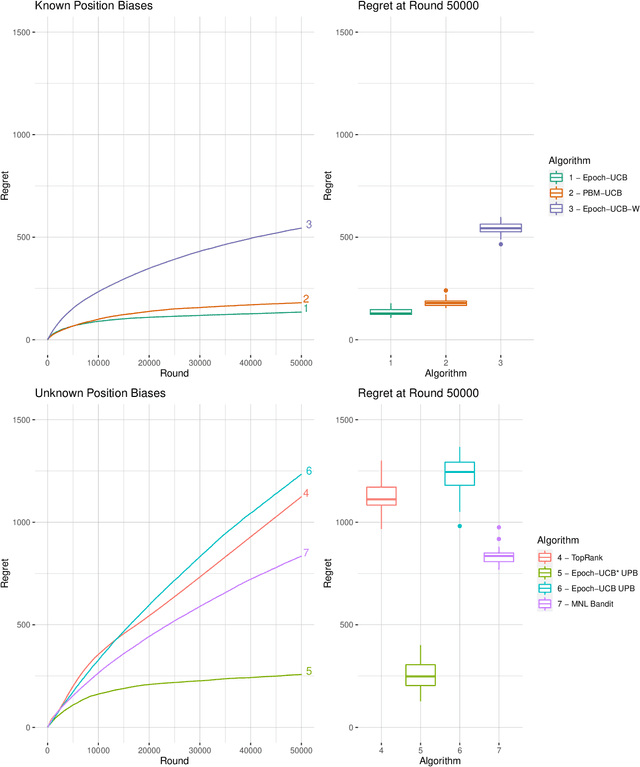
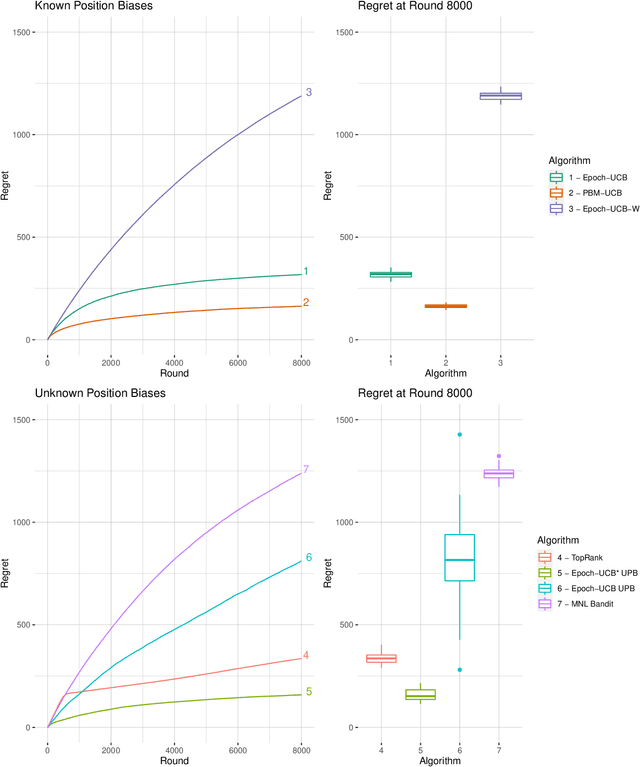
Learning the optimal ordering of content is an important challenge in website design. The learning to rank (LTR) framework models this problem as a sequential problem of selecting lists of content and observing where users decide to click. Most previous work on LTR assumes that the user considers each item in the list in isolation, and makes binary choices to click or not on each. We introduce a multinomial logit (MNL) choice model to the LTR framework, which captures the behaviour of users who consider the ordered list of items as a whole and make a single choice among all the items and a no-click option. Under the MNL model, the user favours items which are either inherently more attractive, or placed in a preferable position within the list. We propose upper confidence bound algorithms to minimise regret in two settings - where the position dependent parameters are known, and unknown. We present theoretical analysis leading to an $\Omega(\sqrt{T})$ lower bound for the problem, an $\tilde{O}(\sqrt{T})$ upper bound on regret for the known parameter version. Our analyses are based on tight new concentration results for Geometric random variables, and novel functional inequalities for maximum likelihood estimators computed on discrete data.
BOSH: Bayesian Optimization by Sampling Hierarchically
Jul 02, 2020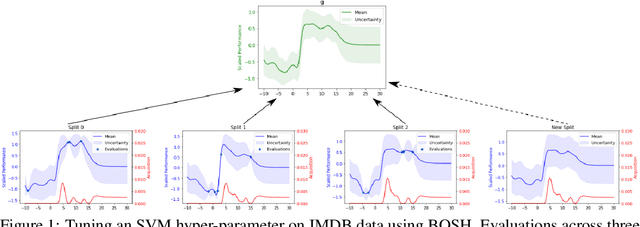
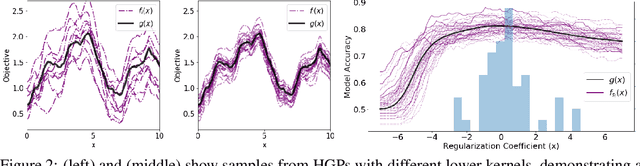
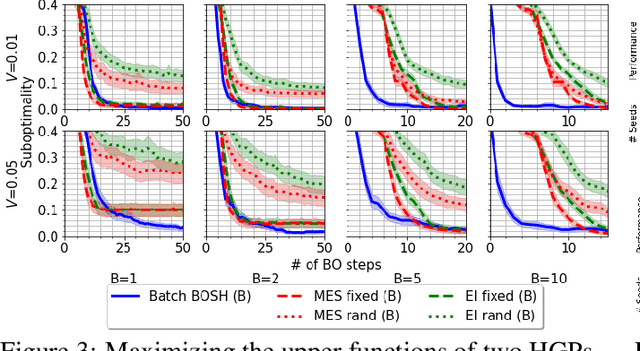
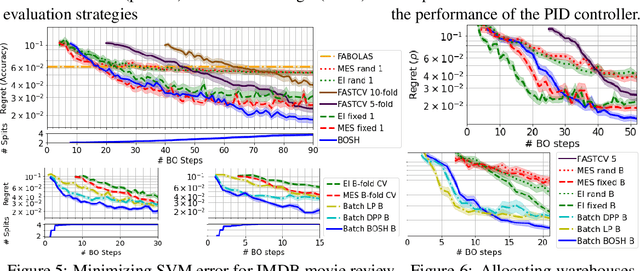
Deployments of Bayesian Optimization (BO) for functions with stochastic evaluations, such as parameter tuning via cross validation and simulation optimization, typically optimize an average of a fixed set of noisy realizations of the objective function. However, disregarding the true objective function in this manner finds a high-precision optimum of the wrong function. To solve this problem, we propose Bayesian Optimization by Sampling Hierarchically (BOSH), a novel BO routine pairing a hierarchical Gaussian process with an information-theoretic framework to generate a growing pool of realizations as the optimization progresses. We demonstrate that BOSH provides more efficient and higher-precision optimization than standard BO across synthetic benchmarks, simulation optimization, reinforcement learning and hyper-parameter tuning tasks.
MUMBO: MUlti-task Max-value Bayesian Optimization
Jun 22, 2020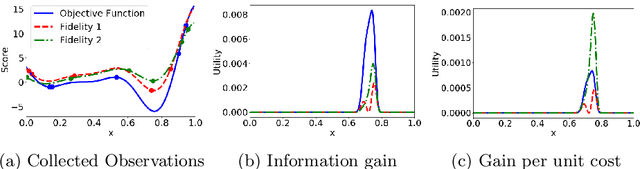
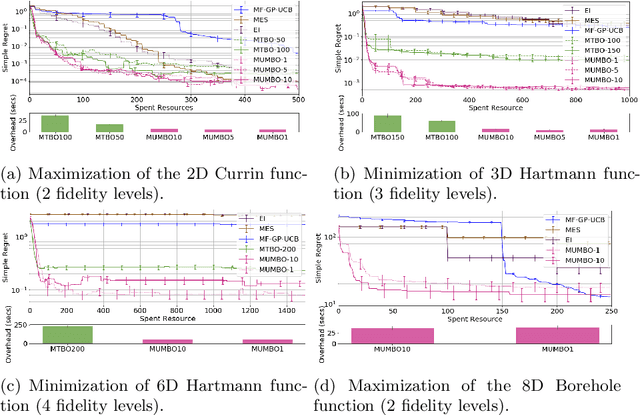
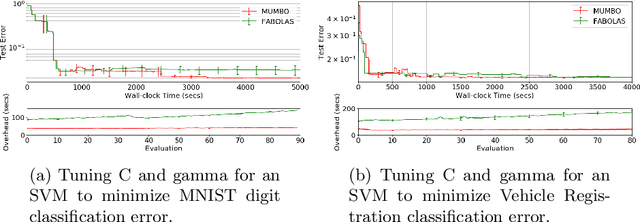
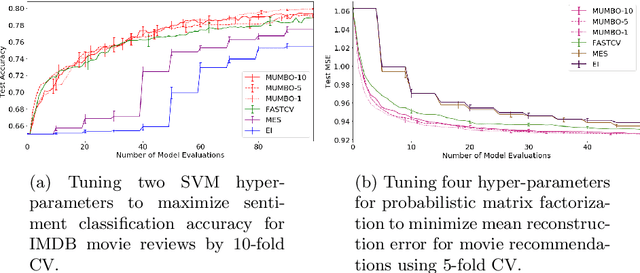
We propose MUMBO, the first high-performing yet computationally efficient acquisition function for multi-task Bayesian optimization. Here, the challenge is to perform efficient optimization by evaluating low-cost functions somehow related to our true target function. This is a broad class of problems including the popular task of multi-fidelity optimization. However, while information-theoretic acquisition functions are known to provide state-of-the-art Bayesian optimization, existing implementations for multi-task scenarios have prohibitive computational requirements. Previous acquisition functions have therefore been suitable only for problems with both low-dimensional parameter spaces and function query costs sufficiently large to overshadow very significant optimization overheads. In this work, we derive a novel multi-task version of entropy search, delivering robust performance with low computational overheads across classic optimization challenges and multi-task hyper-parameter tuning. MUMBO is scalable and efficient, allowing multi-task Bayesian optimization to be deployed in problems with rich parameter and fidelity spaces.