 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLEBench+NorGLM: A Comprehensive Empirical Analysis and Benchmark Dataset for Generative Language Models in Norwegian
Dec 03, 2023



Recent advancements in Generative Language Models (GLMs) have transformed Natural Language Processing (NLP) by showcasing the effectiveness of the "pre-train, prompt, and predict" paradigm in utilizing pre-trained GLM knowledge for diverse applications. Despite their potential, these capabilities lack adequate quantitative characterization due to the absence of comprehensive benchmarks, particularly for low-resource languages. Existing low-resource benchmarks focus on discriminative language models like BERT, neglecting the evaluation of generative language models. Moreover, current benchmarks often overlook measuring generalization performance across multiple tasks, a crucial metric for GLMs. To bridge these gaps, we introduce NLEBench, a comprehensive benchmark tailored for evaluating natural language generation capabilities in Norwegian, a low-resource language. We use Norwegian as a case study to explore whether current GLMs and benchmarks in mainstream languages like English can reveal the unique characteristics of underrepresented languages. NLEBench encompasses a suite of real-world NLP tasks ranging from news storytelling, summarization, open-domain conversation, natural language understanding, instruction fine-tuning, toxicity and bias evaluation, to self-curated Chain-of-Thought investigation. It features two high-quality, human-annotated datasets: an instruction dataset covering traditional Norwegian cultures, idioms, slang, and special expressions, and a document-grounded multi-label dataset for topic classification, question answering, and summarization. This paper also introduces foundational Norwegian Generative Language Models (NorGLMs) developed with diverse parameter scales and Transformer-based architectures. Systematic evaluations on the proposed benchmark suite provide insights into the capabilities and scalability of NorGLMs across various downstream tasks.
FINN.no Slates Dataset: A new Sequential Dataset Logging Interactions, allViewed Items and Click Responses/No-Click for Recommender Systems Research
Nov 05, 2021

We present a novel recommender systems dataset that records the sequential interactions between users and an online marketplace. The users are sequentially presented with both recommendations and search results in the form of ranked lists of items, called slates, from the marketplace. The dataset includes the presented slates at each round, whether the user clicked on any of these items and which item the user clicked on. Although the usage of exposure data in recommender systems is growing, to our knowledge there is no open large-scale recommender systems dataset that includes the slates of items presented to the users at each interaction. As a result, most articles on recommender systems do not utilize this exposure information. Instead, the proposed models only depend on the user's click responses, and assume that the user is exposed to all the items in the item universe at each step, often called uniform candidate sampling. This is an incomplete assumption, as it takes into account items the user might not have been exposed to. This way items might be incorrectly considered as not of interest to the user. Taking into account the actually shown slates allows the models to use a more natural likelihood, based on the click probability given the exposure set of items, as is prevalent in the bandit and reinforcement learning literature. \cite{Eide2021DynamicSampling} shows that likelihoods based on uniform candidate sampling (and similar assumptions) are implicitly assuming that the platform only shows the most relevant items to the user. This causes the recommender system to implicitly reinforce feedback loops and to be biased towards previously exposed items to the user.
Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling
Apr 30, 2021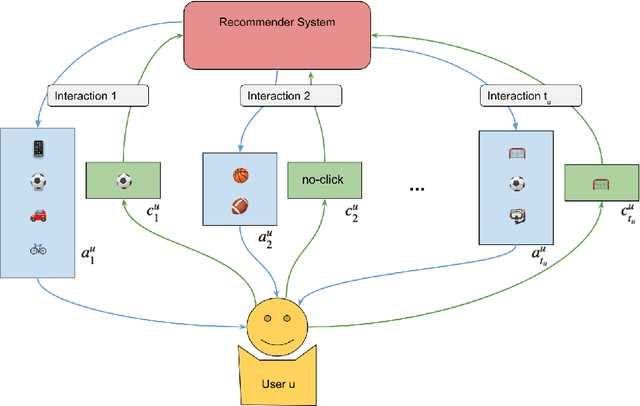

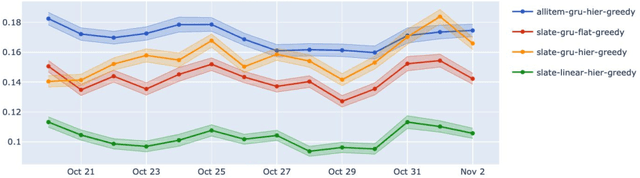

We consider the problem of recommending relevant content to users of an internet platform in the form of lists of items, called slates. We introduce a variational Bayesian Recurrent Neural Net recommender system that acts on time series of interactions between the internet platform and the user, and which scales to real world industrial situations. The recommender system is tested both online on real users, and on an offline dataset collected from a Norwegian web-based marketplace, FINN.no, that is made public for research. This is one of the first publicly available datasets which includes all the slates that are presented to users as well as which items (if any) in the slates were clicked on. Such a data set allows us to move beyond the common assumption that implicitly assumes that users are considering all possible items at each interaction. Instead we build our likelihood using the items that are actually in the slate, and evaluate the strengths and weaknesses of both approaches theoretically and in experiments. We also introduce a hierarchical prior for the item parameters based on group memberships. Both item parameters and user preferences are learned probabilistically. Furthermore, we combine our model with bandit strategies to ensure learning, and introduce `in-slate Thompson Sampling' which makes use of the slates to maximise explorative opportunities. We show experimentally that explorative recommender strategies perform on par or above their greedy counterparts. Even without making use of exploration to learn more effectively, click rates increase simply because of improved diversity in the recommended slates.
Five lessons from building a deep neural network recommender
Oct 07, 2018
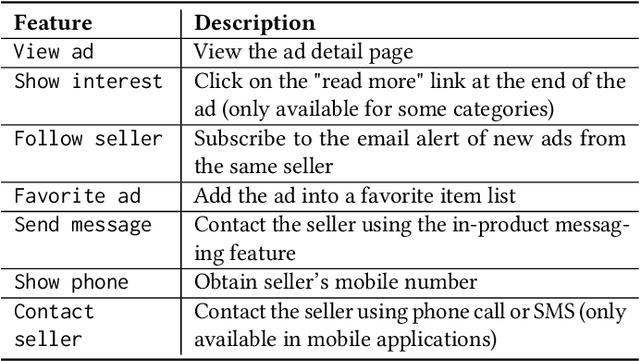


Recommendation algorithms are widely adopted in marketplaces to help users find the items they are looking for. The sparsity of the items by user matrix and the cold-start issue in marketplaces pose challenges for the off-the-shelf matrix factorization based recommender systems. To understand user intent and tailor recommendations to their needs, we use deep learning to explore various heterogeneous data available in marketplaces. This paper summarizes five lessons we learned from experimenting with state-of-the-art deep learning recommenders at the leading Norwegian marketplace FINN.no. We design a hybrid recommender system that takes the user-generated contents of a marketplace (including text, images and meta attributes) and combines them with user behavior data such as page views and messages to provide recommendations for marketplace items. Among various tactics we experimented with, the following five show the best impact: staged training instead of end-to-end training, leveraging rich user behaviors beyond page views, using user behaviors as noisy labels to train embeddings, using transfer learning to solve the unbalanced data problem, and using attention mechanisms in the hybrid model. This system is currently running with around 20% click-through-rate in production at FINN.no and serves over one million visitors everyday.
Deep neural network marketplace recommenders in online experiments
Sep 06, 2018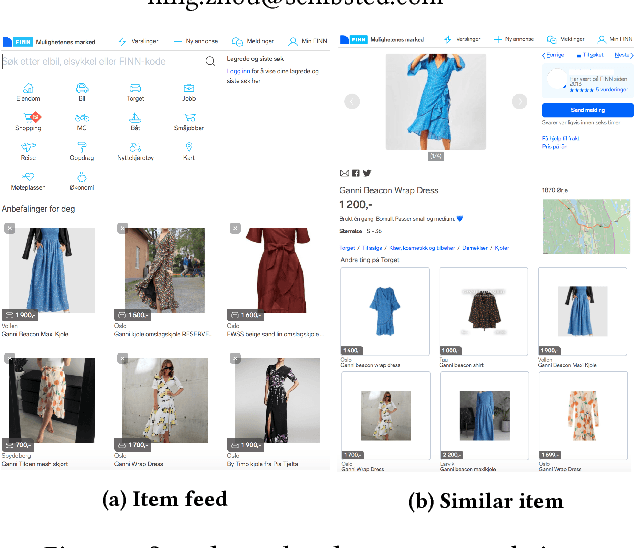

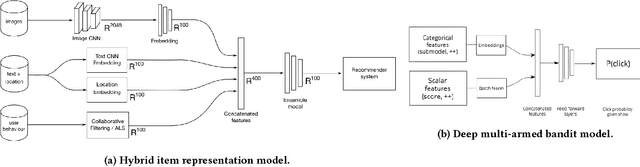
Recommendations are broadly used in marketplaces to match users with items relevant to their interests and needs. To understand user intent and tailor recommendations to their needs, we use deep learning to explore various heterogeneous data available in marketplaces. This paper focuses on the challenge of measuring recommender performance and summarizes the online experiment results with several promising types of deep neural network recommenders - hybrid item representation models combining features from user engagement and content, sequence-based models, and multi-armed bandit models that optimize user engagement by re-ranking proposals from multiple submodels. The recommenders are currently running in production at the leading Norwegian marketplace FINN.no and serves over one million visitors everyday.