 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNorwAI's Large Language Models: Technical Report
Jan 08, 2026Norwegian, spoken by approximately five million people, remains underrepresented in many of the most significant breakthroughs in Natural Language Processing (NLP). To address this gap, the NorLLM team at NorwAI has developed a family of models specifically tailored to Norwegian and other Scandinavian languages, building on diverse Transformer-based architectures such as GPT, Mistral, Llama2, Mixtral and Magistral. These models are either pretrained from scratch or continually pretrained on 25B - 88.45B tokens, using a Norwegian-extended tokenizer and advanced post-training strategies to optimize performance, enhance robustness, and improve adaptability across various real-world tasks. Notably, instruction-tuned variants (e.g., Mistral-7B-Instruct and Mixtral-8x7B-Instruct) showcase strong assistant-style capabilities, underscoring their potential for practical deployment in interactive and domain-specific applications. The NorwAI large language models are openly available to Nordic organizations, companies and students for both research and experimental use. This report provides detailed documentation of the model architectures, training data, tokenizer design, fine-tuning strategies, deployment, and evaluations.
The Impact of Copyrighted Material on Large Language Models: A Norwegian Perspective
Dec 12, 2024



The use of copyrighted materials in training generative language models raises critical legal and ethical questions. This paper presents a framework for and the results of empirically assessing the impact of copyrighted materials on the performance of large language models (LLMs) for Norwegian. We found that both books and newspapers contribute positively when the models are evaluated on a diverse set of Norwegian benchmarks, while fiction works possibly lead to decreased performance. Our experiments could inform the creation of a compensation scheme for authors whose works contribute to AI development.
PersonalSum: A User-Subjective Guided Personalized Summarization Dataset for Large Language Models
Oct 04, 2024With the rapid advancement of Natural Language Processing in recent years, numerous studies have shown that generic summaries generated by Large Language Models (LLMs) can sometimes surpass those annotated by experts, such as journalists, according to human evaluations. However, there is limited research on whether these generic summaries meet the individual needs of ordinary people. The biggest obstacle is the lack of human-annotated datasets from the general public. Existing work on personalized summarization often relies on pseudo datasets created from generic summarization datasets or controllable tasks that focus on specific named entities or other aspects, such as the length and specificity of generated summaries, collected from hypothetical tasks without the annotators' initiative. To bridge this gap, we propose a high-quality, personalized, manually annotated abstractive summarization dataset called PersonalSum. This dataset is the first to investigate whether the focus of public readers differs from the generic summaries generated by LLMs. It includes user profiles, personalized summaries accompanied by source sentences from given articles, and machine-generated generic summaries along with their sources. We investigate several personal signals - entities/topics, plot, and structure of articles - that may affect the generation of personalized summaries using LLMs in a few-shot in-context learning scenario. Our preliminary results and analysis indicate that entities/topics are merely one of the key factors that impact the diverse preferences of users, and personalized summarization remains a significant challenge for existing LLMs.
Understanding Language Modeling Paradigm Adaptations in Recommender Systems: Lessons Learned and Open Challenges
Apr 04, 2024The emergence of Large Language Models (LLMs) has achieved tremendous success in the field of Natural Language Processing owing to diverse training paradigms that empower LLMs to effectively capture intricate linguistic patterns and semantic representations. In particular, the recent "pre-train, prompt and predict" training paradigm has attracted significant attention as an approach for learning generalizable models with limited labeled data. In line with this advancement, these training paradigms have recently been adapted to the recommendation domain and are seen as a promising direction in both academia and industry. This half-day tutorial aims to provide a thorough understanding of extracting and transferring knowledge from pre-trained models learned through different training paradigms to improve recommender systems from various perspectives, such as generality, sparsity, effectiveness and trustworthiness. In this tutorial, we first introduce the basic concepts and a generic architecture of the language modeling paradigm for recommendation purposes. Then, we focus on recent advancements in adapting LLM-related training strategies and optimization objectives for different recommendation tasks. After that, we will systematically introduce ethical issues in LLM-based recommender systems and discuss possible approaches to assessing and mitigating them. We will also summarize the relevant datasets, evaluation metrics, and an empirical study on the recommendation performance of training paradigms. Finally, we will conclude the tutorial with a discussion of open challenges and future directions.
NLEBench+NorGLM: A Comprehensive Empirical Analysis and Benchmark Dataset for Generative Language Models in Norwegian
Dec 03, 2023



Recent advancements in Generative Language Models (GLMs) have transformed Natural Language Processing (NLP) by showcasing the effectiveness of the "pre-train, prompt, and predict" paradigm in utilizing pre-trained GLM knowledge for diverse applications. Despite their potential, these capabilities lack adequate quantitative characterization due to the absence of comprehensive benchmarks, particularly for low-resource languages. Existing low-resource benchmarks focus on discriminative language models like BERT, neglecting the evaluation of generative language models. Moreover, current benchmarks often overlook measuring generalization performance across multiple tasks, a crucial metric for GLMs. To bridge these gaps, we introduce NLEBench, a comprehensive benchmark tailored for evaluating natural language generation capabilities in Norwegian, a low-resource language. We use Norwegian as a case study to explore whether current GLMs and benchmarks in mainstream languages like English can reveal the unique characteristics of underrepresented languages. NLEBench encompasses a suite of real-world NLP tasks ranging from news storytelling, summarization, open-domain conversation, natural language understanding, instruction fine-tuning, toxicity and bias evaluation, to self-curated Chain-of-Thought investigation. It features two high-quality, human-annotated datasets: an instruction dataset covering traditional Norwegian cultures, idioms, slang, and special expressions, and a document-grounded multi-label dataset for topic classification, question answering, and summarization. This paper also introduces foundational Norwegian Generative Language Models (NorGLMs) developed with diverse parameter scales and Transformer-based architectures. Systematic evaluations on the proposed benchmark suite provide insights into the capabilities and scalability of NorGLMs across various downstream tasks.
Pre-train, Prompt and Recommendation: A Comprehensive Survey of Language Modelling Paradigm Adaptations in Recommender Systems
Feb 07, 2023The emergency of Pre-trained Language Models (PLMs) has achieved tremendous success in the field of Natural Language Processing (NLP) by learning universal representations on large corpora in a self-supervised manner. The pre-trained models and the learned representations can be beneficial to a series of downstream NLP tasks. This training paradigm has recently been adapted to the recommendation domain and is considered a promising approach by both academia and industry. In this paper, we systematically investigate how to extract and transfer knowledge from pre-trained models learned by different PLM-related training paradigms to improve recommendation performance from various perspectives, such as generality, sparsity, efficiency and effectiveness. Specifically, we propose an orthogonal taxonomy to divide existing PLM-based recommender systems w.r.t. their training strategies and objectives. Then, we analyze and summarize the connection between PLM-based training paradigms and different input data types for recommender systems. Finally, we elaborate on open issues and future research directions in this vibrant field.
Recommending on Graphs: A Comprehensive Review from Data Perspective
Dec 23, 2022Recent advances in graph-based learning approaches have demonstrated their effectiveness in modelling users' preferences and items' characteristics for Recommender Systems (RSS). Most of the data in RSS can be organized into graphs where various objects (e.g., users, items, and attributes) are explicitly or implicitly connected and influence each other via various relations. Such a graph-based organization brings benefits to exploiting potential properties in graph learning (e.g., random walk and network embedding) techniques to enrich the representations of the user and item nodes, which is an essential factor for successful recommendations. In this paper, we provide a comprehensive survey of Graph Learning-based Recommender Systems (GLRSs). Specifically, we start from a data-driven perspective to systematically categorize various graphs in GLRSs and analyze their characteristics. Then, we discuss the state-of-the-art frameworks with a focus on the graph learning module and how they address practical recommendation challenges such as scalability, fairness, diversity, explainability and so on. Finally, we share some potential research directions in this rapidly growing area.
Evaluating and Improving Context Attention Distribution on Multi-Turn Response Generation using Self-Contained Distractions
Nov 09, 2022Despite the rapid progress of open-domain generation-based conversational agents, most deployed systems treat dialogue contexts as single-turns, while systems dealing with multi-turn contexts are less studied. There is a lack of a reliable metric for evaluating multi-turn modelling, as well as an effective solution for improving it. In this paper, we focus on an essential component of multi-turn generation-based conversational agents: context attention distribution, i.e. how systems distribute their attention on dialogue's context. For evaluation of this component, We introduce a novel attention-mechanism-based metric: DAS ratio. To improve performance on this component, we propose an optimization strategy that employs self-contained distractions. Our experiments on the Ubuntu chatlogs dataset show that models with comparable perplexity can be distinguished by their ability on context attention distribution. Our proposed optimization strategy improves both non-hierarchical and hierarchical models on the proposed metric by about 10% from baselines.
Balancing Multi-Domain Corpora Learning for Open-Domain Response Generation
May 05, 2022
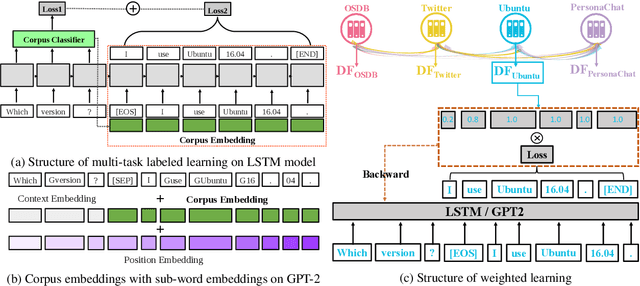
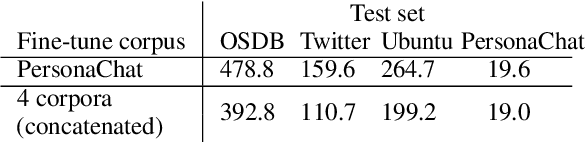
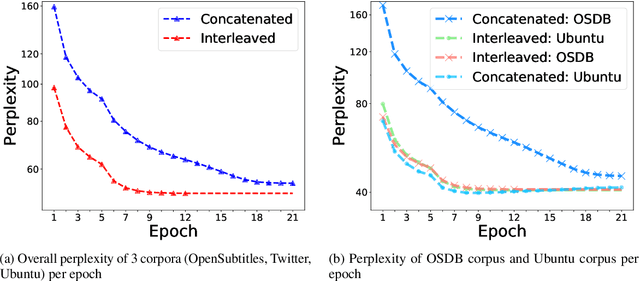
Open-domain conversational systems are assumed to generate equally good responses on multiple domains. Previous work achieved good performance on the single corpus, but training and evaluating on multiple corpora from different domains are less studied. This paper explores methods of generating relevant responses for each of multiple multi-domain corpora. We first examine interleaved learning which intermingles multiple corpora as the baseline. We then investigate two multi-domain learning methods, labeled learning and multi-task labeled learning, which encode each corpus through a unique corpus embedding. Furthermore, we propose Domain-specific Frequency (DF), a novel word-level importance weight that measures the relative importance of a word for a specific corpus compared to other corpora. Based on DF, we propose weighted learning, a method that integrates DF to the loss function. We also adopt DF as a new evaluation metric. Extensive experiments show that our methods gain significant improvements on both automatic and human evaluation. We share our code and data for reproducibility
Neural Networks for Entity Matching
Oct 21, 2020
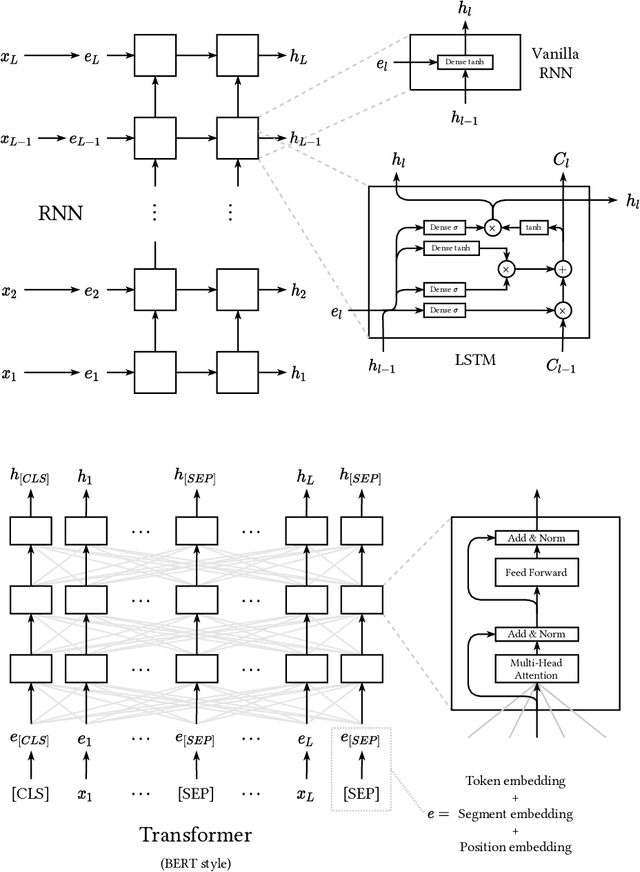
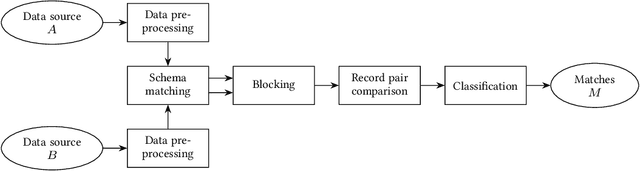
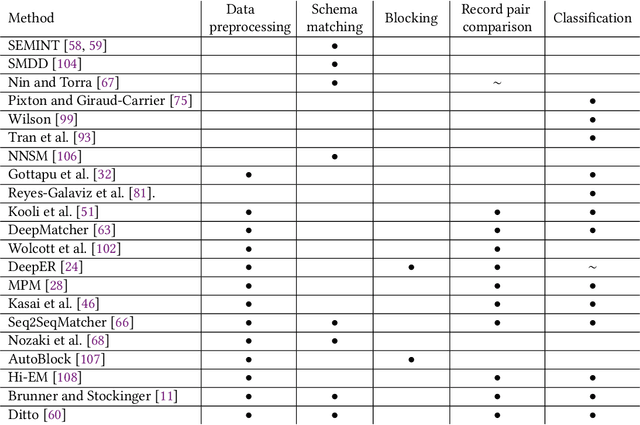
Entity matching is the problem of identifying which records refer to the same real-world entity. It has been actively researched for decades, and a variety of different approaches have been developed. Even today, it remains a challenging problem, and there is still generous room for improvement. In recent years we have seen new methods based upon deep learning techniques for natural language processing emerge. In this survey, we present how neural networks have been used for entity matching. Specifically, we identify which steps of the entity matching process existing work have targeted using neural networks, and provide an overview of the different techniques used at each step. We also discuss contributions from deep learning in entity matching compared to traditional methods, and propose a taxonomy of deep neural networks for entity matching.