 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalSum: A User-Subjective Guided Personalized Summarization Dataset for Large Language Models
Oct 04, 2024With the rapid advancement of Natural Language Processing in recent years, numerous studies have shown that generic summaries generated by Large Language Models (LLMs) can sometimes surpass those annotated by experts, such as journalists, according to human evaluations. However, there is limited research on whether these generic summaries meet the individual needs of ordinary people. The biggest obstacle is the lack of human-annotated datasets from the general public. Existing work on personalized summarization often relies on pseudo datasets created from generic summarization datasets or controllable tasks that focus on specific named entities or other aspects, such as the length and specificity of generated summaries, collected from hypothetical tasks without the annotators' initiative. To bridge this gap, we propose a high-quality, personalized, manually annotated abstractive summarization dataset called PersonalSum. This dataset is the first to investigate whether the focus of public readers differs from the generic summaries generated by LLMs. It includes user profiles, personalized summaries accompanied by source sentences from given articles, and machine-generated generic summaries along with their sources. We investigate several personal signals - entities/topics, plot, and structure of articles - that may affect the generation of personalized summaries using LLMs in a few-shot in-context learning scenario. Our preliminary results and analysis indicate that entities/topics are merely one of the key factors that impact the diverse preferences of users, and personalized summarization remains a significant challenge for existing LLMs.
Towards human performance on automatic motion tracking of infant spontaneous movements
Oct 22, 2020



Assessment of spontaneous movements can predict the long-term developmental outcomes in high-risk infants. In order to develop algorithms for automated prediction of later function based on early motor repertoire, high-precision tracking of segments and joints are required. Four types of convolutional neural networks were investigated on a novel infant pose dataset, covering the large variation in 1 424 videos from a clinical international community. The precision level of the networks was evaluated as the deviation between the estimated keypoint positions and human expert annotations. The computational efficiency was also assessed to determine the feasibility of the neural networks in clinical practice. The study shows that the precision of the best performing infant motion tracker is similar to the inter-rater error of human experts, while still operating efficiently. In conclusion, the proposed tracking of infant movements can pave the way for early detection of motor disorders in children with perinatal brain injuries by quantifying infant movements from video recordings with human precision.
Prediction Intervals: Split Normal Mixture from Quality-Driven Deep Ensembles
Jul 19, 2020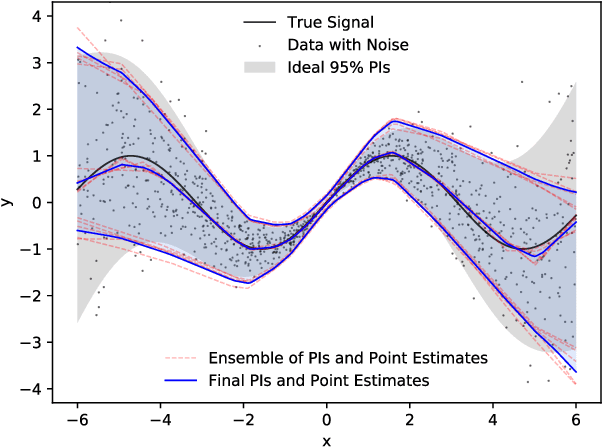
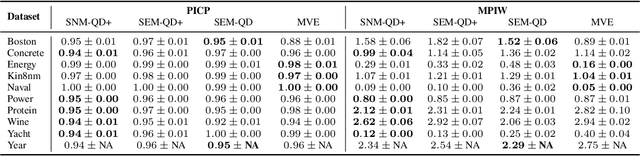
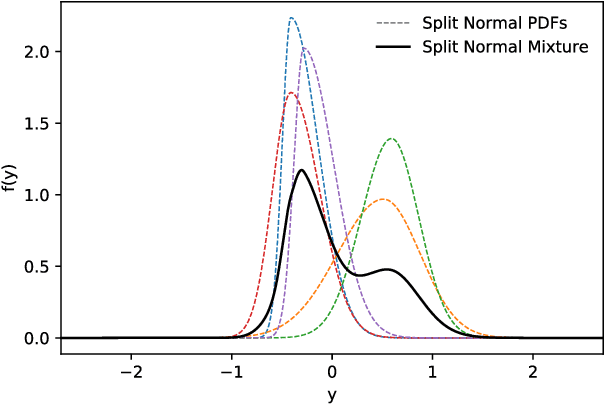
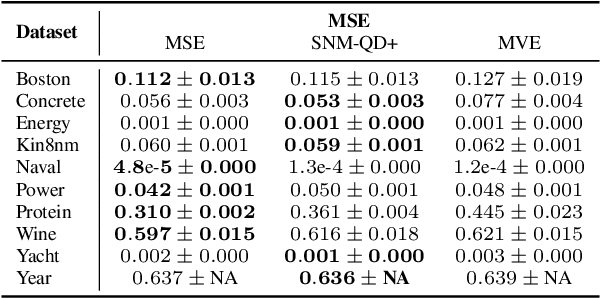
Prediction intervals are a machine- and human-interpretable way to represent predictive uncertainty in a regression analysis. In this paper, we present a method for generating prediction intervals along with point estimates from an ensemble of neural networks. We propose a multi-objective loss function fusing quality measures related to prediction intervals and point estimates, and a penalty function, which enforces semantic integrity of the results and stabilizes the training process of the neural networks. The ensembled prediction intervals are aggregated as a split normal mixture accounting for possible multimodality and asymmetricity of the posterior predictive distribution, and resulting in prediction intervals that capture aleatoric and epistemic uncertainty. Our results show that both our quality-driven loss function and our aggregation method contribute to well-calibrated prediction intervals and point estimates.
EfficientPose: Scalable single-person pose estimation
Apr 25, 2020



Human pose estimation facilitates markerless movement analysis in sports, as well as in clinical applications. Still, state-of-the-art models for human pose estimation generally do not meet the requirements for real-life deployment. The main reason for this is that the more the field progresses, the more expensive the approaches become, with high computational demands. To cope with the challenges caused by this trend, we propose a convolutional neural network architecture that benefits from the recently proposed EfficientNets to deliver scalable single-person pose estimation. To this end, we introduce EfficientPose, which is a family of models harnessing an effective multi-scale feature extractor, computation efficient detection blocks utilizing mobile inverted bottleneck convolutions, and upscaling improving precision of pose configurations. EfficientPose enables real-world deployment on edge devices through 500K parameter model consuming less than one GFLOP. The results from our experiments, using the challenging MPII single-person benchmark, show that the proposed EfficientPose models substantially outperform the widely-used OpenPose model in terms of accuracy, while being at the same time up to 15 times smaller and 20 times more computationally efficient than its counterpart.
Forecasting Intra-Hour Imbalances in Electric Power Systems
Feb 01, 2019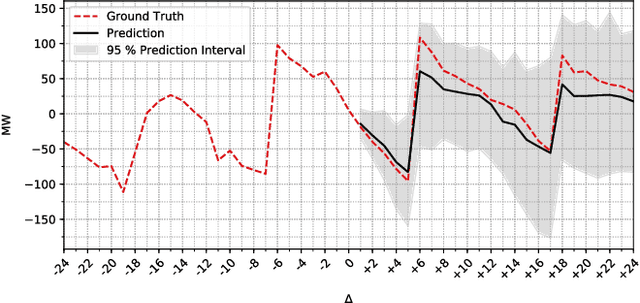
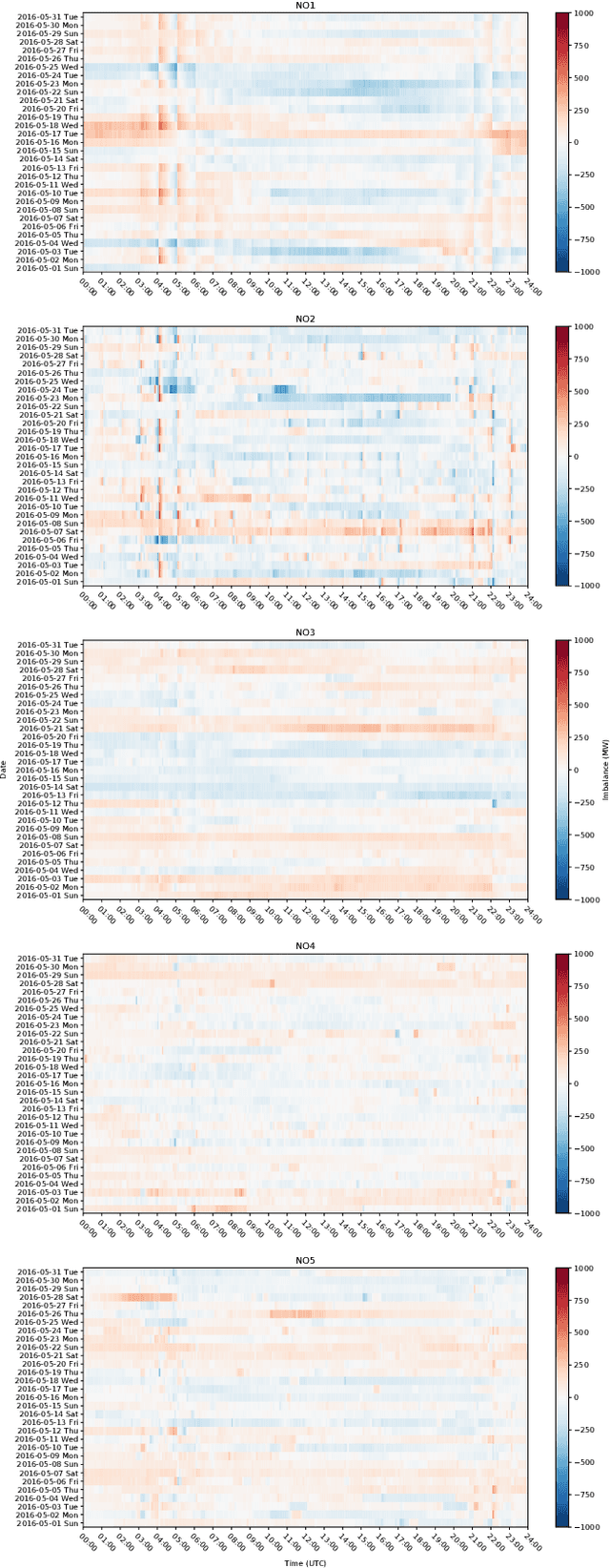
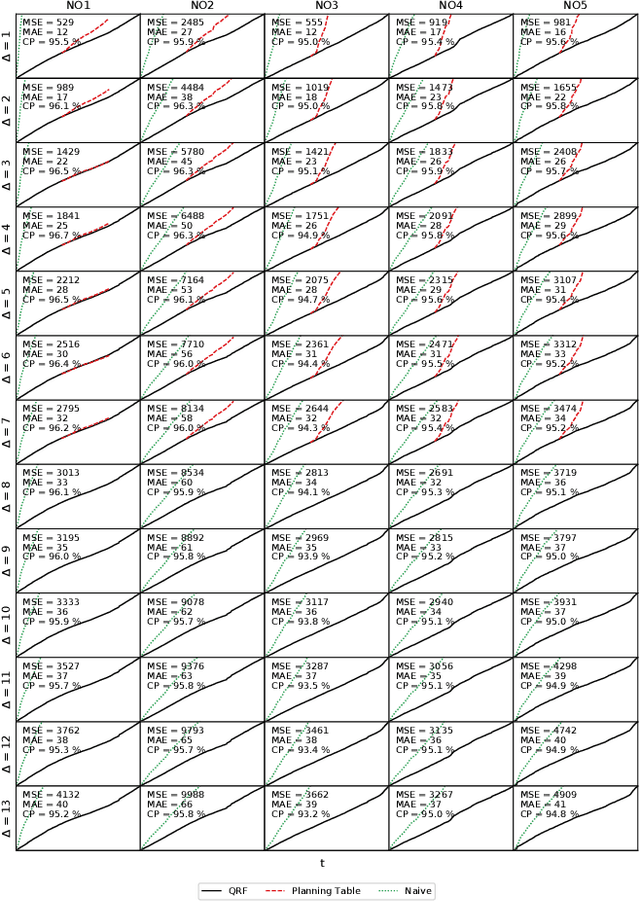
Keeping the electricity production in balance with the actual demand is becoming a difficult and expensive task in spite of an involvement of experienced human operators. This is due to the increasing complexity of the electric power grid system with the intermittent renewable production as one of the contributors. A beforehand information about an occurring imbalance can help the transmission system operator to adjust the production plans, and thus ensure a high security of supply by reducing the use of costly balancing reserves, and consequently reduce undesirable fluctuations of the 50 Hz power system frequency. In this paper, we introduce the relatively new problem of an intra-hour imbalance forecasting for the transmission system operator (TSO). We focus on the use case of the Norwegian TSO, Statnett. We present a complementary imbalance forecasting tool that is able to support the TSO in determining the trend of future imbalances, and show the potential to proactively alleviate imbalances with a higher accuracy compared to the contemporary solution.
Securing Tag-based recommender systems against profile injection attacks: A comparative study. (Extended Report)
Jan 24, 2019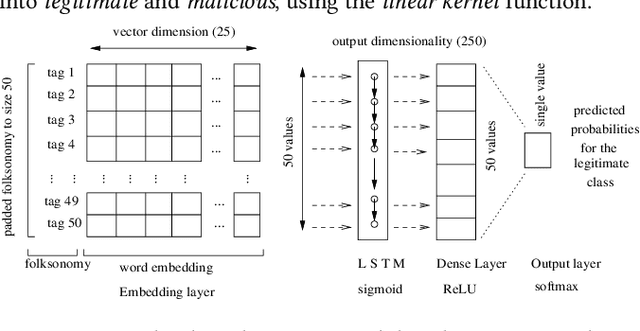
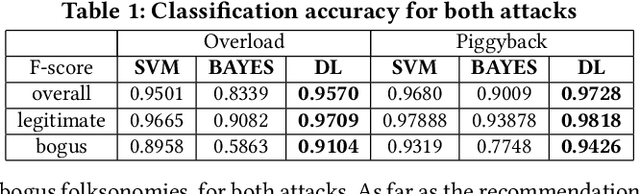
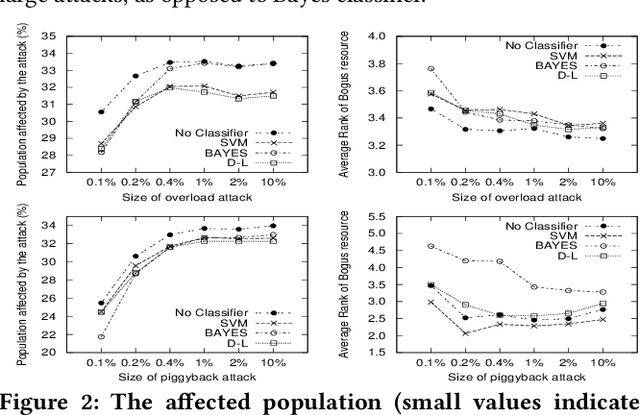
This work addresses the challenges related to attacks on collaborative tagging systems, which often comes in a form of malicious annotations or profile injection attacks. In particular, we study various countermeasures against two types of such attacks for social tagging systems, the Overload attack and the Piggyback attack. The countermeasure schemes studied here include baseline classifiers such as, Naive Bayes filter and Support Vector Machine, as well as a Deep Learning approach. Our evaluation performed over synthetic spam data generated from del.icio.us dataset, shows that in most cases, Deep Learning can outperform the classical solutions, providing high-level protection against threats.
Extracting News Events from Microblogs
Jun 20, 2018
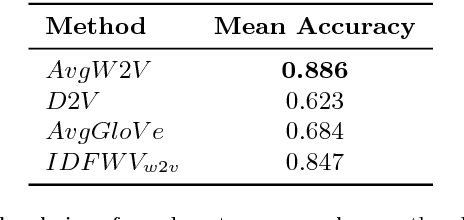


Twitter stream has become a large source of information for many people, but the magnitude of tweets and the noisy nature of its content have made harvesting the knowledge from Twitter a challenging task for researchers for a long time. Aiming at overcoming some of the main challenges of extracting the hidden information from tweet streams, this work proposes a new approach for real-time detection of news events from the Twitter stream. We divide our approach into three steps. The first step is to use a neural network or deep learning to detect news-relevant tweets from the stream. The second step is to apply a novel streaming data clustering algorithm to the detected news tweets to form news events. The third and final step is to rank the detected events based on the size of the event clusters and growth speed of the tweet frequencies. We evaluate the proposed system on a large, publicly available corpus of annotated news events from Twitter. As part of the evaluation, we compare our approach with a related state-of-the-art solution. Overall, our experiments and user-based evaluation show that our approach on detecting current (real) news events delivers a state-of-the-art performance.
Context-Aware Sequence-to-Sequence Models for Conversational Systems
May 22, 2018
This work proposes a novel approach based on sequence-to-sequence (seq2seq) models for context-aware conversational systems. Exist- ing seq2seq models have been shown to be good for generating natural responses in a data-driven conversational system. However, they still lack mechanisms to incorporate previous conversation turns. We investigate RNN-based methods that efficiently integrate previous turns as a context for generating responses. Overall, our experimental results based on human judgment demonstrate the feasibility and effectiveness of the proposed approach.
Detecting Offensive Language in Tweets Using Deep Learning
Jan 13, 2018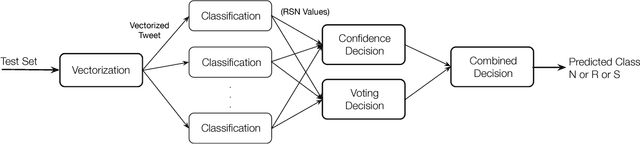


This paper addresses the important problem of discerning hateful content in social media. We propose a detection scheme that is an ensemble of Recurrent Neural Network (RNN) classifiers, and it incorporates various features associated with user-related information, such as the users' tendency towards racism or sexism. These data are fed as input to the above classifiers along with the word frequency vectors derived from the textual content. Our approach has been evaluated on a publicly available corpus of 16k tweets, and the results demonstrate its effectiveness in comparison to existing state of the art solutions. More specifically, our scheme can successfully distinguish racism and sexism messages from normal text, and achieve higher classification quality than current state-of-the-art algorithms.
A Deep Network Model for Paraphrase Detection in Short Text Messages
Dec 07, 2017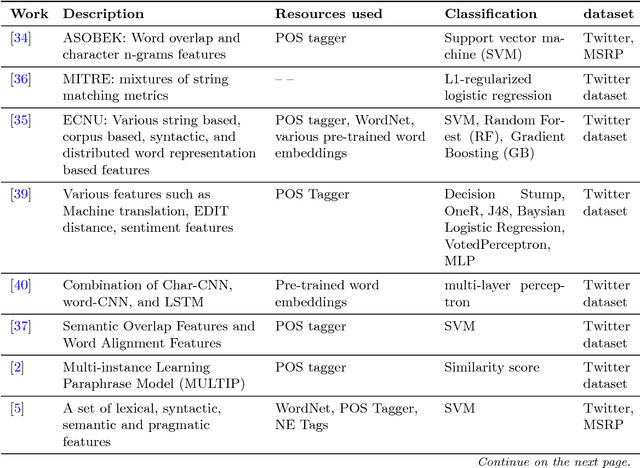
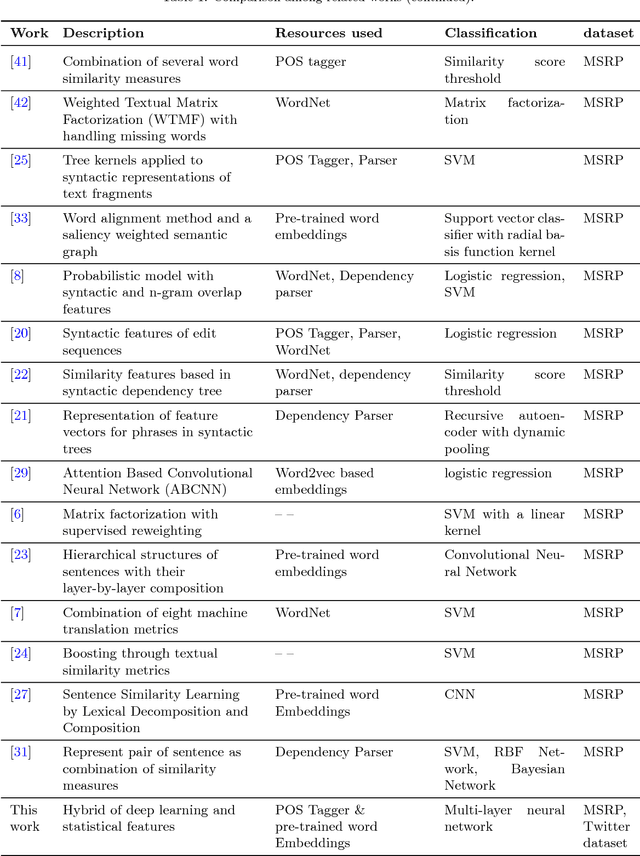
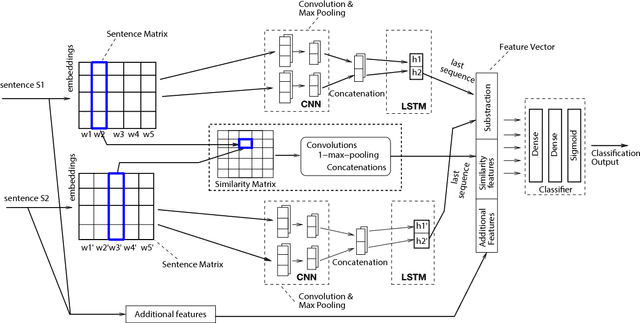
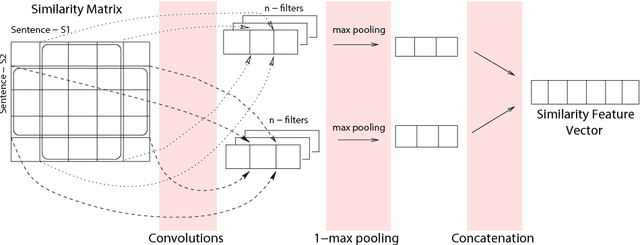
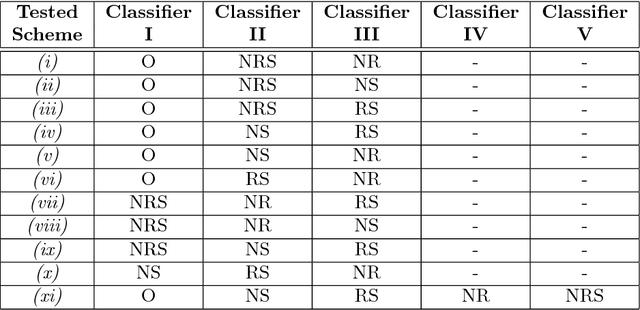
This paper is concerned with paraphrase detection. The ability to detect similar sentences written in natural language is crucial for several applications, such as text mining, text summarization, plagiarism detection, authorship authentication and question answering. Given two sentences, the objective is to detect whether they are semantically identical. An important insight from this work is that existing paraphrase systems perform well when applied on clean texts, but they do not necessarily deliver good performance against noisy texts. Challenges with paraphrase detection on user generated short texts, such as Twitter, include language irregularity and noise. To cope with these challenges, we propose a novel deep neural network-based approach that relies on coarse-grained sentence modeling using a convolutional neural network and a long short-term memory model, combined with a specific fine-grained word-level similarity matching model. Our experimental results show that the proposed approach outperforms existing state-of-the-art approaches on user-generated noisy social media data, such as Twitter texts, and achieves highly competitive performance on a cleaner corpus.