 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Land Anywhere: Transferable Generative Models for Aircraft Trajectories
Nov 06, 2025
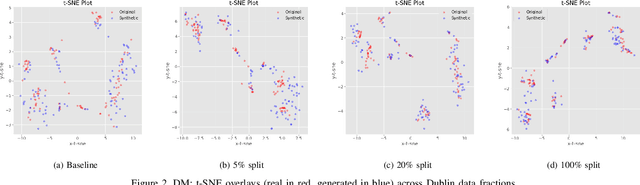


Access to trajectory data is a key requirement for developing and validating Air Traffic Management (ATM) solutions, yet many secondary and regional airports face severe data scarcity. This limits the applicability of machine learning methods and the ability to perform large-scale simulations or "what-if" analyses. In this paper, we investigate whether generative models trained on data-rich airports can be efficiently adapted to data-scarce airports using transfer learning. We adapt state-of-the-art diffusion- and flow-matching-based architectures to the aviation domain and evaluate their transferability between Zurich (source) and Dublin (target) landing trajectory datasets. Models are pretrained on Zurich and fine-tuned on Dublin with varying amounts of local data, ranging from 0% to 100%. Results show that diffusion-based models achieve competitive performance with as little as 5% of the Dublin data and reach baseline-level performance around 20%, consistently outperforming models trained from scratch across metrics and visual inspections. Latent flow matching and latent diffusion models also benefit from pretraining, though with more variable gains, while flow matching models show weaker generalization. Despite challenges in capturing rare trajectory patterns, these findings demonstrate the potential of transfer learning to substantially reduce data requirements for trajectory generation in ATM, enabling realistic synthetic data generation even in environments with limited historical records.
PIGPVAE: Physics-Informed Gaussian Process Variational Autoencoders
May 25, 2025Recent advances in generative AI offer promising solutions for synthetic data generation but often rely on large datasets for effective training. To address this limitation, we propose a novel generative model that learns from limited data by incorporating physical constraints to enhance performance. Specifically, we extend the VAE architecture by incorporating physical models in the generative process, enabling it to capture underlying dynamics more effectively. While physical models provide valuable insights, they struggle to capture complex temporal dependencies present in real-world data. To bridge this gap, we introduce a discrepancy term to account for unmodeled dynamics, represented within a latent Gaussian Process VAE (GPVAE). Furthermore, we apply regularization to ensure the generated data aligns closely with observed data, enhancing both the diversity and accuracy of the synthetic samples. The proposed method is applied to indoor temperature data, achieving state-of-the-art performance. Additionally, we demonstrate that PIGPVAE can produce realistic samples beyond the observed distribution, highlighting its robustness and usefulness under distribution shifts.
Synthetic Aircraft Trajectory Generation Using Time-Based VQ-VAE
Apr 12, 2025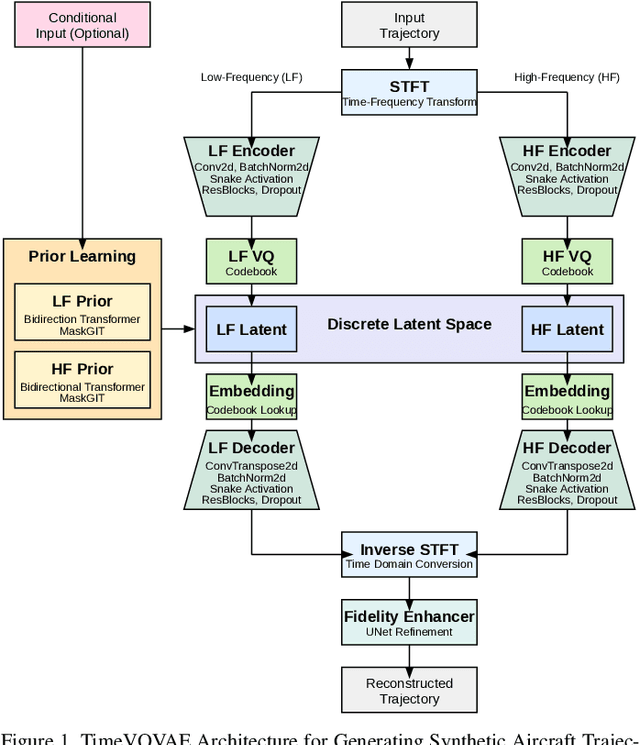
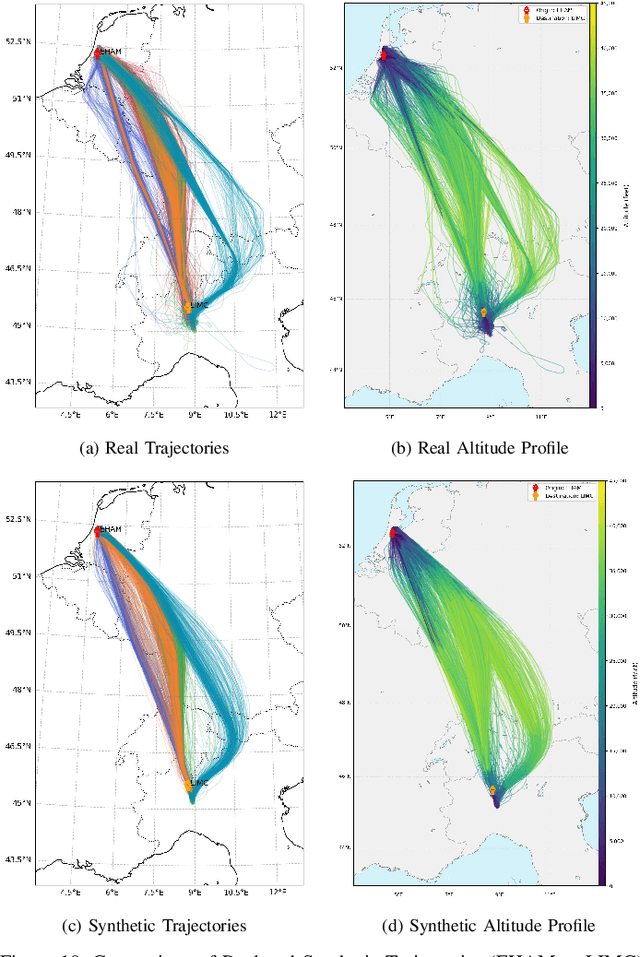
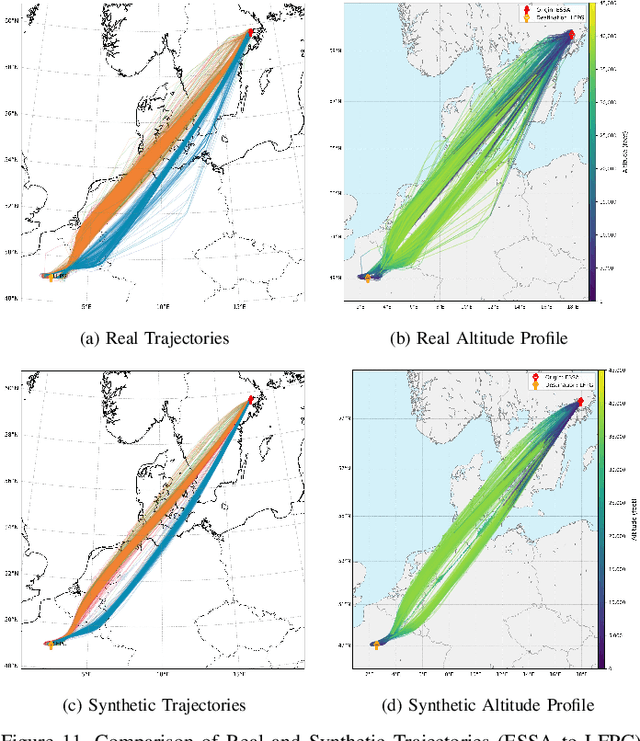
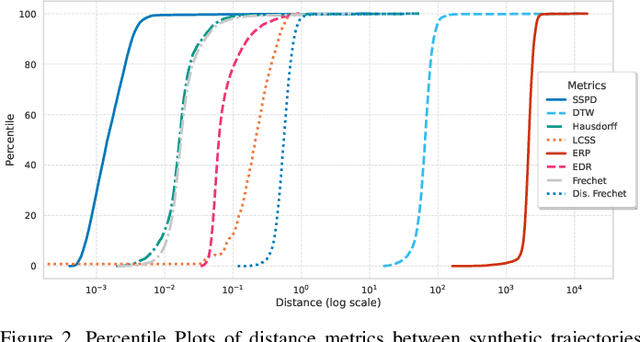
In modern air traffic management, generating synthetic flight trajectories has emerged as a promising solution for addressing data scarcity, protecting sensitive information, and supporting large-scale analyses. In this paper, we propose a novel method for trajectory synthesis by adapting the Time-Based Vector Quantized Variational Autoencoder (TimeVQVAE). Our approach leverages time-frequency domain processing, vector quantization, and transformer-based priors to capture both global and local dynamics in flight data. By discretizing the latent space and integrating transformer priors, the model learns long-range spatiotemporal dependencies and preserves coherence across entire flight paths. We evaluate the adapted TimeVQVAE using an extensive suite of quality, statistical, and distributional metrics, as well as a flyability assessment conducted in an open-source air traffic simulator. Results indicate that TimeVQVAE outperforms a temporal convolutional VAE baseline, generating synthetic trajectories that mirror real flight data in terms of spatial accuracy, temporal consistency, and statistical properties. Furthermore, the simulator-based assessment shows that most generated trajectories maintain operational feasibility, although occasional outliers underscore the potential need for additional domain-specific constraints. Overall, our findings underscore the importance of multi-scale representation learning for capturing complex flight behaviors and demonstrate the promise of TimeVQVAE in producing representative synthetic trajectories for downstream tasks such as model training, airspace design, and air traffic forecasting.
SiamTST: A Novel Representation Learning Framework for Enhanced Multivariate Time Series Forecasting applied to Telco Networks
Jul 02, 2024



We introduce SiamTST, a novel representation learning framework for multivariate time series. SiamTST integrates a Siamese network with attention, channel-independent patching, and normalization techniques to achieve superior performance. Evaluated on a real-world industrial telecommunication dataset, SiamTST demonstrates significant improvements in forecasting accuracy over existing methods. Notably, a simple linear network also shows competitive performance, achieving the second-best results, just behind SiamTST. The code is available at https://github.com/simenkristoff/SiamTST.
Enhancing Indoor Temperature Forecasting through Synthetic Data in Low-Data Environments
Jun 07, 2024Forecasting indoor temperatures is important to achieve efficient control of HVAC systems. In this task, the limited data availability presents a challenge as most of the available data is acquired during standard operation where extreme scenarios and transitory regimes such as major temperature increases or decreases are de-facto excluded. Acquisition of such data requires significant energy consumption and a dedicated facility, hindering the quantity and diversity of available data. Cost related constraints however do not allow for continuous year-around acquisition. To address this, we investigate the efficacy of data augmentation techniques leveraging SoTA AI-based methods for synthetic data generation. Inspired by practical and experimental motivations, we explore fusion strategies of real and synthetic data to improve forecasting models. This approach alleviates the need for continuously acquiring extensive time series data, especially in contexts involving repetitive heating and cooling cycles in buildings. In our evaluation 1) we assess the performance of synthetic data generators independently, particularly focusing on SoTA AI-based methods; 2) we measure the utility of incorporating synthetically augmented data in a subsequent forecasting tasks where we employ a simple model in two distinct scenarios: 1) we first examine an augmentation technique that combines real and synthetically generated data to expand the training dataset, 2) we delve into utilizing synthetic data to tackle dataset imbalances. Our results highlight the potential of synthetic data augmentation in enhancing forecasting accuracy while mitigating training variance. Through empirical experiments, we show significant improvements achievable by integrating synthetic data, thereby paving the way for more robust forecasting models in low-data regime.
Global Transformer Architecture for Indoor Room Temperature Forecasting
Oct 31, 2023A thorough regulation of building energy systems translates in relevant energy savings and in a better comfort for the occupants. Algorithms to predict the thermal state of a building on a certain time horizon with a good confidence are essential for the implementation of effective control systems. This work presents a global Transformer architecture for indoor temperature forecasting in multi-room buildings, aiming at optimizing energy consumption and reducing greenhouse gas emissions associated with HVAC systems. Recent advancements in deep learning have enabled the development of more sophisticated forecasting models compared to traditional feedback control systems. The proposed global Transformer architecture can be trained on the entire dataset encompassing all rooms, eliminating the need for multiple room-specific models, significantly improving predictive performance, and simplifying deployment and maintenance. Notably, this study is the first to apply a Transformer architecture for indoor temperature forecasting in multi-room buildings. The proposed approach provides a novel solution to enhance the accuracy and efficiency of temperature forecasting, serving as a valuable tool to optimize energy consumption and decrease greenhouse gas emissions in the building sector.
Navigating the Metric Maze: A Taxonomy of Evaluation Metrics for Anomaly Detection in Time Series
Mar 02, 2023The field of time series anomaly detection is constantly advancing, with several methods available, making it a challenge to determine the most appropriate method for a specific domain. The evaluation of these methods is facilitated by the use of metrics, which vary widely in their properties. Despite the existence of new evaluation metrics, there is limited agreement on which metrics are best suited for specific scenarios and domain, and the most commonly used metrics have faced criticism in the literature. This paper provides a comprehensive overview of the metrics used for the evaluation of time series anomaly detection methods, and also defines a taxonomy of these based on how they are calculated. By defining a set of properties for evaluation metrics and a set of specific case studies and experiments, twenty metrics are analyzed and discussed in detail, highlighting the unique suitability of each for specific tasks. Through extensive experimentation and analysis, this paper argues that the choice of evaluation metric must be made with care, taking into account the specific requirements of the task at hand.
Persistence Initialization: A novel adaptation of the Transformer architecture for Time Series Forecasting
Aug 30, 2022
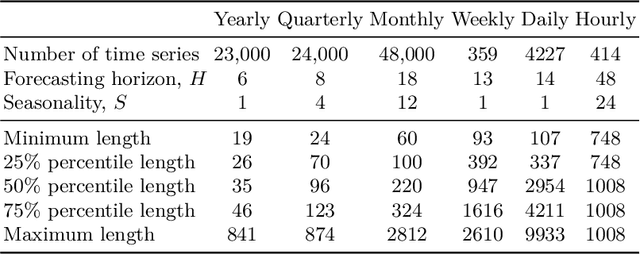
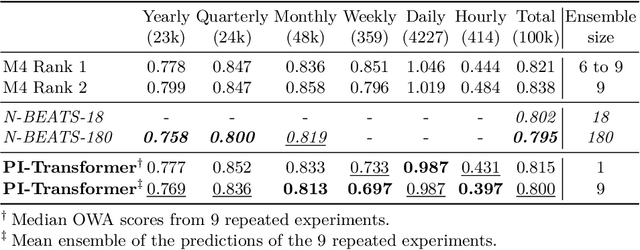
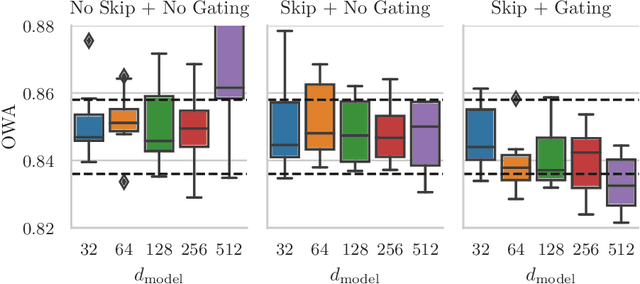
Time series forecasting is an important problem, with many real world applications. Ensembles of deep neural networks have recently achieved impressive forecasting accuracy, but such large ensembles are impractical in many real world settings. Transformer models been successfully applied to a diverse set of challenging problems. We propose a novel adaptation of the original Transformer architecture focusing on the task of time series forecasting, called Persistence Initialization. The model is initialized as a naive persistence model by using a multiplicative gating mechanism combined with a residual skip connection. We use a decoder Transformer with ReZero normalization and Rotary positional encodings, but the adaptation is applicable to any auto-regressive neural network model. We evaluate our proposed architecture on the challenging M4 dataset, achieving competitive performance compared to ensemble based methods. We also compare against existing recently proposed Transformer models for time series forecasting, showing superior performance on the M4 dataset. Extensive ablation studies show that Persistence Initialization leads to better performance and faster convergence. As the size of the model increases, only the models with our proposed adaptation gain in performance. We also perform an additional ablation study to determine the importance of the choice of normalization and positional encoding, and find both the use of Rotary encodings and ReZero normalization to be essential for good forecasting performance.
Positional Encoding Augmented GAN for the Assessment of Wind Flow for Pedestrian Comfort in Urban Areas
Jan 04, 2022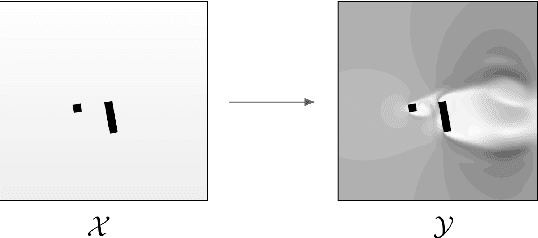
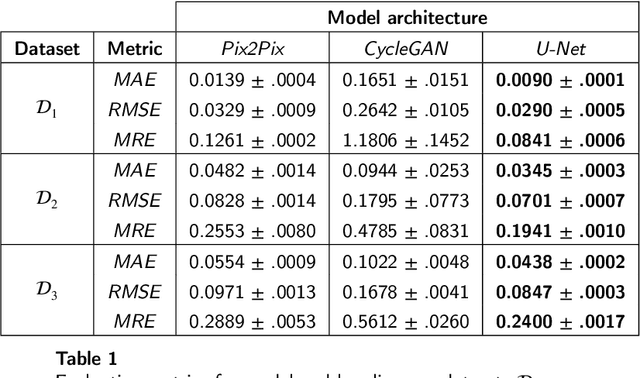

Approximating wind flows using computational fluid dynamics (CFD) methods can be time-consuming. Creating a tool for interactively designing prototypes while observing the wind flow change requires simpler models to simulate faster. Instead of running numerical approximations resulting in detailed calculations, data-driven methods and deep learning might be able to give similar results in a fraction of the time. This work rephrases the problem from computing 3D flow fields using CFD to a 2D image-to-image translation-based problem on the building footprints to predict the flow field at pedestrian height level. We investigate the use of generative adversarial networks (GAN), such as Pix2Pix [1] and CycleGAN [2] representing state-of-the-art for image-to-image translation task in various domains as well as U-Net autoencoder [3]. The models can learn the underlying distribution of a dataset in a data-driven manner, which we argue can help the model learn the underlying Reynolds-averaged Navier-Stokes (RANS) equations from CFD. We experiment on novel simulated datasets on various three-dimensional bluff-shaped buildings with and without height information. Moreover, we present an extensive qualitative and quantitative evaluation of the generated images for a selection of models and compare their performance with the simulations delivered by CFD. We then show that adding positional data to the input can produce more accurate results by proposing a general framework for injecting such information on the different architectures. Furthermore, we show that the models performances improve by applying attention mechanisms and spectral normalization to facilitate stable training.
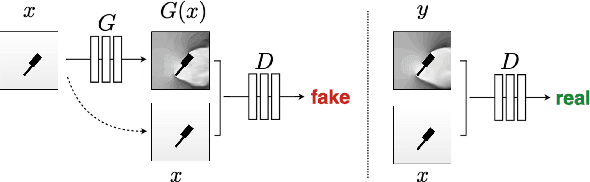
Augmented Memory Networks for Streaming-Based Active One-Shot Learning
Sep 04, 2019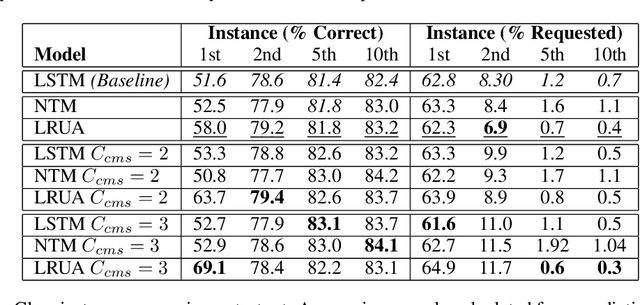
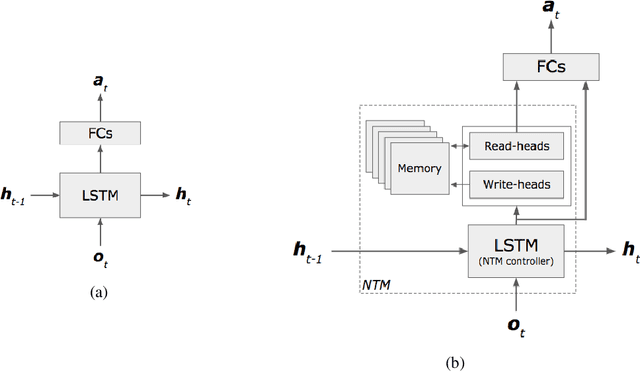
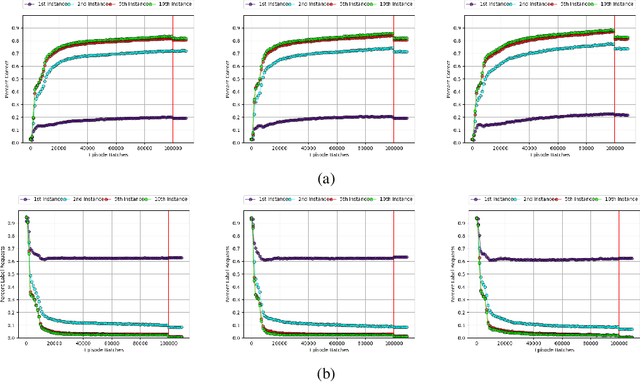
One of the major challenges in training deep architectures for predictive tasks is the scarcity and cost of labeled training data. Active Learning (AL) is one way of addressing this challenge. In stream-based AL, observations are continuously made available to the learner that have to decide whether to request a label or to make a prediction. The goal is to reduce the request rate while at the same time maximize prediction performance. In previous research, reinforcement learning has been used for learning the AL request/prediction strategy. In our work, we propose to equip a reinforcement learning process with memory augmented neural networks, to enhance the one-shot capabilities. Moreover, we introduce Class Margin Sampling (CMS) as an extension of the standard margin sampling to the reinforcement learning setting. This strategy aims to reduce training time and improve sample efficiency in the training process. We evaluate the proposed method on a classification task using empirical accuracy of label predictions and percentage of label requests. The results indicates that the proposed method, by making use of the memory augmented networks and CMS in the training process, outperforms existing baselines.