 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Gap Between Synthetic and Ground Truth Time Series Distributions via Neural Mapping
Jan 29, 2025
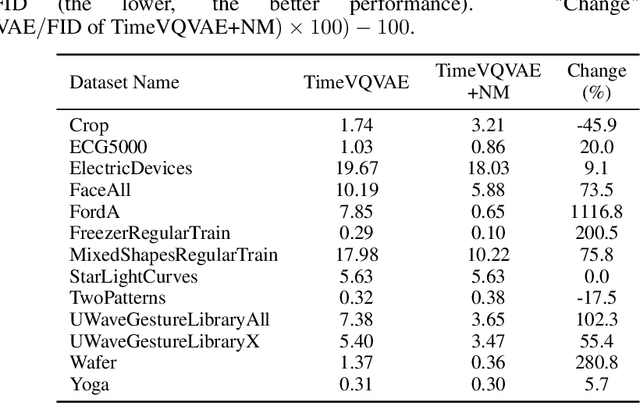
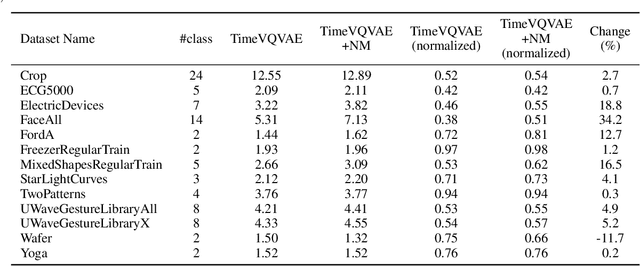
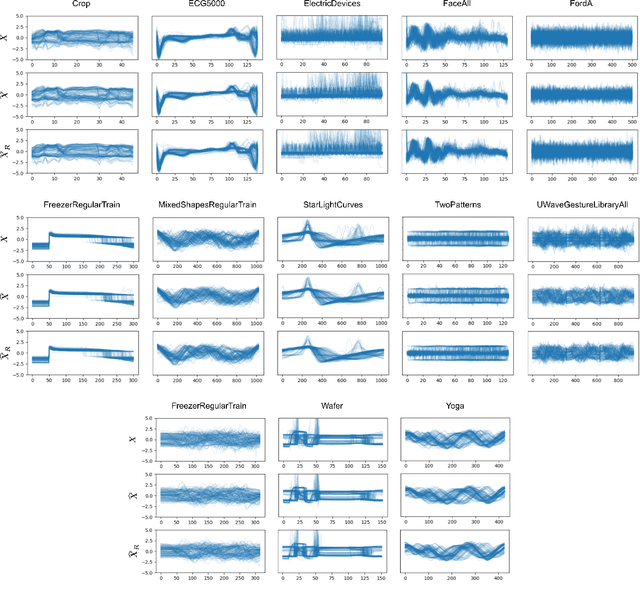
In this paper, we introduce Neural Mapper for Vector Quantized Time Series Generator (NM-VQTSG), a novel method aimed at addressing fidelity challenges in vector quantized (VQ) time series generation. VQ-based methods, such as TimeVQVAE, have demonstrated success in generating time series but are hindered by two critical bottlenecks: information loss during compression into discrete latent spaces and deviations in the learned prior distribution from the ground truth distribution. These challenges result in synthetic time series with compromised fidelity and distributional accuracy. To overcome these limitations, NM-VQTSG leverages a U-Net-based neural mapping model to bridge the distributional gap between synthetic and ground truth time series. To be more specific, the model refines synthetic data by addressing artifacts introduced during generation, effectively aligning the distributions of synthetic and real data. Importantly, NM-VQTSG can be used for synthetic time series generated by any VQ-based generative method. We evaluate NM-VQTSG across diverse datasets from the UCR Time Series Classification archive, demonstrating its capability to consistently enhance fidelity in both unconditional and conditional generation tasks. The improvements are evidenced by significant improvements in FID, IS, and conditional FID, additionally backed up by visual inspection in a data space and a latent space. Our findings establish NM-VQTSG as a new method to improve the quality of synthetic time series. Our implementation is available on \url{https://github.com/ML4ITS/TimeVQVAE}.
Blending Low and High-Level Semantics of Time Series for Better Masked Time Series Generation
Aug 29, 2024State-of-the-art approaches in time series generation (TSG), such as TimeVQVAE, utilize vector quantization-based tokenization to effectively model complex distributions of time series. These approaches first learn to transform time series into a sequence of discrete latent vectors, and then a prior model is learned to model the sequence. The discrete latent vectors, however, only capture low-level semantics (\textit{e.g.,} shapes). We hypothesize that higher-fidelity time series can be generated by training a prior model on more informative discrete latent vectors that contain both low and high-level semantics (\textit{e.g.,} characteristic dynamics). In this paper, we introduce a novel framework, termed NC-VQVAE, to integrate self-supervised learning into those TSG methods to derive a discrete latent space where low and high-level semantics are captured. Our experimental results demonstrate that NC-VQVAE results in a considerable improvement in the quality of synthetic samples.
Explainable Anomaly Detection using Masked Latent Generative Modeling
Nov 22, 2023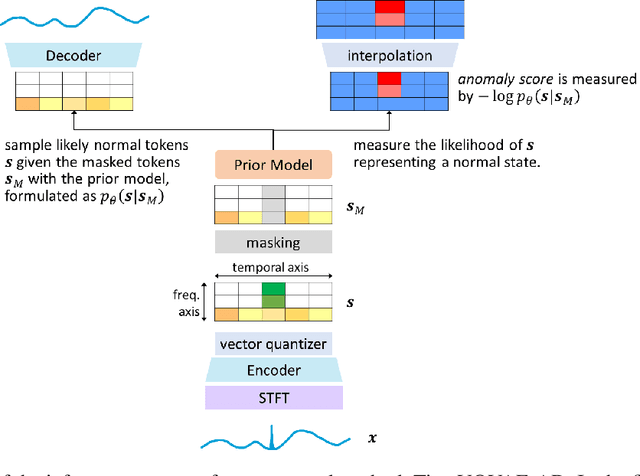
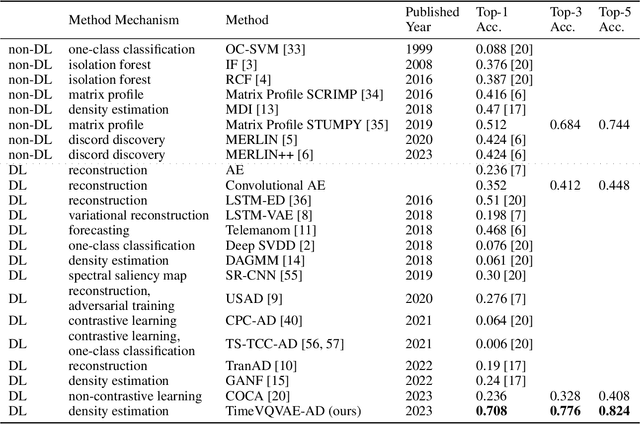
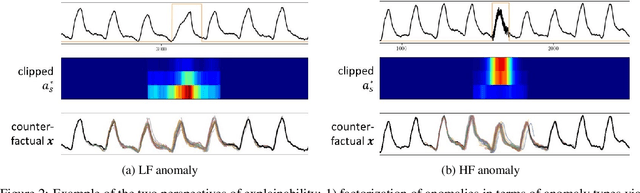
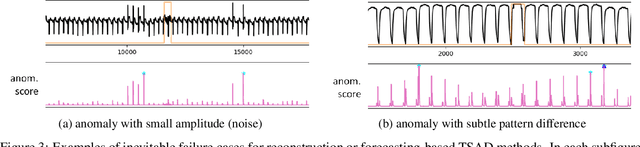
We present a novel time series anomaly detection method that achieves excellent detection accuracy while offering a superior level of explainability. Our proposed method, TimeVQVAE-AD, leverages masked generative modeling adapted from the cutting-edge time series generation method known as TimeVQVAE. The prior model is trained on the discrete latent space of a time-frequency domain. Notably, the dimensional semantics of the time-frequency domain are preserved in the latent space, enabling us to compute anomaly scores across different frequency bands, which provides a better insight into the detected anomalies. Additionally, the generative nature of the prior model allows for sampling likely normal states for detected anomalies, enhancing the explainability of the detected anomalies through counterfactuals. Our experimental evaluation on the UCR Time Series Anomaly archive demonstrates that TimeVQVAE-AD significantly surpasses the existing methods in terms of detection accuracy and explainability.
Latent Diffusion Model for Conditional Reservoir Facies Generation
Nov 03, 2023Creating accurate and geologically realistic reservoir facies based on limited measurements is crucial for field development and reservoir management, especially in the oil and gas sector. Traditional two-point geostatistics, while foundational, often struggle to capture complex geological patterns. Multi-point statistics offers more flexibility, but comes with its own challenges. With the rise of Generative Adversarial Networks (GANs) and their success in various fields, there has been a shift towards using them for facies generation. However, recent advances in the computer vision domain have shown the superiority of diffusion models over GANs. Motivated by this, a novel Latent Diffusion Model is proposed, which is specifically designed for conditional generation of reservoir facies. The proposed model produces high-fidelity facies realizations that rigorously preserve conditioning data. It significantly outperforms a GAN-based alternative.
Masked Generative Modeling with Enhanced Sampling Scheme
Sep 14, 2023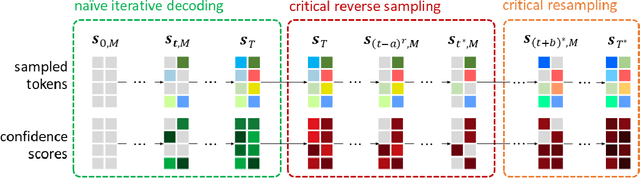

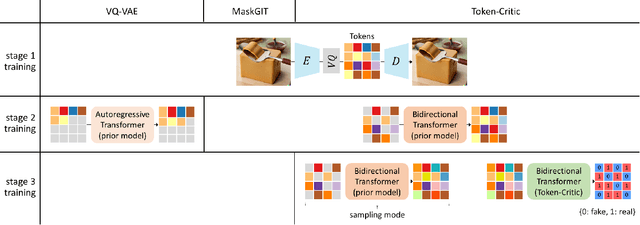
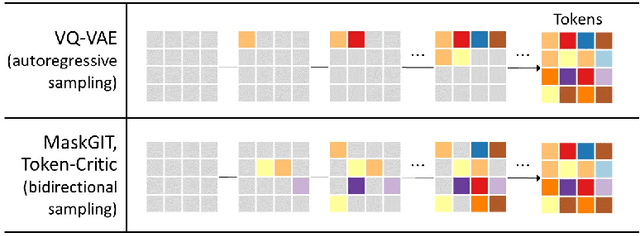
This paper presents a novel sampling scheme for masked non-autoregressive generative modeling. We identify the limitations of TimeVQVAE, MaskGIT, and Token-Critic in their sampling processes, and propose Enhanced Sampling Scheme (ESS) to overcome these limitations. ESS explicitly ensures both sample diversity and fidelity, and consists of three stages: Naive Iterative Decoding, Critical Reverse Sampling, and Critical Resampling. ESS starts by sampling a token set using the naive iterative decoding as proposed in MaskGIT, ensuring sample diversity. Then, the token set undergoes the critical reverse sampling, masking tokens leading to unrealistic samples. After that, critical resampling reconstructs masked tokens until the final sampling step is reached to ensure high fidelity. Critical resampling uses confidence scores obtained from a self-Token-Critic to better measure the realism of sampled tokens, while critical reverse sampling uses the structure of the quantized latent vector space to discover unrealistic sample paths. We demonstrate significant performance gains of ESS in both unconditional sampling and class-conditional sampling using all the 128 datasets in the UCR Time Series archive.
Vector Quantized Time Series Generation with a Bidirectional Prior Model
Mar 15, 2023Time series generation (TSG) studies have mainly focused on the use of Generative Adversarial Networks (GANs) combined with recurrent neural network (RNN) variants. However, the fundamental limitations and challenges of training GANs still remain. In addition, the RNN-family typically has difficulties with temporal consistency between distant timesteps. Motivated by the successes in the image generation (IMG) domain, we propose TimeVQVAE, the first work, to our knowledge, that uses vector quantization (VQ) techniques to address the TSG problem. Moreover, the priors of the discrete latent spaces are learned with bidirectional transformer models that can better capture global temporal consistency. We also propose VQ modeling in a time-frequency domain, separated into low-frequency (LF) and high-frequency (HF). This allows us to retain important characteristics of the time series and, in turn, generate new synthetic signals that are of better quality, with sharper changes in modularity, than its competing TSG methods. Our experimental evaluation is conducted on all datasets from the UCR archive, using well-established metrics in the IMG literature, such as Fr\'echet inception distance and inception scores. Our implementation on GitHub: \url{https://github.com/ML4ITS/TimeVQVAE}.
Persistence Initialization: A novel adaptation of the Transformer architecture for Time Series Forecasting
Aug 30, 2022
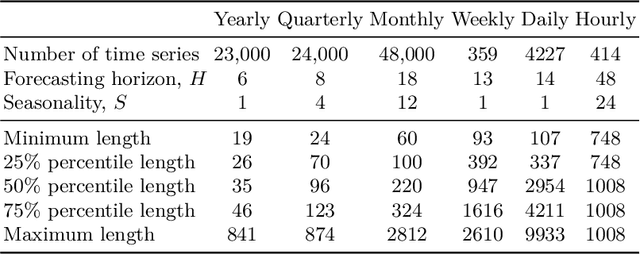
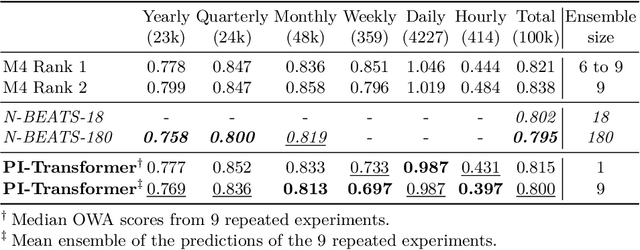
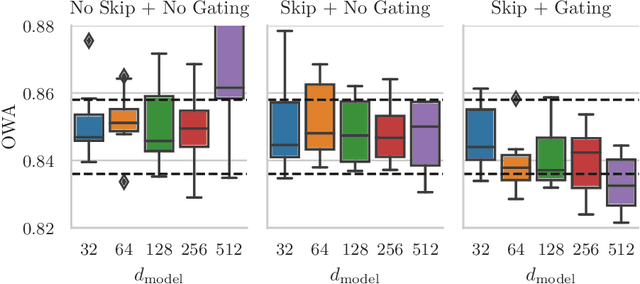
Time series forecasting is an important problem, with many real world applications. Ensembles of deep neural networks have recently achieved impressive forecasting accuracy, but such large ensembles are impractical in many real world settings. Transformer models been successfully applied to a diverse set of challenging problems. We propose a novel adaptation of the original Transformer architecture focusing on the task of time series forecasting, called Persistence Initialization. The model is initialized as a naive persistence model by using a multiplicative gating mechanism combined with a residual skip connection. We use a decoder Transformer with ReZero normalization and Rotary positional encodings, but the adaptation is applicable to any auto-regressive neural network model. We evaluate our proposed architecture on the challenging M4 dataset, achieving competitive performance compared to ensemble based methods. We also compare against existing recently proposed Transformer models for time series forecasting, showing superior performance on the M4 dataset. Extensive ablation studies show that Persistence Initialization leads to better performance and faster convergence. As the size of the model increases, only the models with our proposed adaptation gain in performance. We also perform an additional ablation study to determine the importance of the choice of normalization and positional encoding, and find both the use of Rotary encodings and ReZero normalization to be essential for good forecasting performance.
VNIbCReg: VICReg with Neighboring-Invariance and better-Covariance Evaluated on Non-stationary Seismic Signal Time Series
Apr 08, 2022

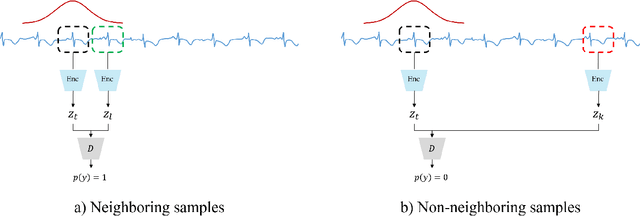
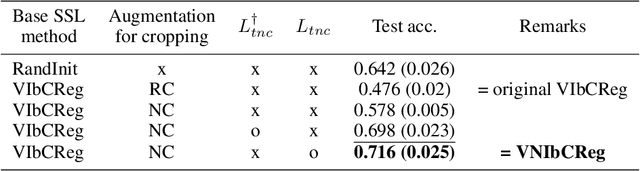
One of the latest self-supervised learning (SSL) methods, VICReg, showed a great performance both in the linear evaluation and the fine-tuning evaluation. However, VICReg is proposed in computer vision and it learns by pulling representations of random crops of an image while maintaining the representation space by the variance and covariance loss. However, VICReg would be ineffective on non-stationary time series where different parts/crops of input should be differently encoded to consider the non-stationarity. Another recent SSL proposal, Temporal Neighborhood Coding (TNC) is effective for encoding non-stationary time series. This study shows that a combination of a VICReg-style method and TNC is very effective for SSL on non-stationary time series, where a non-stationary seismic signal time series is used as an evaluation dataset.
VIbCReg: Variance-Invariance-better-Covariance Regularization for Self-Supervised Learning on Time Series
Sep 02, 2021

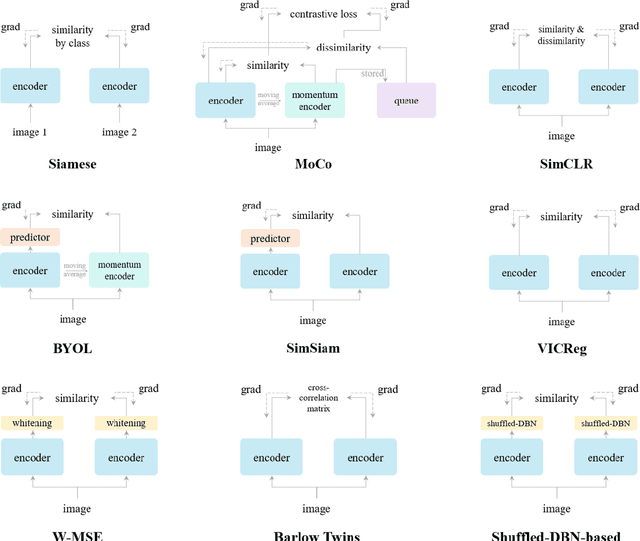

Self-supervised learning for image representations has recently had many breakthroughs with respect to linear evaluation and fine-tuning evaluation. These approaches rely on both cleverly crafted loss functions and training setups to avoid the feature collapse problem. In this paper, we improve on the recently proposed VICReg paper, which introduced a loss function that does not rely on specialized training loops to converge to useful representations. Our method improves on a covariance term proposed in VICReg, and in addition we augment the head of the architecture by an IterNorm layer that greatly accelerates convergence of the model. Our model achieves superior performance on linear evaluation and fine-tuning evaluation on a subset of the UCR time series classification archive and the PTB-XL ECG dataset.
Augmented Memory Networks for Streaming-Based Active One-Shot Learning
Sep 04, 2019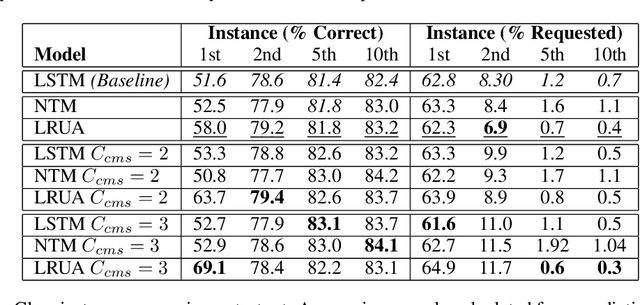
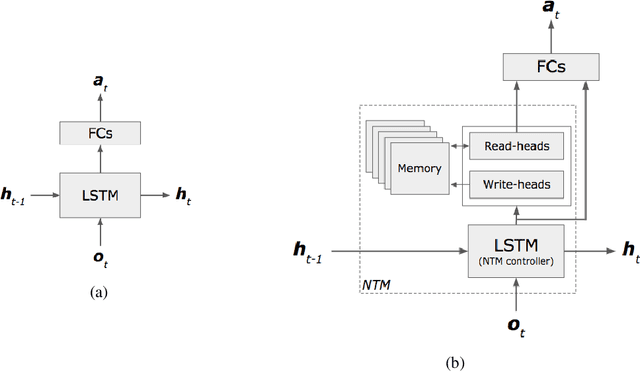
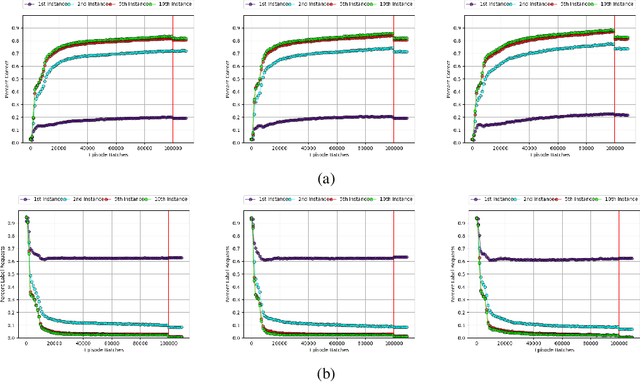
One of the major challenges in training deep architectures for predictive tasks is the scarcity and cost of labeled training data. Active Learning (AL) is one way of addressing this challenge. In stream-based AL, observations are continuously made available to the learner that have to decide whether to request a label or to make a prediction. The goal is to reduce the request rate while at the same time maximize prediction performance. In previous research, reinforcement learning has been used for learning the AL request/prediction strategy. In our work, we propose to equip a reinforcement learning process with memory augmented neural networks, to enhance the one-shot capabilities. Moreover, we introduce Class Margin Sampling (CMS) as an extension of the standard margin sampling to the reinforcement learning setting. This strategy aims to reduce training time and improve sample efficiency in the training process. We evaluate the proposed method on a classification task using empirical accuracy of label predictions and percentage of label requests. The results indicates that the proposed method, by making use of the memory augmented networks and CMS in the training process, outperforms existing baselines.