 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIbCReg: Variance-Invariance-better-Covariance Regularization for Self-Supervised Learning on Time Series
Paper and Code


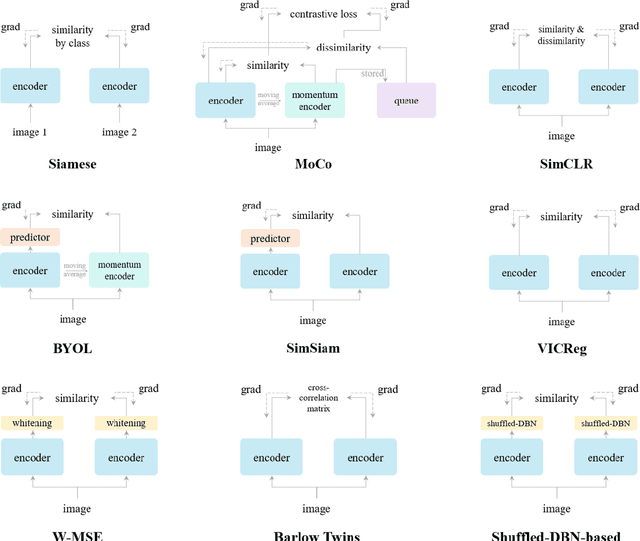

Self-supervised learning for image representations has recently had many breakthroughs with respect to linear evaluation and fine-tuning evaluation. These approaches rely on both cleverly crafted loss functions and training setups to avoid the feature collapse problem. In this paper, we improve on the recently proposed VICReg paper, which introduced a loss function that does not rely on specialized training loops to converge to useful representations. Our method improves on a covariance term proposed in VICReg, and in addition we augment the head of the architecture by an IterNorm layer that greatly accelerates convergence of the model. Our model achieves superior performance on linear evaluation and fine-tuning evaluation on a subset of the UCR time series classification archive and the PTB-XL ECG dataset.