 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistence Initialization: A novel adaptation of the Transformer architecture for Time Series Forecasting
Paper and Code

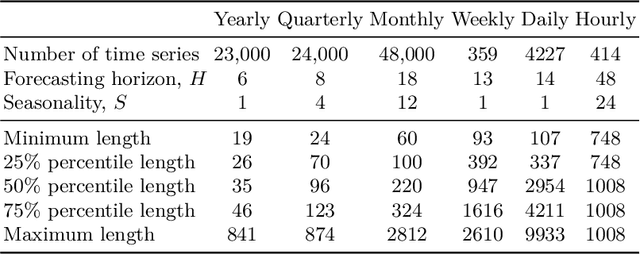
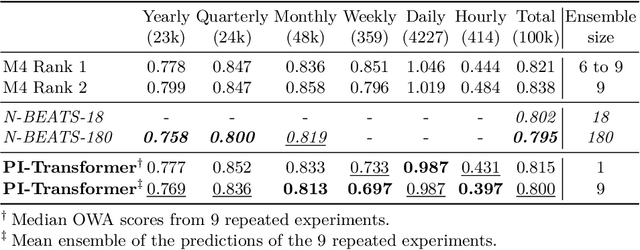
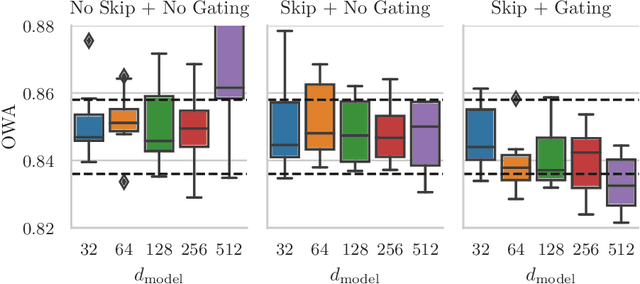
Time series forecasting is an important problem, with many real world applications. Ensembles of deep neural networks have recently achieved impressive forecasting accuracy, but such large ensembles are impractical in many real world settings. Transformer models been successfully applied to a diverse set of challenging problems. We propose a novel adaptation of the original Transformer architecture focusing on the task of time series forecasting, called Persistence Initialization. The model is initialized as a naive persistence model by using a multiplicative gating mechanism combined with a residual skip connection. We use a decoder Transformer with ReZero normalization and Rotary positional encodings, but the adaptation is applicable to any auto-regressive neural network model. We evaluate our proposed architecture on the challenging M4 dataset, achieving competitive performance compared to ensemble based methods. We also compare against existing recently proposed Transformer models for time series forecasting, showing superior performance on the M4 dataset. Extensive ablation studies show that Persistence Initialization leads to better performance and faster convergence. As the size of the model increases, only the models with our proposed adaptation gain in performance. We also perform an additional ablation study to determine the importance of the choice of normalization and positional encoding, and find both the use of Rotary encodings and ReZero normalization to be essential for good forecasting performance.