 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-mixed Sentiment and Hate-speech Prediction
May 21, 2024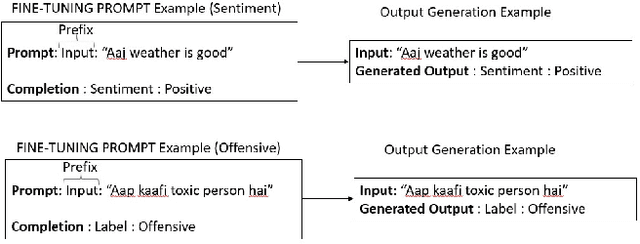



Code-mixed discourse combines multiple languages in a single text. It is commonly used in informal discourse in countries with several official languages, but also in many other countries in combination with English or neighboring languages. As recently large language models have dominated most natural language processing tasks, we investigated their performance in code-mixed settings for relevant tasks. We first created four new bilingual pre-trained masked language models for English-Hindi and English-Slovene languages, specifically aimed to support informal language. Then we performed an evaluation of monolingual, bilingual, few-lingual, and massively multilingual models on several languages, using two tasks that frequently contain code-mixed text, in particular, sentiment analysis and offensive language detection in social media texts. The results show that the most successful classifiers are fine-tuned bilingual models and multilingual models, specialized for social media texts, followed by non-specialized massively multilingual and monolingual models, while huge generative models are not competitive. For our affective problems, the models mostly perform slightly better on code-mixed data compared to non-code-mixed data.
A Deep Network Model for Paraphrase Detection in Short Text Messages
Dec 07, 2017
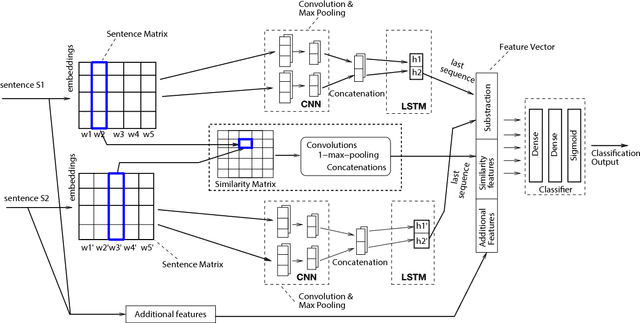
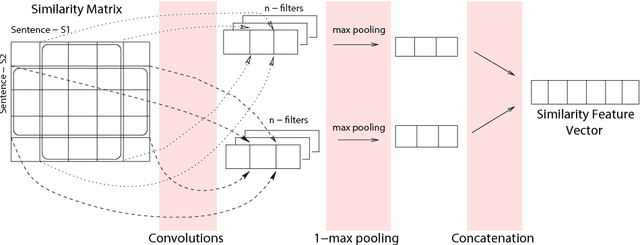
This paper is concerned with paraphrase detection. The ability to detect similar sentences written in natural language is crucial for several applications, such as text mining, text summarization, plagiarism detection, authorship authentication and question answering. Given two sentences, the objective is to detect whether they are semantically identical. An important insight from this work is that existing paraphrase systems perform well when applied on clean texts, but they do not necessarily deliver good performance against noisy texts. Challenges with paraphrase detection on user generated short texts, such as Twitter, include language irregularity and noise. To cope with these challenges, we propose a novel deep neural network-based approach that relies on coarse-grained sentence modeling using a convolutional neural network and a long short-term memory model, combined with a specific fine-grained word-level similarity matching model. Our experimental results show that the proposed approach outperforms existing state-of-the-art approaches on user-generated noisy social media data, such as Twitter texts, and achieves highly competitive performance on a cleaner corpus.
Icon Based Information Retrieval and Disease Identification in Agriculture
Apr 07, 2014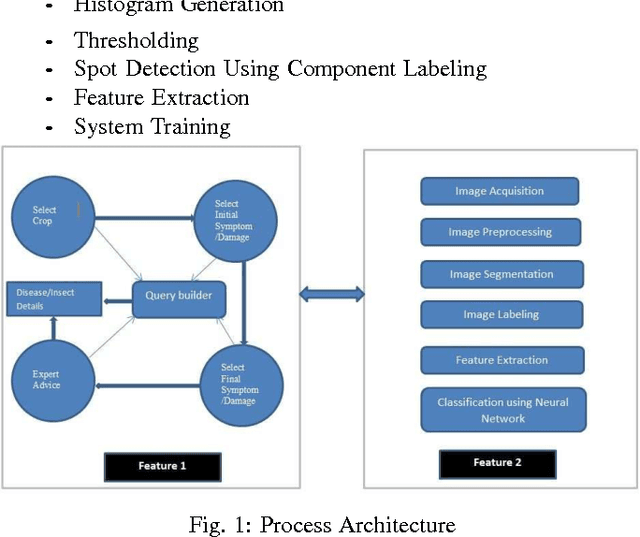



Recent developments in the ICT industry in past few decades has enabled the quick and easy access to the information available on the internet. But, digital literacy is the pre-requisite for its use. The main purpose of this paper is to provide an interface for digitally illiterate users, especially farmers to efficiently and effectively retrieve information through Internet. In addition, to enable the farmers to identify the disease in their crop, its cause and symptoms using digital image processing and pattern recognition instantly without waiting for an expert to visit the farms and identify the disease.
* Iconic Interface, Image Processing, Pattern Recognition, Data Mining, Information Retrieval