 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-mixed Sentiment and Hate-speech Prediction
Paper and Code
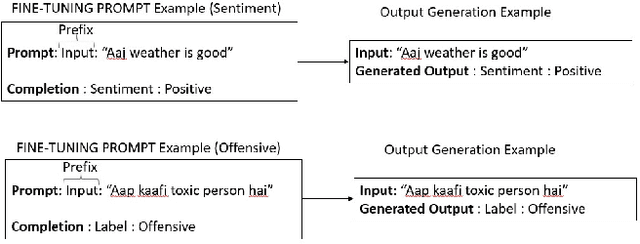



Code-mixed discourse combines multiple languages in a single text. It is commonly used in informal discourse in countries with several official languages, but also in many other countries in combination with English or neighboring languages. As recently large language models have dominated most natural language processing tasks, we investigated their performance in code-mixed settings for relevant tasks. We first created four new bilingual pre-trained masked language models for English-Hindi and English-Slovene languages, specifically aimed to support informal language. Then we performed an evaluation of monolingual, bilingual, few-lingual, and massively multilingual models on several languages, using two tasks that frequently contain code-mixed text, in particular, sentiment analysis and offensive language detection in social media texts. The results show that the most successful classifiers are fine-tuned bilingual models and multilingual models, specialized for social media texts, followed by non-specialized massively multilingual and monolingual models, while huge generative models are not competitive. For our affective problems, the models mostly perform slightly better on code-mixed data compared to non-code-mixed data.