 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLawSum: A weakly supervised approach for Indian Legal Document Summarization
Oct 05, 2021


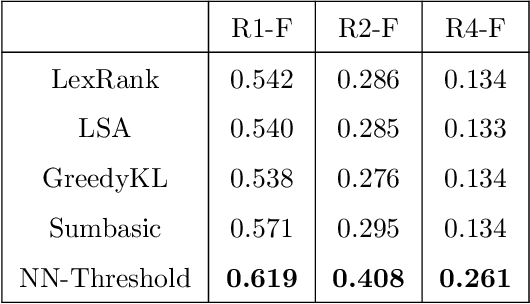
Unlike the courts in western countries, public records of Indian judiciary are completely unstructured and noisy. No large scale publicly available annotated datasets of Indian legal documents exist till date. This limits the scope for legal analytics research. In this work, we propose a new dataset consisting of over 10,000 judgements delivered by the supreme court of India and their corresponding hand written summaries. The proposed dataset is pre-processed by normalising common legal abbreviations, handling spelling variations in named entities, handling bad punctuations and accurate sentence tokenization. Each sentence is tagged with their rhetorical roles. We also annotate each judgement with several attributes like date, names of the plaintiffs, defendants and the people representing them, judges who delivered the judgement, acts/statutes that are cited and the most common citations used to refer the judgement. Further, we propose an automatic labelling technique for identifying sentences which have summary worthy information. We demonstrate that this auto labeled data can be used effectively to train a weakly supervised sentence extractor with high accuracy. Some possible applications of this dataset besides legal document summarization can be in retrieval, citation analysis and prediction of decisions by a particular judge.
Icon Based Information Retrieval and Disease Identification in Agriculture
Apr 07, 2014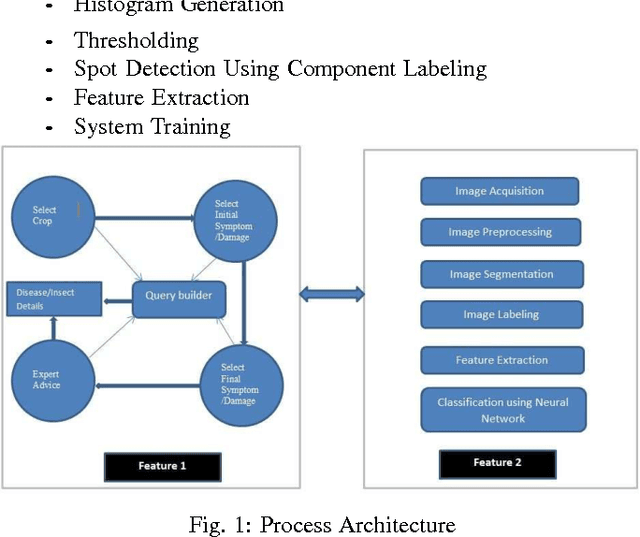



Recent developments in the ICT industry in past few decades has enabled the quick and easy access to the information available on the internet. But, digital literacy is the pre-requisite for its use. The main purpose of this paper is to provide an interface for digitally illiterate users, especially farmers to efficiently and effectively retrieve information through Internet. In addition, to enable the farmers to identify the disease in their crop, its cause and symptoms using digital image processing and pattern recognition instantly without waiting for an expert to visit the farms and identify the disease.
* Iconic Interface, Image Processing, Pattern Recognition, Data Mining, Information Retrieval