 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVineSynth: A Truncated C-Vine Copula Generator of Synthetic Tabular Data to Balance Privacy and Utility
Mar 20, 2025



We propose TVineSynth, a vine copula based synthetic tabular data generator, which is designed to balance privacy and utility, using the vine tree structure and its truncation to do the trade-off. Contrary to synthetic data generators that achieve DP by globally adding noise, TVineSynth performs a controlled approximation of the estimated data generating distribution, so that it does not suffer from poor utility of the resulting synthetic data for downstream prediction tasks. TVineSynth introduces a targeted bias into the vine copula model that, combined with the specific tree structure of the vine, causes the model to zero out privacy-leaking dependencies while relying on those that are beneficial for utility. Privacy is here measured with membership (MIA) and attribute inference attacks (AIA). Further, we theoretically justify how the construction of TVineSynth ensures AIA privacy under a natural privacy measure for continuous sensitive attributes. When compared to competitor models, with and without DP, on simulated and on real-world data, TVineSynth achieves a superior privacy-utility balance.
Prediction of cancer dynamics under treatment using Bayesian neural networks: A simulated study
May 23, 2024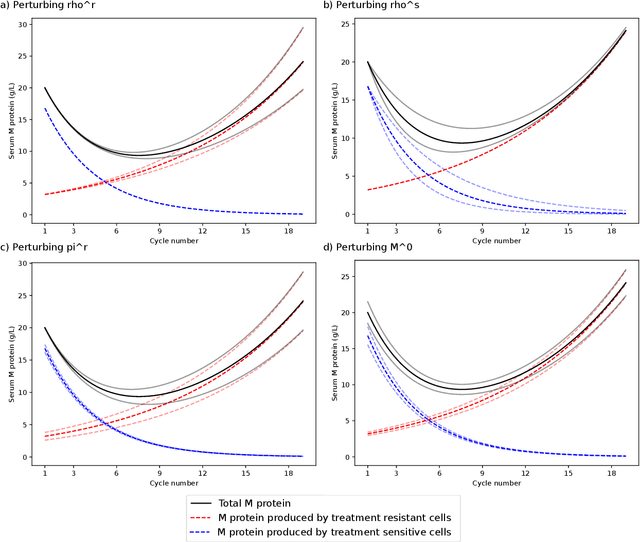
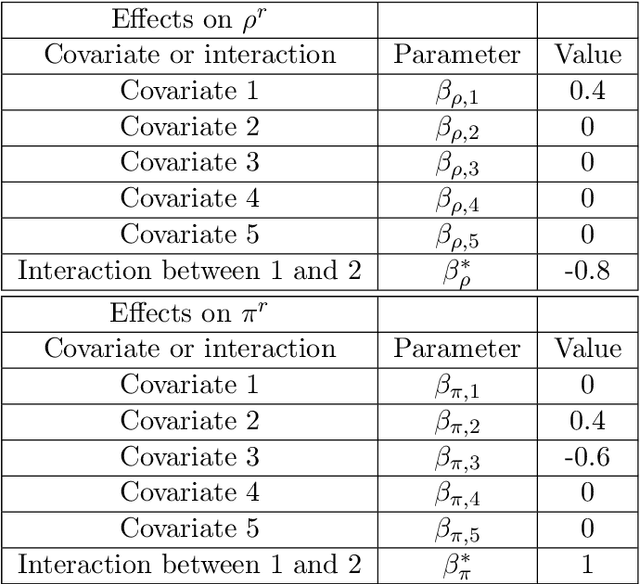
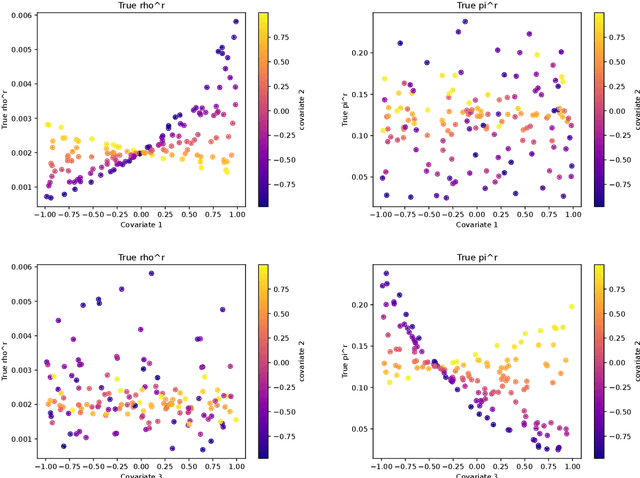
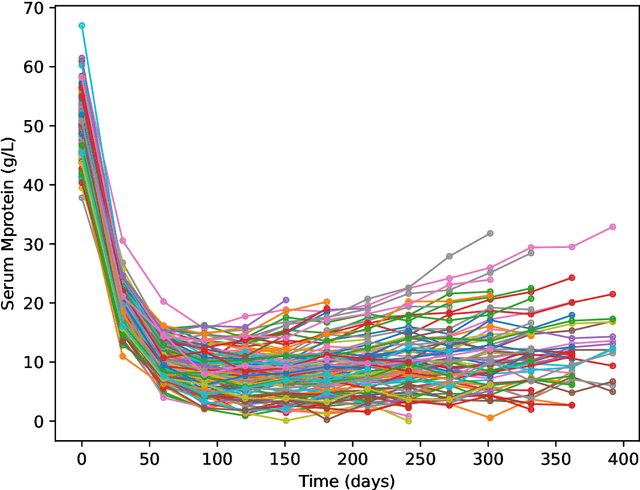
Predicting cancer dynamics under treatment is challenging due to high inter-patient heterogeneity, lack of predictive biomarkers, and sparse and noisy longitudinal data. Mathematical models can summarize cancer dynamics by a few interpretable parameters per patient. Machine learning methods can then be trained to predict the model parameters from baseline covariates, but do not account for uncertainty in the parameter estimates. Instead, hierarchical Bayesian modeling can model the relationship between baseline covariates to longitudinal measurements via mechanistic parameters while accounting for uncertainty in every part of the model. The mapping from baseline covariates to model parameters can be modeled in several ways. A linear mapping simplifies inference but fails to capture nonlinear covariate effects and scale poorly for interaction modeling when the number of covariates is large. In contrast, Bayesian neural networks can potentially discover interactions between covariates automatically, but at a substantial cost in computational complexity. In this work, we develop a hierarchical Bayesian model of subpopulation dynamics that uses baseline covariate information to predict cancer dynamics under treatment, inspired by cancer dynamics in multiple myeloma (MM), where serum M protein is a well-known proxy of tumor burden. As a working example, we apply the model to a simulated dataset and compare its ability to predict M protein trajectories to a model with linear covariate effects. Our results show that the Bayesian neural network covariate effect model predicts cancer dynamics more accurately than a linear covariate effect model when covariate interactions are present. The framework can also be applied to other types of cancer or other time series prediction problems that can be described with a parametric model.
FINN.no Slates Dataset: A new Sequential Dataset Logging Interactions, allViewed Items and Click Responses/No-Click for Recommender Systems Research
Nov 05, 2021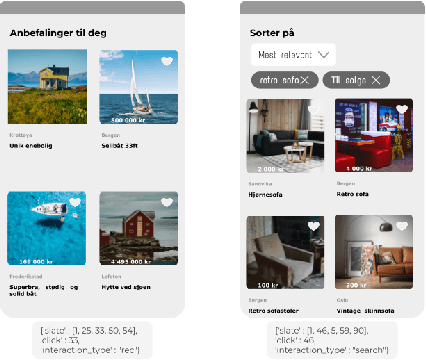

We present a novel recommender systems dataset that records the sequential interactions between users and an online marketplace. The users are sequentially presented with both recommendations and search results in the form of ranked lists of items, called slates, from the marketplace. The dataset includes the presented slates at each round, whether the user clicked on any of these items and which item the user clicked on. Although the usage of exposure data in recommender systems is growing, to our knowledge there is no open large-scale recommender systems dataset that includes the slates of items presented to the users at each interaction. As a result, most articles on recommender systems do not utilize this exposure information. Instead, the proposed models only depend on the user's click responses, and assume that the user is exposed to all the items in the item universe at each step, often called uniform candidate sampling. This is an incomplete assumption, as it takes into account items the user might not have been exposed to. This way items might be incorrectly considered as not of interest to the user. Taking into account the actually shown slates allows the models to use a more natural likelihood, based on the click probability given the exposure set of items, as is prevalent in the bandit and reinforcement learning literature. \cite{Eide2021DynamicSampling} shows that likelihoods based on uniform candidate sampling (and similar assumptions) are implicitly assuming that the platform only shows the most relevant items to the user. This causes the recommender system to implicitly reinforce feedback loops and to be biased towards previously exposed items to the user.
Dynamic Slate Recommendation with Gated Recurrent Units and Thompson Sampling
Apr 30, 2021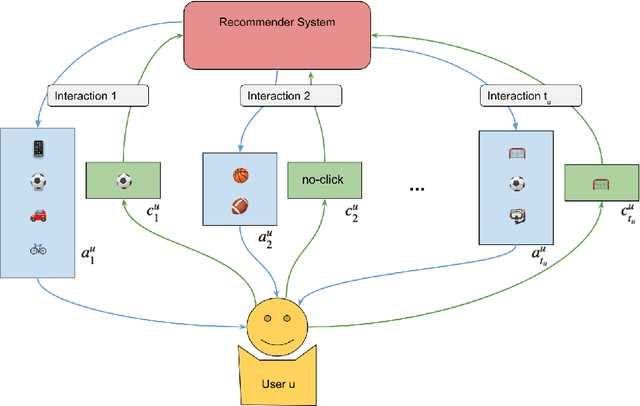

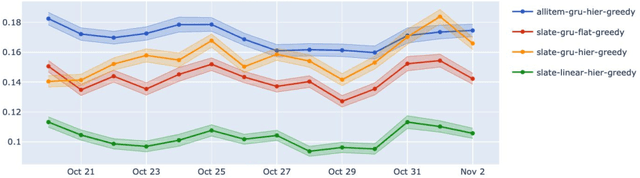

We consider the problem of recommending relevant content to users of an internet platform in the form of lists of items, called slates. We introduce a variational Bayesian Recurrent Neural Net recommender system that acts on time series of interactions between the internet platform and the user, and which scales to real world industrial situations. The recommender system is tested both online on real users, and on an offline dataset collected from a Norwegian web-based marketplace, FINN.no, that is made public for research. This is one of the first publicly available datasets which includes all the slates that are presented to users as well as which items (if any) in the slates were clicked on. Such a data set allows us to move beyond the common assumption that implicitly assumes that users are considering all possible items at each interaction. Instead we build our likelihood using the items that are actually in the slate, and evaluate the strengths and weaknesses of both approaches theoretically and in experiments. We also introduce a hierarchical prior for the item parameters based on group memberships. Both item parameters and user preferences are learned probabilistically. Furthermore, we combine our model with bandit strategies to ensure learning, and introduce `in-slate Thompson Sampling' which makes use of the slates to maximise explorative opportunities. We show experimentally that explorative recommender strategies perform on par or above their greedy counterparts. Even without making use of exploration to learn more effectively, click rates increase simply because of improved diversity in the recommended slates.