 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTVineSynth: A Truncated C-Vine Copula Generator of Synthetic Tabular Data to Balance Privacy and Utility
Mar 20, 2025



We propose TVineSynth, a vine copula based synthetic tabular data generator, which is designed to balance privacy and utility, using the vine tree structure and its truncation to do the trade-off. Contrary to synthetic data generators that achieve DP by globally adding noise, TVineSynth performs a controlled approximation of the estimated data generating distribution, so that it does not suffer from poor utility of the resulting synthetic data for downstream prediction tasks. TVineSynth introduces a targeted bias into the vine copula model that, combined with the specific tree structure of the vine, causes the model to zero out privacy-leaking dependencies while relying on those that are beneficial for utility. Privacy is here measured with membership (MIA) and attribute inference attacks (AIA). Further, we theoretically justify how the construction of TVineSynth ensures AIA privacy under a natural privacy measure for continuous sensitive attributes. When compared to competitor models, with and without DP, on simulated and on real-world data, TVineSynth achieves a superior privacy-utility balance.
Assessing univariate and bivariate risks of late-frost and drought using vine copulas: A historical study for Bavaria
Oct 16, 2023In light of climate change's impacts on forests, including extreme drought and late-frost, leading to vitality decline and regional forest die-back, we assess univariate drought and late-frost risks and perform a joint risk analysis in Bavaria, Germany, from 1952 to 2020. Utilizing a vast dataset with 26 bioclimatic and topographic variables, we employ vine copula models due to the data's non-Gaussian and asymmetric dependencies. We use D-vine regression for univariate and Y-vine regression for bivariate analysis, and propose corresponding univariate and bivariate conditional probability risk measures. We identify "at-risk" regions, emphasizing the need for forest adaptation due to climate change.
Bivariate vine copula based quantile regression
May 05, 2022

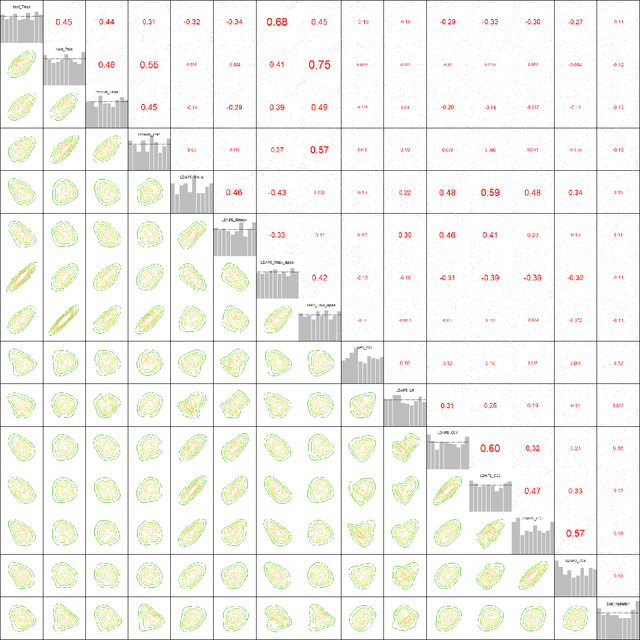

The statistical analysis of univariate quantiles is a well developed research topic. However, there is a profound need for research in multivariate quantiles. We tackle the topic of bivariate quantiles and bivariate quantile regression using vine copulas. They are graph theoretical models identified by a sequence of linked trees, which allow for separate modelling of marginal distributions and the dependence structure. We introduce a novel graph structure model (given by a tree sequence) specifically designed for a symmetric treatment of two responses in a predictive regression setting. We establish computational tractability of the model and a straight forward way of obtaining different conditional distributions. Using vine copulas the typical shortfalls of regression, as the need for transformations or interactions of predictors, collinearity or quantile crossings are avoided. We illustrate the copula based bivariate quantiles for different copula distributions and provide a data set example. Further, the data example emphasizes the benefits of the joint bivariate response modelling in contrast to two separate univariate regressions or by assuming conditional independence, for bivariate response data set in the presence of conditional dependence.
Vine copula mixture models and clustering for non-Gaussian data
Feb 05, 2021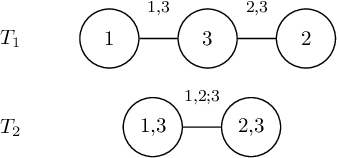

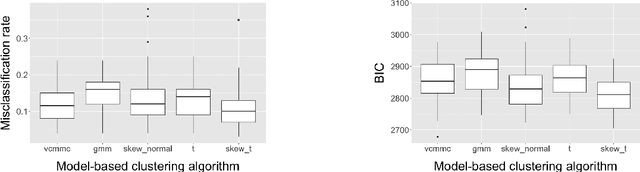

The majority of finite mixture models suffer from not allowing asymmetric tail dependencies within components and not capturing non-elliptical clusters in clustering applications. Since vine copulas are very flexible in capturing these types of dependencies, we propose a novel vine copula mixture model for continuous data. We discuss the model selection and parameter estimation problems and further formulate a new model-based clustering algorithm. The use of vine copulas in clustering allows for a range of shapes and dependency structures for the clusters. Our simulation experiments illustrate a significant gain in clustering accuracy when notably asymmetric tail dependencies or/and non-Gaussian margins within the components exist. The analysis of real data sets accompanies the proposed method. We show that the model-based clustering algorithm with vine copula mixture models outperforms the other model-based clustering techniques, especially for the non-Gaussian multivariate data.
Dependence Modeling in Ultra High Dimensions with Vine Copulas and the Graphical Lasso
Sep 15, 2017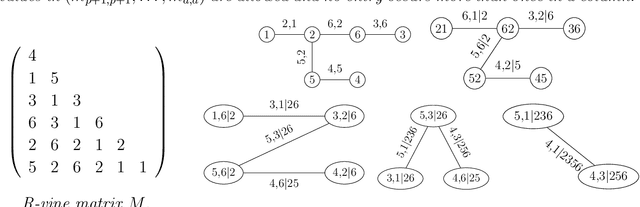

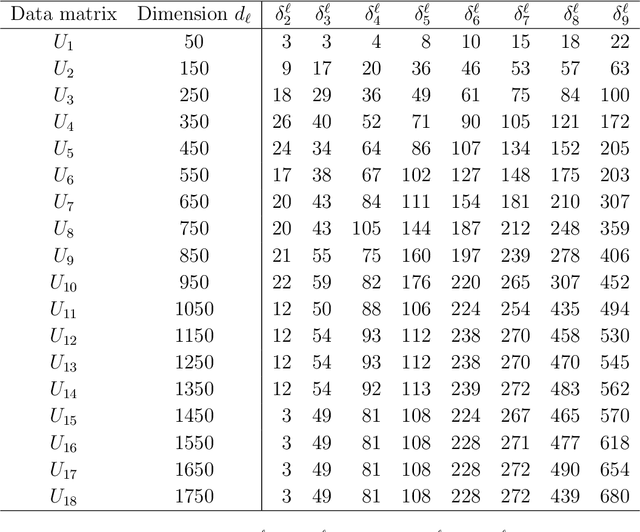
To model high dimensional data, Gaussian methods are widely used since they remain tractable and yield parsimonious models by imposing strong assumptions on the data. Vine copulas are more flexible by combining arbitrary marginal distributions and (conditional) bivariate copulas. Yet, this adaptability is accompanied by sharply increasing computational effort as the dimension increases. The approach proposed in this paper overcomes this burden and makes the first step into ultra high dimensional non-Gaussian dependence modeling by using a divide-and-conquer approach. First, we apply Gaussian methods to split datasets into feasibly small subsets and second, apply parsimonious and flexible vine copulas thereon. Finally, we reconcile them into one joint model. We provide numerical results demonstrating the feasibility of our approach in moderate dimensions and showcase its ability to estimate ultra high dimensional non-Gaussian dependence models in thousands of dimensions.