 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Intelligence in Africa: a survey
Feb 03, 2024In the last 5 years, the availability of large audio datasets in African countries has opened unlimited opportunities to build machine intelligence (MI) technologies that are closer to the people and speak, learn, understand, and do businesses in local languages, including for those who cannot read and write. Unfortunately, these audio datasets are not fully exploited by current MI tools, leaving several Africans out of MI business opportunities. Additionally, many state-of-the-art MI models are not culture-aware, and the ethics of their adoption indexes are questionable. The lack thereof is a major drawback in many applications in Africa. This paper summarizes recent developments in machine intelligence in Africa from a multi-layer multiscale and culture-aware ethics perspective, showcasing MI use cases in 54 African countries through 400 articles on MI research, industry, government actions, as well as uses in art, music, the informal economy, and small businesses in Africa. The survey also opens discussions on the reliability of MI rankings and indexes in the African continent as well as algorithmic definitions of unclear terms used in MI.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023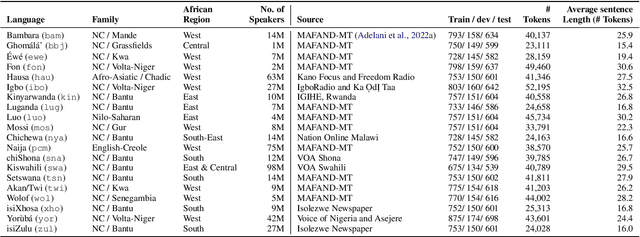
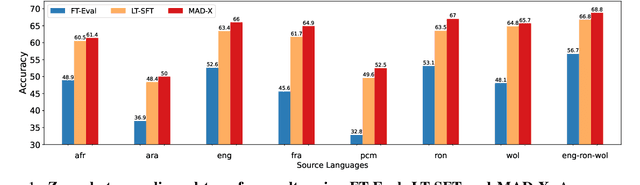
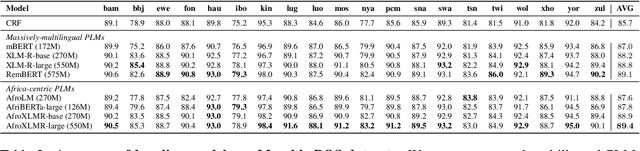
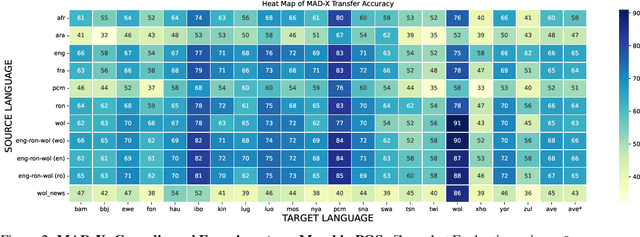
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022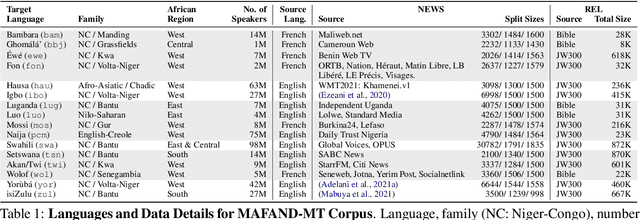
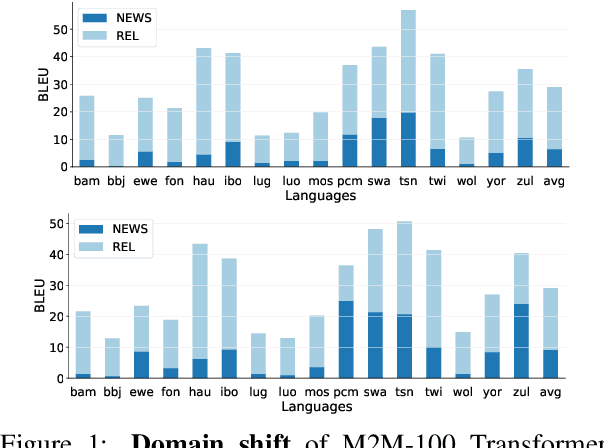

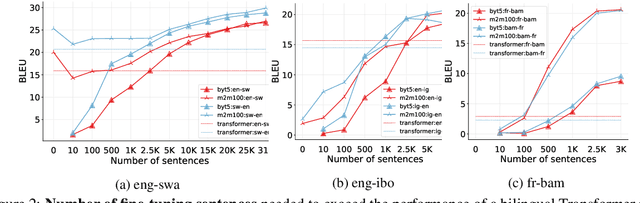
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
Domain-specific MT for Low-resource Languages: The case of Bambara-French
Mar 31, 2021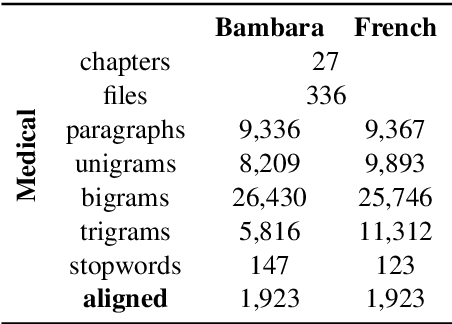
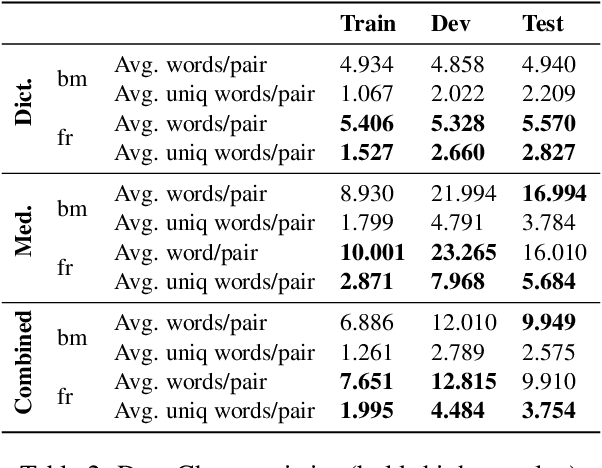
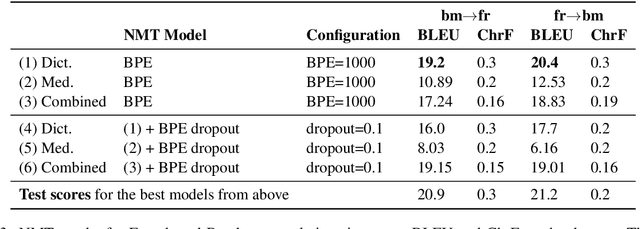
Translating to and from low-resource languages is a challenge for machine translation (MT) systems due to a lack of parallel data. In this paper we address the issue of domain-specific MT for Bambara, an under-resourced Mande language spoken in Mali. We present the first domain-specific parallel dataset for MT of Bambara into and from French. We discuss challenges in working with small quantities of domain-specific data for a low-resource language and we present the results of machine learning experiments on this data.
Neural Machine Translation for Extremely Low-Resource African Languages: A Case Study on Bambara
Nov 10, 2020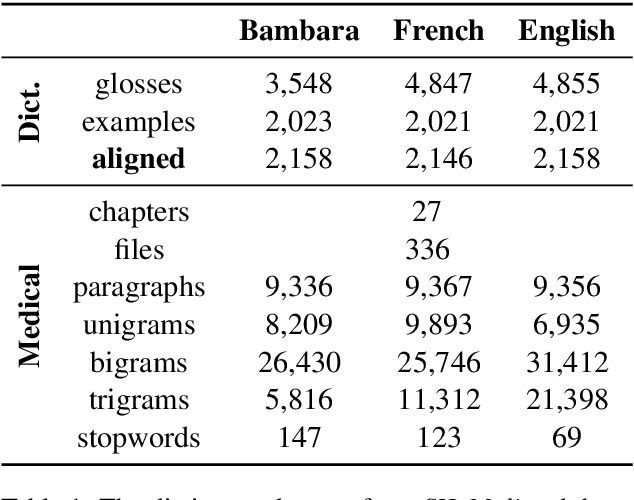
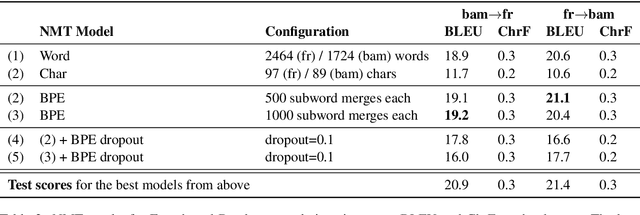
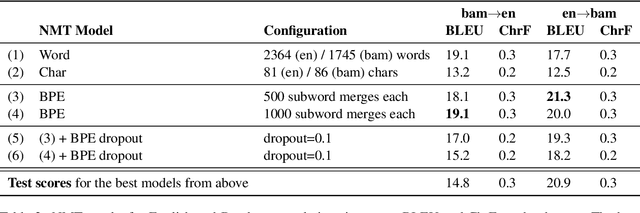
Low-resource languages present unique challenges to (neural) machine translation. We discuss the case of Bambara, a Mande language for which training data is scarce and requires significant amounts of pre-processing. More than the linguistic situation of Bambara itself, the socio-cultural context within which Bambara speakers live poses challenges for automated processing of this language. In this paper, we present the first parallel data set for machine translation of Bambara into and from English and French and the first benchmark results on machine translation to and from Bambara. We discuss challenges in working with low-resource languages and propose strategies to cope with data scarcity in low-resource machine translation (MT).