Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Machine Translation for Extremely Low-Resource African Languages: A Case Study on Bambara
Paper and Code
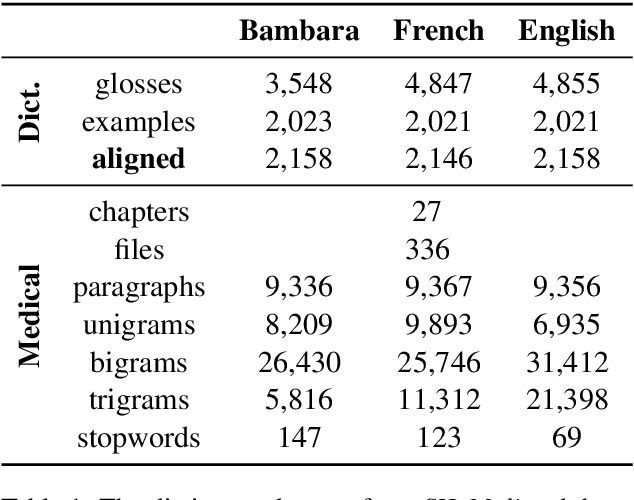
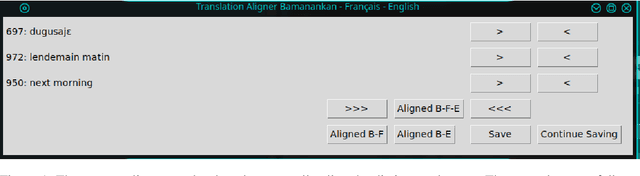
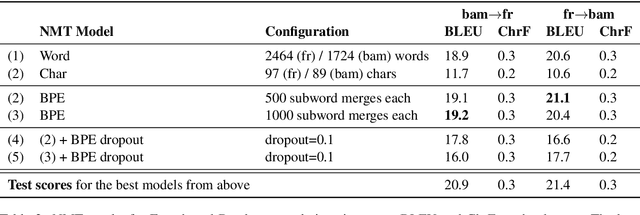
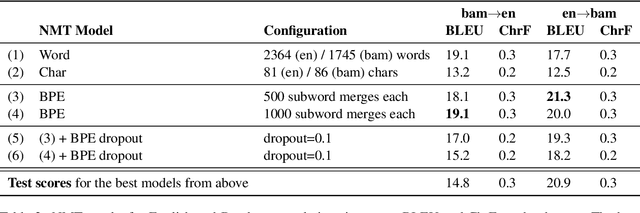
Low-resource languages present unique challenges to (neural) machine translation. We discuss the case of Bambara, a Mande language for which training data is scarce and requires significant amounts of pre-processing. More than the linguistic situation of Bambara itself, the socio-cultural context within which Bambara speakers live poses challenges for automated processing of this language. In this paper, we present the first parallel data set for machine translation of Bambara into and from English and French and the first benchmark results on machine translation to and from Bambara. We discuss challenges in working with low-resource languages and propose strategies to cope with data scarcity in low-resource machine translation (MT).
View paper on