 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSL-MT: Linguistically Informed Negative Samples for Efficient Machine Translation in Low-Resource Languages
Nov 12, 2025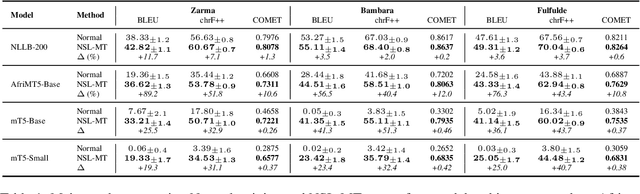
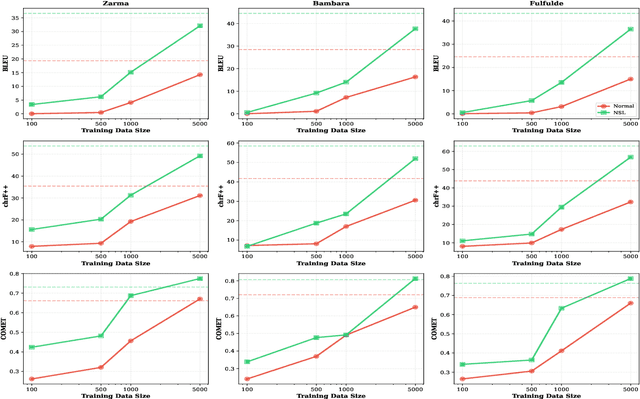

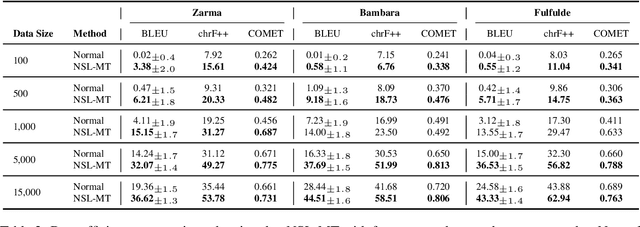
We introduce Negative Space Learning MT (NSL-MT), a training method that teaches models what not to generate by encoding linguistic constraints as severity-weighted penalties in the loss function. NSL-MT increases limited parallel data with synthetically generated violations of target language grammar, explicitly penalizing the model when it assigns high probability to these linguistically invalid outputs. We demonstrate that NSL-MT delivers improvements across all architectures: 3-12\% BLEU gains for well-performing models and 56-89\% gains for models lacking descent initial support. Furthermore, NSL-MT provides a 5x data efficiency multiplier -- training with 1,000 examples matches or exceeds normal training with 5,000 examples. Thus, NSL-MT provides a data-efficient alternative training method for settings where there is limited annotated parallel corporas.
How Many Ratings per Item are Necessary for Reliable Significance Testing?
Dec 04, 2024Most approaches to machine learning evaluation assume that machine and human responses are repeatable enough to be measured against data with unitary, authoritative, "gold standard" responses, via simple metrics such as accuracy, precision, and recall that assume scores are independent given the test item. However, AI models have multiple sources of stochasticity and the human raters who create gold standards tend to disagree with each other, often in meaningful ways, hence a single output response per input item may not provide enough information. We introduce methods for determining whether an (existing or planned) evaluation dataset has enough responses per item to reliably compare the performance of one model to another. We apply our methods to several of very few extant gold standard test sets with multiple disaggregated responses per item and show that there are usually not enough responses per item to reliably compare the performance of one model against another. Our methods also allow us to estimate the number of responses per item for hypothetical datasets with similar response distributions to the existing datasets we study. When two models are very far apart in their predictive performance, fewer raters are needed to confidently compare them, as expected. However, as the models draw closer, we find that a larger number of raters than are currently typical in annotation collection are needed to ensure that the power analysis correctly reflects the difference in performance.
Grammatical Error Correction for Low-Resource Languages: The Case of Zarma
Oct 20, 2024


Grammatical error correction (GEC) is important for improving written materials for low-resource languages like Zarma -- spoken by over 5 million people in West Africa. Yet it remains a challenging problem. This study compares rule-based methods, machine translation (MT) models, and large language models (LLMs) for GEC in Zarma. We evaluate each approach's effectiveness on our manually-built dataset of over 250,000 examples using synthetic and human-annotated data. Our experiments show that the MT-based approach using the M2M100 model outperforms others, achieving a detection rate of 95.82% and a suggestion accuracy of 78.90% in automatic evaluations, and scoring 3.0 out of 5.0 in logical/grammar error correction during MEs by native speakers. The rule-based method achieved perfect detection (100%) and high suggestion accuracy (96.27%) for spelling corrections but struggled with context-level errors. LLMs like MT5-small showed moderate performance with a detection rate of 90.62% and a suggestion accuracy of 57.15%. Our work highlights the potential of MT models to enhance GEC in low-resource languages, paving the way for more inclusive NLP tools.
Feriji: A French-Zarma Parallel Corpus, Glossary & Translator
Jun 09, 2024



Machine translation (MT) is a rapidly expanding field that has experienced significant advancements in recent years with the development of models capable of translating multiple languages with remarkable accuracy. However, the representation of African languages in this field still needs to improve due to linguistic complexities and limited resources. This applies to the Zarma language, a dialect of Songhay (of the Nilo-Saharan language family) spoken by over 5 million people across Niger and neighboring countries \cite{lewis2016ethnologue}. This paper introduces Feriji, the first robust French-Zarma parallel corpus and glossary designed for MT. The corpus, containing 61,085 sentences in Zarma and 42,789 in French, and a glossary of 4,062 words represent a significant step in addressing the need for more resources for Zarma. We fine-tune three large language models on our dataset, obtaining a BLEU score of 30.06 on the best-performing model. We further evaluate the models on human judgments of fluency, comprehension, and readability and the importance and impact of the corpus and models. Our contributions help to bridge a significant language gap and promote an essential and overlooked indigenous African language.
A Framework to Assess agreement Among Diverse Rater Groups
Nov 09, 2023Recent advancements in conversational AI have created an urgent need for safety guardrails that prevent users from being exposed to offensive and dangerous content. Much of this work relies on human ratings and feedback, but does not account for the fact that perceptions of offense and safety are inherently subjective and that there may be systematic disagreements between raters that align with their socio-demographic identities. Instead, current machine learning approaches largely ignore rater subjectivity and use gold standards that obscure disagreements (e.g., through majority voting). In order to better understand the socio-cultural leanings of such tasks, we propose a comprehensive disagreement analysis framework to measure systematic diversity in perspectives among different rater subgroups. We then demonstrate its utility by applying this framework to a dataset of human-chatbot conversations rated by a demographically diverse pool of raters. Our analysis reveals specific rater groups that have more diverse perspectives than the rest, and informs demographic axes that are crucial to consider for safety annotations.
Neural Machine Translation for Extremely Low-Resource African Languages: A Case Study on Bambara
Nov 10, 2020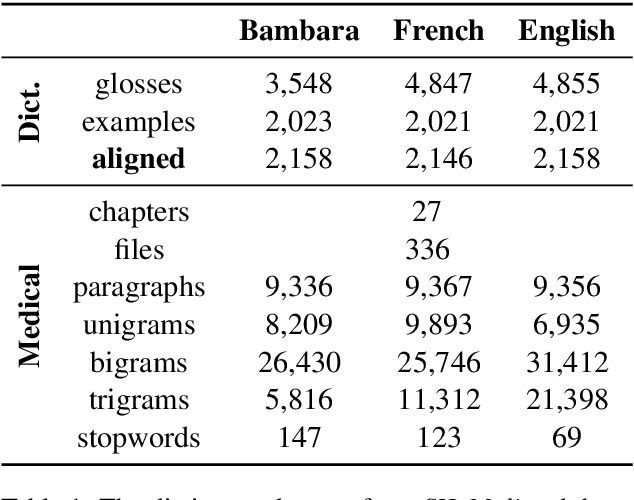
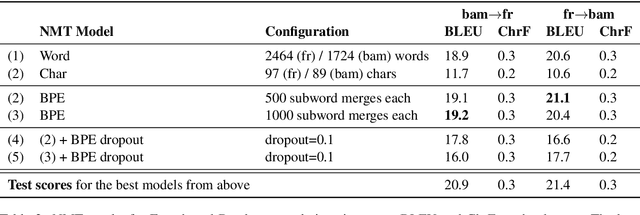
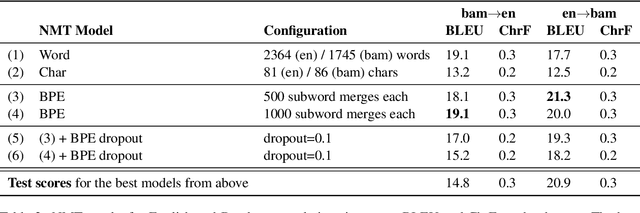
Low-resource languages present unique challenges to (neural) machine translation. We discuss the case of Bambara, a Mande language for which training data is scarce and requires significant amounts of pre-processing. More than the linguistic situation of Bambara itself, the socio-cultural context within which Bambara speakers live poses challenges for automated processing of this language. In this paper, we present the first parallel data set for machine translation of Bambara into and from English and French and the first benchmark results on machine translation to and from Bambara. We discuss challenges in working with low-resource languages and propose strategies to cope with data scarcity in low-resource machine translation (MT).
A $O(\log m)$, deterministic, polynomial-time computable approximation of Lewis Carroll's scoring rule
Apr 09, 2008We provide deterministic, polynomial-time computable voting rules that approximate Dodgson's and (the ``minimization version'' of) Young's scoring rules to within a logarithmic factor. Our approximation of Dodgson's rule is tight up to a constant factor, as Dodgson's rule is $\NP$-hard to approximate to within some logarithmic factor. The ``maximization version'' of Young's rule is known to be $\NP$-hard to approximate by any constant factor. Both approximations are simple, and natural as rules in their own right: Given a candidate we wish to score, we can regard either its Dodgson or Young score as the edit distance between a given set of voter preferences and one in which the candidate to be scored is the Condorcet winner. (The difference between the two scoring rules is the type of edits allowed.) We regard the marginal cost of a sequence of edits to be the number of edits divided by the number of reductions (in the candidate's deficit against any of its opponents in the pairwise race against that opponent) that the edits yield. Over a series of rounds, our scoring rules greedily choose a sequence of edits that modify exactly one voter's preferences and whose marginal cost is no greater than any other such single-vote-modifying sequence.