 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Reproducibility in Evaluation through Multi-Level Annotator Modeling
May 13, 2026As generative AI models such as large language models (LLMs) become more pervasive, ensuring the safety, robustness, and overall trustworthiness of these systems is paramount. However, AI is currently facing a reproducibility crisis driven by unreliable evaluations and unrepeatable experimental results. While human raters are often used to assess models for utility and safety, they introduce divergent biases and subjective opinions into their annotations. Overcoming this variance is exceptionally challenging because very little data exists to study how experimental repeatability actually improves as the annotator pool grows. Standard evaluation practices typically rely on a small number of annotations per item (often 3 to 5) and lack the persistent rater identifiers necessary to model individual variance across items. In this work, we introduce a multi-level bootstrapping approach to realistically model annotator behavior. Leveraging datasets with a large number of ratings and persistent rater identifiers, we analyze the tradeoffs between the number of items ($N$) and the number of responses per item ($K$) required to achieve statistical significance.
How Many Ratings per Item are Necessary for Reliable Significance Testing?
Dec 04, 2024Most approaches to machine learning evaluation assume that machine and human responses are repeatable enough to be measured against data with unitary, authoritative, "gold standard" responses, via simple metrics such as accuracy, precision, and recall that assume scores are independent given the test item. However, AI models have multiple sources of stochasticity and the human raters who create gold standards tend to disagree with each other, often in meaningful ways, hence a single output response per input item may not provide enough information. We introduce methods for determining whether an (existing or planned) evaluation dataset has enough responses per item to reliably compare the performance of one model to another. We apply our methods to several of very few extant gold standard test sets with multiple disaggregated responses per item and show that there are usually not enough responses per item to reliably compare the performance of one model against another. Our methods also allow us to estimate the number of responses per item for hypothetical datasets with similar response distributions to the existing datasets we study. When two models are very far apart in their predictive performance, fewer raters are needed to confidently compare them, as expected. However, as the models draw closer, we find that a larger number of raters than are currently typical in annotation collection are needed to ensure that the power analysis correctly reflects the difference in performance.
Kernel Banzhaf: A Fast and Robust Estimator for Banzhaf Values
Oct 10, 2024



Banzhaf values offer a simple and interpretable alternative to the widely-used Shapley values. We introduce Kernel Banzhaf, a novel algorithm inspired by KernelSHAP, that leverages an elegant connection between Banzhaf values and linear regression. Through extensive experiments on feature attribution tasks, we demonstrate that Kernel Banzhaf substantially outperforms other algorithms for estimating Banzhaf values in both sample efficiency and robustness to noise. Furthermore, we prove theoretical guarantees on the algorithm's performance, establishing Kernel Banzhaf as a valuable tool for interpretable machine learning.
HexCNN: A Framework for Native Hexagonal Convolutional Neural Networks
Jan 25, 2021
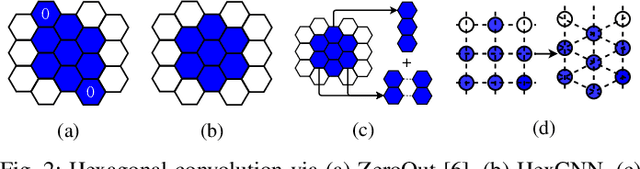
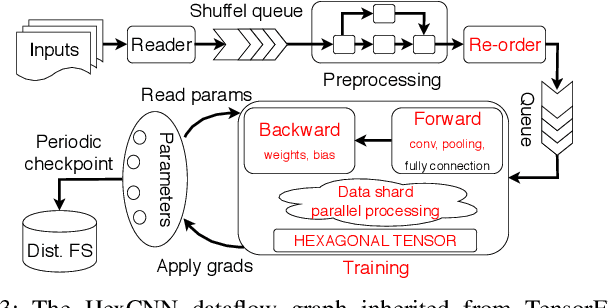
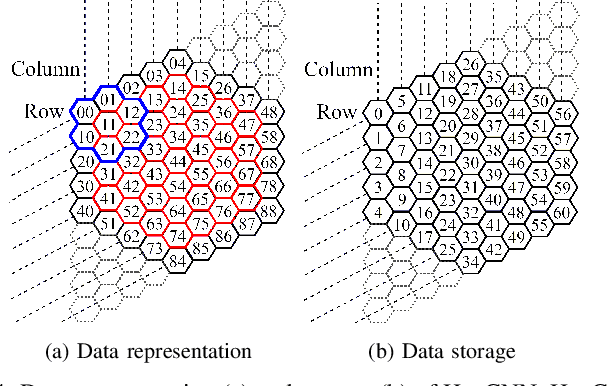
Hexagonal CNN models have shown superior performance in applications such as IACT data analysis and aerial scene classification due to their better rotation symmetry and reduced anisotropy. In order to realize hexagonal processing, existing studies mainly use the ZeroOut method to imitate hexagonal processing, which causes substantial memory and computation overheads. We address this deficiency with a novel native hexagonal CNN framework named HexCNN. HexCNN takes hexagon-shaped input and performs forward and backward propagation on the original form of the input based on hexagon-shaped filters, hence avoiding computation and memory overheads caused by imitation. For applications with rectangle-shaped input but require hexagonal processing, HexCNN can be applied by padding the input into hexagon-shape as preprocessing. In this case, we show that the time and space efficiency of HexCNN still outperforms existing hexagonal CNN methods substantially. Experimental results show that compared with the state-of-the-art models, which imitate hexagonal processing but using rectangle-shaped filters, HexCNN reduces the training time by up to 42.2%. Meanwhile, HexCNN saves the memory space cost by up to 25% and 41.7% for loading the input and performing convolution, respectively.