 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegression-adjusted Monte Carlo Estimators for Shapley Values and Probabilistic Values
Jun 13, 2025With origins in game theory, probabilistic values like Shapley values, Banzhaf values, and semi-values have emerged as a central tool in explainable AI. They are used for feature attribution, data attribution, data valuation, and more. Since all of these values require exponential time to compute exactly, research has focused on efficient approximation methods using two techniques: Monte Carlo sampling and linear regression formulations. In this work, we present a new way of combining both of these techniques. Our approach is more flexible than prior algorithms, allowing for linear regression to be replaced with any function family whose probabilistic values can be computed efficiently. This allows us to harness the accuracy of tree-based models like XGBoost, while still producing unbiased estimates. From experiments across eight datasets, we find that our methods give state-of-the-art performance for estimating probabilistic values. For Shapley values, the error of our methods can be $6.5\times$ lower than Permutation SHAP (the most popular Monte Carlo method), $3.8\times$ lower than Kernel SHAP (the most popular linear regression method), and $2.6\times$ lower than Leverage SHAP (the prior state-of-the-art Shapley value estimator). For more general probabilistic values, we can obtain error $215\times$ lower than the best estimator from prior work.
Magneto: Combining Small and Large Language Models for Schema Matching
Dec 11, 2024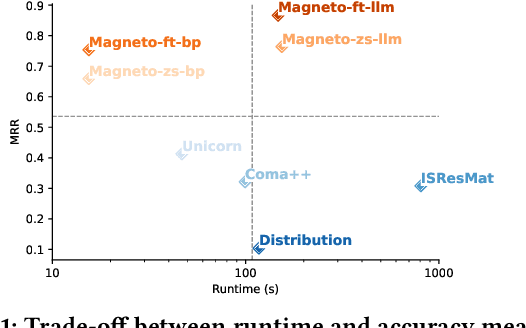
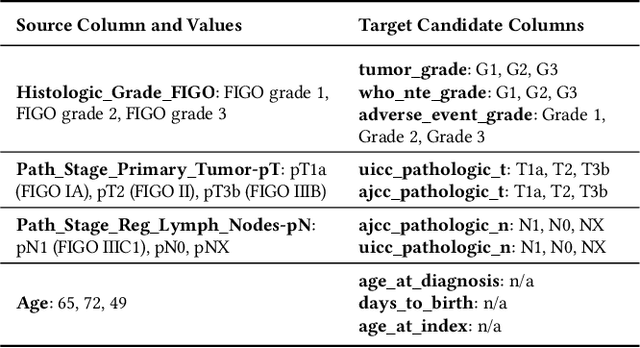


Recent advances in language models opened new opportunities to address complex schema matching tasks. Schema matching approaches have been proposed that demonstrate the usefulness of language models, but they have also uncovered important limitations: Small language models (SLMs) require training data (which can be both expensive and challenging to obtain), and large language models (LLMs) often incur high computational costs and must deal with constraints imposed by context windows. We present Magneto, a cost-effective and accurate solution for schema matching that combines the advantages of SLMs and LLMs to address their limitations. By structuring the schema matching pipeline in two phases, retrieval and reranking, Magneto can use computationally efficient SLM-based strategies to derive candidate matches which can then be reranked by LLMs, thus making it possible to reduce runtime without compromising matching accuracy. We propose a self-supervised approach to fine-tune SLMs which uses LLMs to generate syntactically diverse training data, and prompting strategies that are effective for reranking. We also introduce a new benchmark, developed in collaboration with domain experts, which includes real biomedical datasets and presents new challenges to schema matching methods. Through a detailed experimental evaluation, using both our new and existing benchmarks, we show that Magneto is scalable and attains high accuracy for datasets from different domains.
Kernel Banzhaf: A Fast and Robust Estimator for Banzhaf Values
Oct 10, 2024



Banzhaf values offer a simple and interpretable alternative to the widely-used Shapley values. We introduce Kernel Banzhaf, a novel algorithm inspired by KernelSHAP, that leverages an elegant connection between Banzhaf values and linear regression. Through extensive experiments on feature attribution tasks, we demonstrate that Kernel Banzhaf substantially outperforms other algorithms for estimating Banzhaf values in both sample efficiency and robustness to noise. Furthermore, we prove theoretical guarantees on the algorithm's performance, establishing Kernel Banzhaf as a valuable tool for interpretable machine learning.
Robo-GS: A Physics Consistent Spatial-Temporal Model for Robotic Arm with Hybrid Representation
Aug 27, 2024Real2Sim2Real plays a critical role in robotic arm control and reinforcement learning, yet bridging this gap remains a significant challenge due to the complex physical properties of robots and the objects they manipulate. Existing methods lack a comprehensive solution to accurately reconstruct real-world objects with spatial representations and their associated physics attributes. We propose a Real2Sim pipeline with a hybrid representation model that integrates mesh geometry, 3D Gaussian kernels, and physics attributes to enhance the digital asset representation of robotic arms. This hybrid representation is implemented through a Gaussian-Mesh-Pixel binding technique, which establishes an isomorphic mapping between mesh vertices and Gaussian models. This enables a fully differentiable rendering pipeline that can be optimized through numerical solvers, achieves high-fidelity rendering via Gaussian Splatting, and facilitates physically plausible simulation of the robotic arm's interaction with its environment using mesh-based methods. The code,full presentation and datasets will be made publicly available at our website https://robostudioapp.com
ArcheType: A Novel Framework for Open-Source Column Type Annotation using Large Language Models
Nov 06, 2023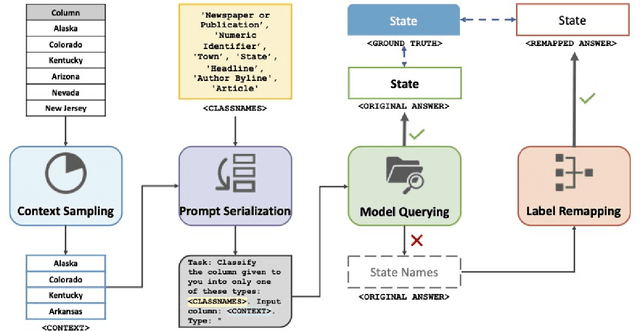



Existing deep-learning approaches to semantic column type annotation (CTA) have important shortcomings: they rely on semantic types which are fixed at training time; require a large number of training samples per type and incur large run-time inference costs; and their performance can degrade when evaluated on novel datasets, even when types remain constant. Large language models have exhibited strong zero-shot classification performance on a wide range of tasks and in this paper we explore their use for CTA. We introduce ArcheType, a simple, practical method for context sampling, prompt serialization, model querying, and label remapping, which enables large language models to solve CTA problems in a fully zero-shot manner. We ablate each component of our method separately, and establish that improvements to context sampling and label remapping provide the most consistent gains. ArcheType establishes a new state-of-the-art performance on zero-shot CTA benchmarks (including three new domain-specific benchmarks which we release along with this paper), and when used in conjunction with classical CTA techniques, it outperforms a SOTA DoDuo model on the fine-tuned SOTAB benchmark. Our code is available at https://github.com/penfever/ArcheType.