 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Provably Unbiased LLM Judges via Bias-Bounded Evaluation
Mar 05, 2026As AI models progress beyond simple chatbots into more complex workflows, we draw ever closer to the event horizon beyond which AI systems will be utilized in autonomous, self-maintaining feedback loops. Any autonomous AI system will depend on automated, verifiable rewards and feedback; in settings where ground truth is sparse or non-deterministic, one practical source of such rewards is an LLM-as-a-Judge. Although LLM judges continue to improve, the literature has yet to introduce systems capable of enforcing standards with strong guarantees, particularly when bias vectors are unknown or adversarially discovered. To remedy this issue, we propose average bias-boundedness (A-BB), an algorithmic framework which formally guarantees reductions of harm/impact as a result of any measurable bias in an LLM judge. Evaluating on Arena-Hard-Auto with four LLM judges, we achieve (tau=0.5, delta=0.01) bias-bounded guarantees while retaining 61-99% correlation with original rankings across formatting and schematic bias settings, with most judge-bias combinations exceeding 80%. The code to reproduce our findings is available at https://github.com/penfever/bias-bounded-evaluation.
MARVIS: Modality Adaptive Reasoning over VISualizations
Jul 02, 2025Scientific applications of machine learning often rely on small, specialized models tuned to particular domains. Such models often achieve excellent performance, but lack flexibility. Foundation models offer versatility, but typically underperform specialized approaches, especially on non-traditional modalities and long-tail domains. We propose MARVIS (Modality Adaptive Reasoning over VISualizations), a training-free method that enables even small vision-language models to predict any data modality with high accuracy. MARVIS transforms latent embedding spaces into visual representations and then leverages the spatial and fine-grained reasoning skills of VLMs to successfully interpret and utilize them. MARVIS achieves competitive performance on vision, audio, biological, and tabular domains using a single 3B parameter model, achieving results that beat Gemini by 16\% on average and approach specialized methods, without exposing personally identifiable information (P.I.I.) or requiring any domain-specific training. We open source our code and datasets at https://github.com/penfever/marvis
OpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Towards Large Reasoning Models for Agriculture
May 25, 2025Agricultural decision-making involves complex, context-specific reasoning, where choices about crops, practices, and interventions depend heavily on geographic, climatic, and economic conditions. Traditional large language models (LLMs) often fall short in navigating this nuanced problem due to limited reasoning capacity. We hypothesize that recent advances in large reasoning models (LRMs) can better handle such structured, domain-specific inference. To investigate this, we introduce AgReason, the first expert-curated open-ended science benchmark with 100 questions for agricultural reasoning. Evaluations across thirteen open-source and proprietary models reveal that LRMs outperform conventional ones, though notable challenges persist, with the strongest Gemini-based baseline achieving 36% accuracy. We also present AgThoughts, a large-scale dataset of 44.6K question-answer pairs generated with human oversight and equipped with synthetically generated reasoning traces. Using AgThoughts, we develop AgThinker, a suite of small reasoning models that can be run on consumer-grade GPUs, and show that our dataset can be effective in unlocking agricultural reasoning abilities in LLMs. Our project page is here: https://baskargroup.github.io/Ag_reasoning/
WILDCHAT-50M: A Deep Dive Into the Role of Synthetic Data in Post-Training
Jan 30, 2025
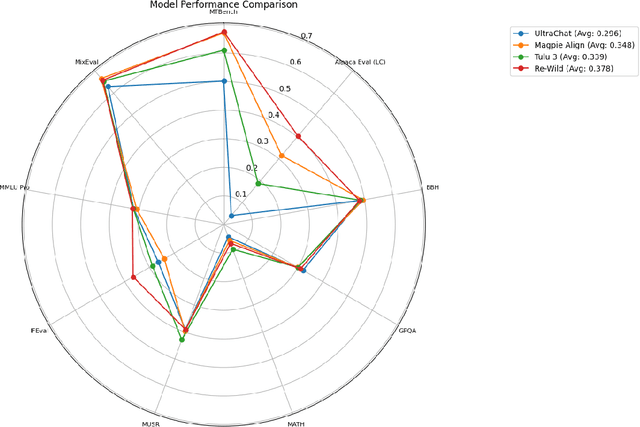

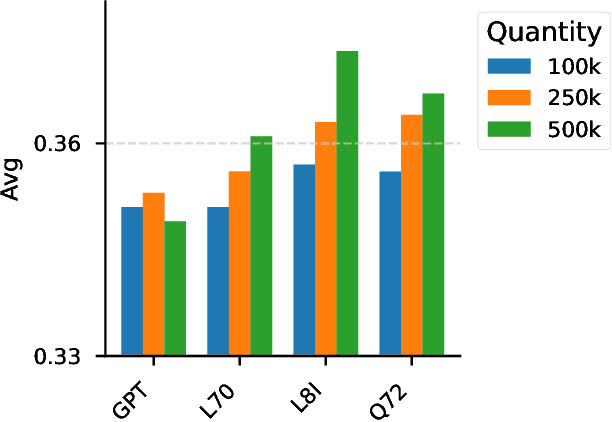
Language model (LLM) post-training, from DPO to distillation, can refine behaviors and unlock new skills, but the open science supporting these post-training techniques is still in its infancy. One limiting factor has been the difficulty of conducting large-scale comparative analyses of synthetic data generating models and LLM judges. To close this gap, we introduce WILDCHAT-50M, the largest public chat dataset to date. We extend the existing WildChat dataset to include responses not only from GPT, but from over 50 different open-weight models, ranging in size from 0.5B to 104B parameters. We conduct an extensive comparative analysis and demonstrate the potential of this dataset by creating RE-WILD, our own public SFT mix, which outperforms the recent Tulu-3 SFT mixture from Allen AI with only 40% as many samples. Our dataset, samples and code are available at https://github.com/penfever/wildchat-50m.
Hidden in the Noise: Two-Stage Robust Watermarking for Images
Dec 05, 2024As the quality of image generators continues to improve, deepfakes become a topic of considerable societal debate. Image watermarking allows responsible model owners to detect and label their AI-generated content, which can mitigate the harm. Yet, current state-of-the-art methods in image watermarking remain vulnerable to forgery and removal attacks. This vulnerability occurs in part because watermarks distort the distribution of generated images, unintentionally revealing information about the watermarking techniques. In this work, we first demonstrate a distortion-free watermarking method for images, based on a diffusion model's initial noise. However, detecting the watermark requires comparing the initial noise reconstructed for an image to all previously used initial noises. To mitigate these issues, we propose a two-stage watermarking framework for efficient detection. During generation, we augment the initial noise with generated Fourier patterns to embed information about the group of initial noises we used. For detection, we (i) retrieve the relevant group of noises, and (ii) search within the given group for an initial noise that might match our image. This watermarking approach achieves state-of-the-art robustness to forgery and removal against a large battery of attacks.
SELECT: A Large-Scale Benchmark of Data Curation Strategies for Image Classification
Oct 07, 2024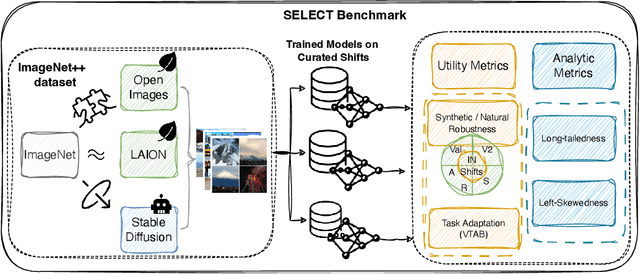
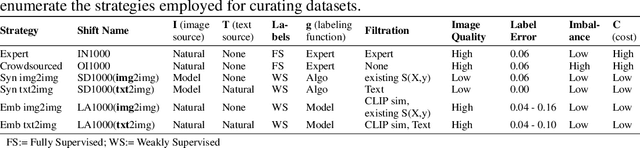

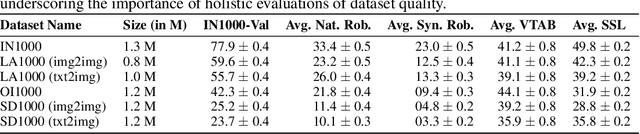
Data curation is the problem of how to collect and organize samples into a dataset that supports efficient learning. Despite the centrality of the task, little work has been devoted towards a large-scale, systematic comparison of various curation methods. In this work, we take steps towards a formal evaluation of data curation strategies and introduce SELECT, the first large-scale benchmark of curation strategies for image classification. In order to generate baseline methods for the SELECT benchmark, we create a new dataset, ImageNet++, which constitutes the largest superset of ImageNet-1K to date. Our dataset extends ImageNet with 5 new training-data shifts, each approximately the size of ImageNet-1K itself, and each assembled using a distinct curation strategy. We evaluate our data curation baselines in two ways: (i) using each training-data shift to train identical image classification models from scratch (ii) using the data itself to fit a pretrained self-supervised representation. Our findings show interesting trends, particularly pertaining to recent methods for data curation such as synthetic data generation and lookup based on CLIP embeddings. We show that although these strategies are highly competitive for certain tasks, the curation strategy used to assemble the original ImageNet-1K dataset remains the gold standard. We anticipate that our benchmark can illuminate the path for new methods to further reduce the gap. We release our checkpoints, code, documentation, and a link to our dataset at https://github.com/jimmyxu123/SELECT.
Arboretum: A Large Multimodal Dataset Enabling AI for Biodiversity
Jun 25, 2024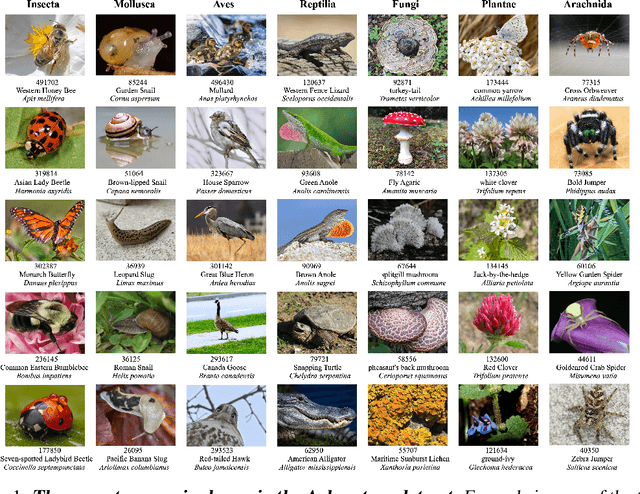

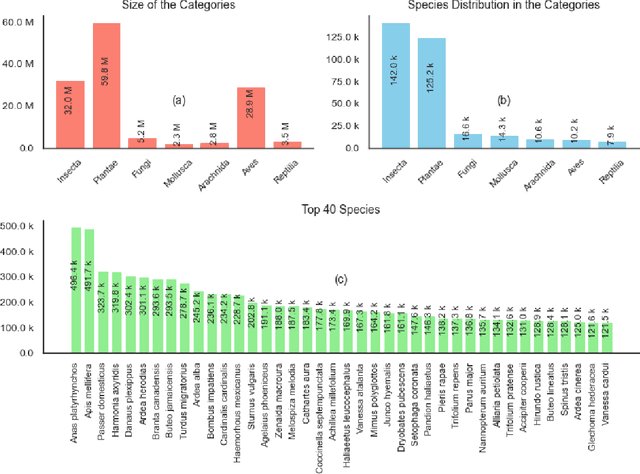

We introduce Arboretum, the largest publicly accessible dataset designed to advance AI for biodiversity applications. This dataset, curated from the iNaturalist community science platform and vetted by domain experts to ensure accuracy, includes 134.6 million images, surpassing existing datasets in scale by an order of magnitude. The dataset encompasses image-language paired data for a diverse set of species from birds (Aves), spiders/ticks/mites (Arachnida), insects (Insecta), plants (Plantae), fungus/mushrooms (Fungi), snails (Mollusca), and snakes/lizards (Reptilia), making it a valuable resource for multimodal vision-language AI models for biodiversity assessment and agriculture research. Each image is annotated with scientific names, taxonomic details, and common names, enhancing the robustness of AI model training. We showcase the value of Arboretum by releasing a suite of CLIP models trained using a subset of 40 million captioned images. We introduce several new benchmarks for rigorous assessment, report accuracy for zero-shot learning, and evaluations across life stages, rare species, confounding species, and various levels of the taxonomic hierarchy. We anticipate that Arboretum will spur the development of AI models that can enable a variety of digital tools ranging from pest control strategies, crop monitoring, and worldwide biodiversity assessment and environmental conservation. These advancements are critical for ensuring food security, preserving ecosystems, and mitigating the impacts of climate change. Arboretum is publicly available, easily accessible, and ready for immediate use. Please see the \href{https://baskargroup.github.io/Arboretum/}{project website} for links to our data, models, and code.
TuneTables: Context Optimization for Scalable Prior-Data Fitted Networks
Feb 17, 2024



While tabular classification has traditionally relied on from-scratch training, a recent breakthrough called prior-data fitted networks (PFNs) challenges this approach. Similar to large language models, PFNs make use of pretraining and in-context learning to achieve strong performance on new tasks in a single forward pass. However, current PFNs have limitations that prohibit their widespread adoption. Notably, TabPFN achieves very strong performance on small tabular datasets but is not designed to make predictions for datasets of size larger than 1000. In this work, we overcome these limitations and substantially improve the performance of PFNs by developing context optimization techniques for PFNs. Specifically, we propose TuneTables, a novel prompt-tuning strategy that compresses large datasets into a smaller learned context. TuneTables scales TabPFN to be competitive with state-of-the-art tabular classification methods on larger datasets, while having a substantially lower inference time than TabPFN. Furthermore, we show that TuneTables can be used as an interpretability tool and can even be used to mitigate biases by optimizing a fairness objective.
Scaling TabPFN: Sketching and Feature Selection for Tabular Prior-Data Fitted Networks
Nov 17, 2023Tabular classification has traditionally relied on supervised algorithms, which estimate the parameters of a prediction model using its training data. Recently, Prior-Data Fitted Networks (PFNs) such as TabPFN have successfully learned to classify tabular data in-context: the model parameters are designed to classify new samples based on labelled training samples given after the model training. While such models show great promise, their applicability to real-world data remains limited due to the computational scale needed. Here we study the following question: given a pre-trained PFN for tabular data, what is the best way to summarize the labelled training samples before feeding them to the model? We conduct an initial investigation of sketching and feature-selection methods for TabPFN, and note certain key differences between it and conventionally fitted tabular models.