 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArboretum: A Large Multimodal Dataset Enabling AI for Biodiversity
Jun 25, 2024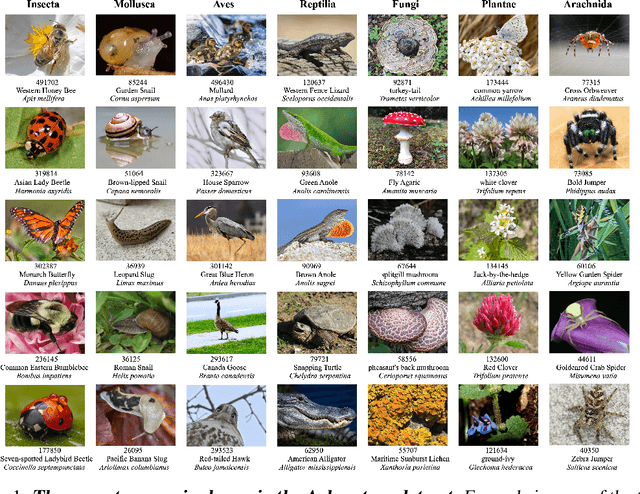

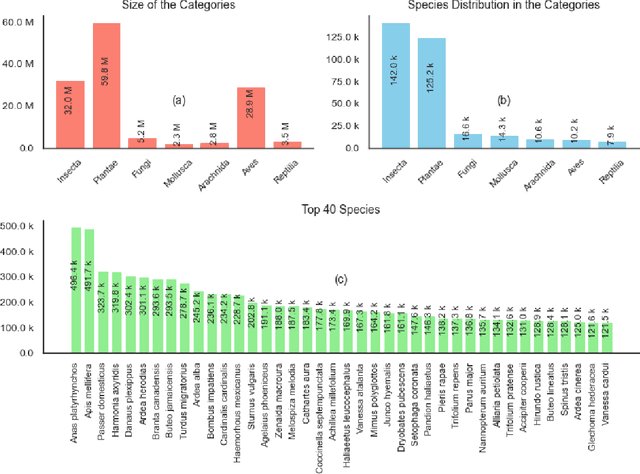

We introduce Arboretum, the largest publicly accessible dataset designed to advance AI for biodiversity applications. This dataset, curated from the iNaturalist community science platform and vetted by domain experts to ensure accuracy, includes 134.6 million images, surpassing existing datasets in scale by an order of magnitude. The dataset encompasses image-language paired data for a diverse set of species from birds (Aves), spiders/ticks/mites (Arachnida), insects (Insecta), plants (Plantae), fungus/mushrooms (Fungi), snails (Mollusca), and snakes/lizards (Reptilia), making it a valuable resource for multimodal vision-language AI models for biodiversity assessment and agriculture research. Each image is annotated with scientific names, taxonomic details, and common names, enhancing the robustness of AI model training. We showcase the value of Arboretum by releasing a suite of CLIP models trained using a subset of 40 million captioned images. We introduce several new benchmarks for rigorous assessment, report accuracy for zero-shot learning, and evaluations across life stages, rare species, confounding species, and various levels of the taxonomic hierarchy. We anticipate that Arboretum will spur the development of AI models that can enable a variety of digital tools ranging from pest control strategies, crop monitoring, and worldwide biodiversity assessment and environmental conservation. These advancements are critical for ensuring food security, preserving ecosystems, and mitigating the impacts of climate change. Arboretum is publicly available, easily accessible, and ready for immediate use. Please see the \href{https://baskargroup.github.io/Arboretum/}{project website} for links to our data, models, and code.
On the Expressive Power of Graph Neural Networks
Jan 03, 2024The study of Graph Neural Networks has received considerable interest in the past few years. By extending deep learning to graph-structured data, GNNs can solve a diverse set of tasks in fields including social science, chemistry, and medicine. The development of GNN architectures has largely been focused on improving empirical performance on tasks like node or graph classification. However, a line of recent work has instead sought to find GNN architectures that have desirable theoretical properties - by studying their expressive power and designing architectures that maximize this expressiveness. While there is no consensus on the best way to define the expressiveness of a GNN, it can be viewed from several well-motivated perspectives. Perhaps the most natural approach is to study the universal approximation properties of GNNs, much in the way that this has been studied extensively for MLPs. Another direction focuses on the extent to which GNNs can distinguish between different graph structures, relating this to the graph isomorphism test. Besides, a GNN's ability to compute graph properties such as graph moments has been suggested as another form of expressiveness. All of these different definitions are complementary and have yielded different recommendations for GNN architecture choices. In this paper, we would like to give an overview of the notion of "expressive power" of GNNs and provide some valuable insights regarding the design choices of GNNs.
Towards Foundational AI Models for Additive Manufacturing: Language Models for G-Code Debugging, Manipulation, and Comprehension
Sep 04, 2023



3D printing or additive manufacturing is a revolutionary technology that enables the creation of physical objects from digital models. However, the quality and accuracy of 3D printing depend on the correctness and efficiency of the G-code, a low-level numerical control programming language that instructs 3D printers how to move and extrude material. Debugging G-code is a challenging task that requires a syntactic and semantic understanding of the G-code format and the geometry of the part to be printed. In this paper, we present the first extensive evaluation of six state-of-the-art foundational large language models (LLMs) for comprehending and debugging G-code files for 3D printing. We design effective prompts to enable pre-trained LLMs to understand and manipulate G-code and test their performance on various aspects of G-code debugging and manipulation, including detection and correction of common errors and the ability to perform geometric transformations. We analyze their strengths and weaknesses for understanding complete G-code files. We also discuss the implications and limitations of using LLMs for G-code comprehension.