 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagneto: Combining Small and Large Language Models for Schema Matching
Dec 11, 2024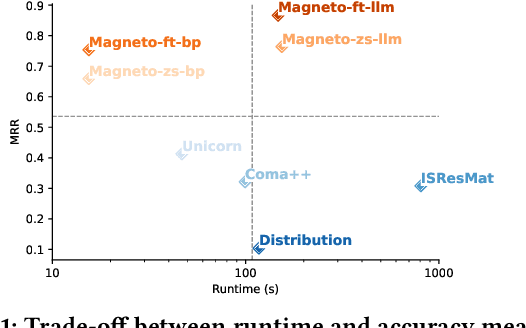
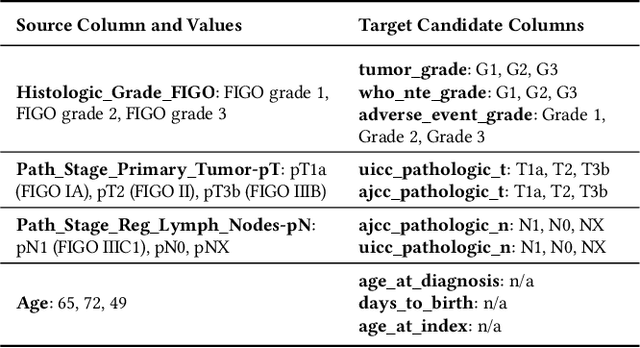


Recent advances in language models opened new opportunities to address complex schema matching tasks. Schema matching approaches have been proposed that demonstrate the usefulness of language models, but they have also uncovered important limitations: Small language models (SLMs) require training data (which can be both expensive and challenging to obtain), and large language models (LLMs) often incur high computational costs and must deal with constraints imposed by context windows. We present Magneto, a cost-effective and accurate solution for schema matching that combines the advantages of SLMs and LLMs to address their limitations. By structuring the schema matching pipeline in two phases, retrieval and reranking, Magneto can use computationally efficient SLM-based strategies to derive candidate matches which can then be reranked by LLMs, thus making it possible to reduce runtime without compromising matching accuracy. We propose a self-supervised approach to fine-tune SLMs which uses LLMs to generate syntactically diverse training data, and prompting strategies that are effective for reranking. We also introduce a new benchmark, developed in collaboration with domain experts, which includes real biomedical datasets and presents new challenges to schema matching methods. Through a detailed experimental evaluation, using both our new and existing benchmarks, we show that Magneto is scalable and attains high accuracy for datasets from different domains.