 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntrinsic and Extrinsic Factor Disentanglement for Recommendation in Various Context Scenarios
Mar 05, 2025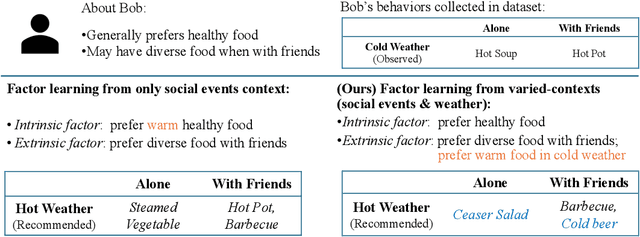
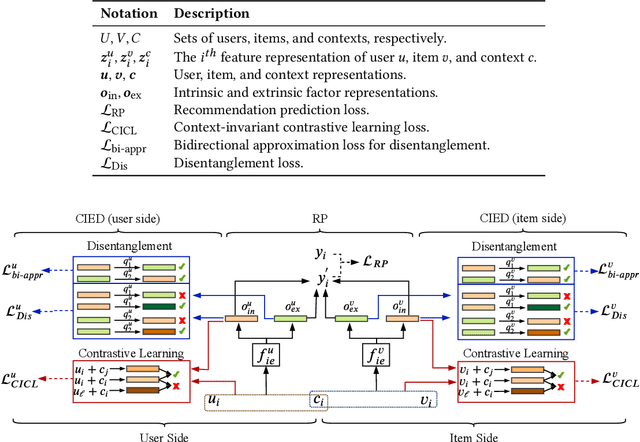
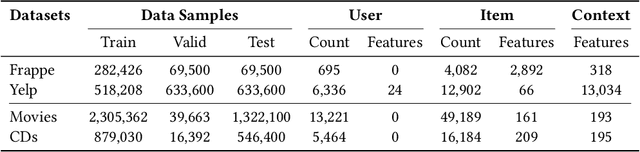
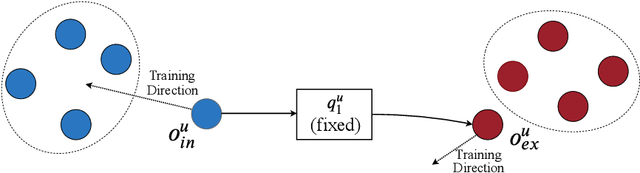
In recommender systems, the patterns of user behaviors (e.g., purchase, click) may vary greatly in different contexts (e.g., time and location). This is because user behavior is jointly determined by two types of factors: intrinsic factors, which reflect consistent user preference, and extrinsic factors, which reflect external incentives that may vary in different contexts. Differentiating between intrinsic and extrinsic factors helps learn user behaviors better. However, existing studies have only considered differentiating them from a single, pre-defined context (e.g., time or location), ignoring the fact that a user's extrinsic factors may be influenced by the interplay of various contexts at the same time. In this paper, we propose the Intrinsic-Extrinsic Disentangled Recommendation (IEDR) model, a generic framework that differentiates intrinsic from extrinsic factors considering various contexts simultaneously, enabling more accurate differentiation of factors and hence the improvement of recommendation accuracy. IEDR contains a context-invariant contrastive learning component to capture intrinsic factors, and a disentanglement component to extract extrinsic factors under the interplay of various contexts. The two components work together to achieve effective factor learning. Extensive experiments on real-world datasets demonstrate IEDR's effectiveness in learning disentangled factors and significantly improving recommendation accuracy by up to 4% in NDCG.
DaMSTF: Domain Adversarial Learning Enhanced Meta Self-Training for Domain Adaptation
Aug 05, 2023



Self-training emerges as an important research line on domain adaptation. By taking the model's prediction as the pseudo labels of the unlabeled data, self-training bootstraps the model with pseudo instances in the target domain. However, the prediction errors of pseudo labels (label noise) challenge the performance of self-training. To address this problem, previous approaches only use reliable pseudo instances, i.e., pseudo instances with high prediction confidence, to retrain the model. Although these strategies effectively reduce the label noise, they are prone to miss the hard examples. In this paper, we propose a new self-training framework for domain adaptation, namely Domain adversarial learning enhanced Self-Training Framework (DaMSTF). Firstly, DaMSTF involves meta-learning to estimate the importance of each pseudo instance, so as to simultaneously reduce the label noise and preserve hard examples. Secondly, we design a meta constructor for constructing the meta-validation set, which guarantees the effectiveness of the meta-learning module by improving the quality of the meta-validation set. Thirdly, we find that the meta-learning module suffers from the training guidance vanishment and tends to converge to an inferior optimal. To this end, we employ domain adversarial learning as a heuristic neural network initialization method, which can help the meta-learning module converge to a better optimal. Theoretically and experimentally, we demonstrate the effectiveness of the proposed DaMSTF. On the cross-domain sentiment classification task, DaMSTF improves the performance of BERT with an average of nearly 4%.
Meta-Tsallis-Entropy Minimization: A New Self-Training Approach for Domain Adaptation on Text Classification
Aug 04, 2023



Text classification is a fundamental task for natural language processing, and adapting text classification models across domains has broad applications. Self-training generates pseudo-examples from the model's predictions and iteratively trains on the pseudo-examples, i.e., minimizes the loss on the source domain and the Gibbs entropy on the target domain. However, Gibbs entropy is sensitive to prediction errors, and thus, self-training tends to fail when the domain shift is large. In this paper, we propose Meta-Tsallis Entropy minimization (MTEM), which applies a meta-learning algorithm to optimize the instance adaptive Tsallis entropy on the target domain. To reduce the computation cost of MTEM, we propose an approximation technique to approximate the Second-order derivation involved in the meta-learning. To efficiently generate pseudo labels, we propose an annealing sampling mechanism for exploring the model's prediction probability. Theoretically, we prove the convergence of the meta-learning algorithm in MTEM and analyze the effectiveness of MTEM in achieving domain adaptation. Experimentally, MTEM improves the adaptation performance of BERT with an average of 4 percent on the benchmark dataset.
Detecting Arbitrary Order Beneficial Feature Interactions for Recommender Systems
Jun 28, 2022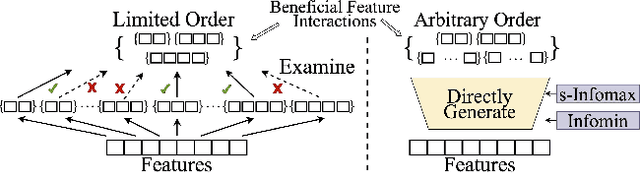
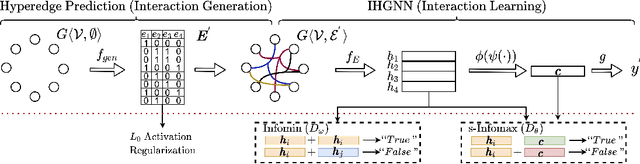
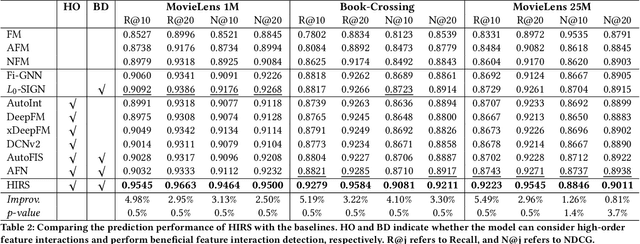
Detecting beneficial feature interactions is essential in recommender systems, and existing approaches achieve this by examining all the possible feature interactions. However, the cost of examining all the possible higher-order feature interactions is prohibitive (exponentially growing with the order increasing). Hence existing approaches only detect limited order (e.g., combinations of up to four features) beneficial feature interactions, which may miss beneficial feature interactions with orders higher than the limitation. In this paper, we propose a hypergraph neural network based model named HIRS. HIRS is the first work that directly generates beneficial feature interactions of arbitrary orders and makes recommendation predictions accordingly. The number of generated feature interactions can be specified to be much smaller than the number of all the possible interactions and hence, our model admits a much lower running time. To achieve an effective algorithm, we exploit three properties of beneficial feature interactions, and propose deep-infomax-based methods to guide the interaction generation. Our experimental results show that HIRS outperforms state-of-the-art algorithms by up to 5% in terms of recommendation accuracy.
Graph Pooling via Coarsened Graph Infomax
May 31, 2021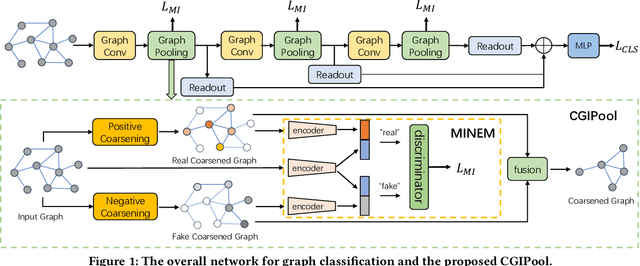
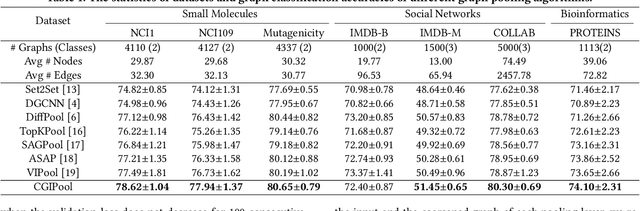
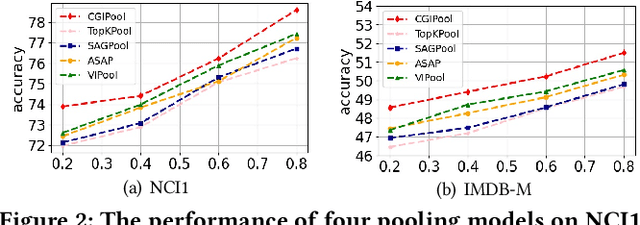
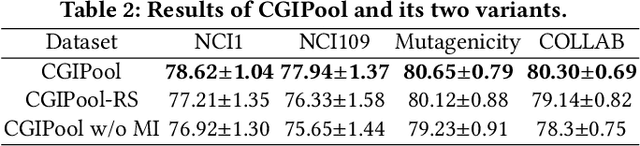
Graph pooling that summaries the information in a large graph into a compact form is essential in hierarchical graph representation learning. Existing graph pooling methods either suffer from high computational complexity or cannot capture the global dependencies between graphs before and after pooling. To address the problems of existing graph pooling methods, we propose Coarsened Graph Infomax Pooling (CGIPool) that maximizes the mutual information between the input and the coarsened graph of each pooling layer to preserve graph-level dependencies. To achieve mutual information neural maximization, we apply contrastive learning and propose a self-attention-based algorithm for learning positive and negative samples. Extensive experimental results on seven datasets illustrate the superiority of CGIPool comparing to the state-of-the-art methods.
WGCN: Graph Convolutional Networks with Weighted Structural Features
Apr 29, 2021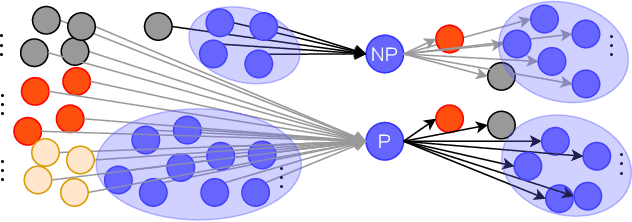
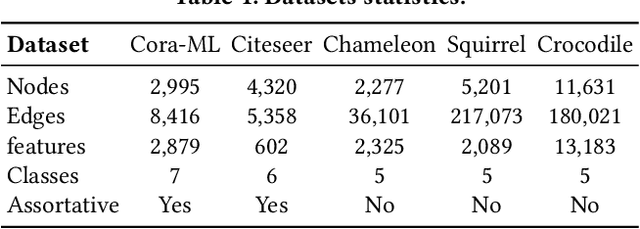
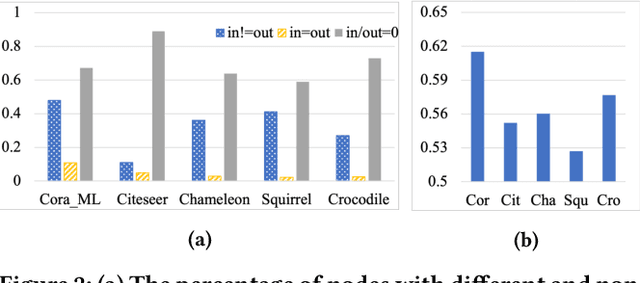
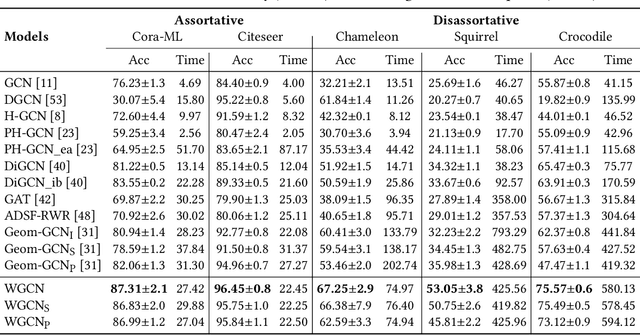
Graph structural information such as topologies or connectivities provides valuable guidance for graph convolutional networks (GCNs) to learn nodes' representations. Existing GCN models that capture nodes' structural information weight in- and out-neighbors equally or differentiate in- and out-neighbors globally without considering nodes' local topologies. We observe that in- and out-neighbors contribute differently for nodes with different local topologies. To explore the directional structural information for different nodes, we propose a GCN model with weighted structural features, named WGCN. WGCN first captures nodes' structural fingerprints via a direction and degree aware Random Walk with Restart algorithm, where the walk is guided by both edge direction and nodes' in- and out-degrees. Then, the interactions between nodes' structural fingerprints are used as the weighted node structural features. To further capture nodes' high-order dependencies and graph geometry, WGCN embeds graphs into a latent space to obtain nodes' latent neighbors and geometrical relationships. Based on nodes' geometrical relationships in the latent space, WGCN differentiates latent, in-, and out-neighbors with an attention-based geometrical aggregation. Experiments on transductive node classification tasks show that WGCN outperforms the baseline models consistently by up to 17.07% in terms of accuracy on five benchmark datasets.
HexCNN: A Framework for Native Hexagonal Convolutional Neural Networks
Jan 25, 2021
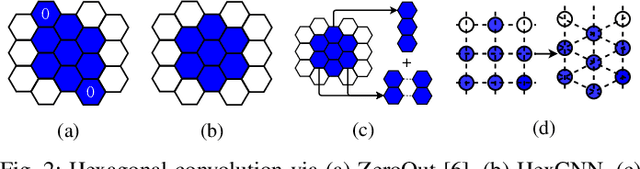
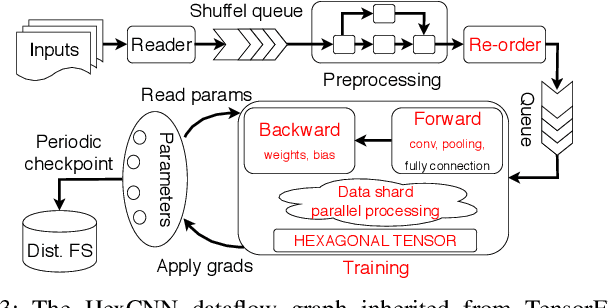
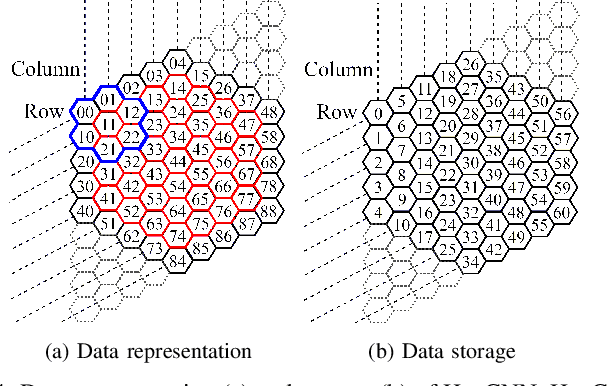
Hexagonal CNN models have shown superior performance in applications such as IACT data analysis and aerial scene classification due to their better rotation symmetry and reduced anisotropy. In order to realize hexagonal processing, existing studies mainly use the ZeroOut method to imitate hexagonal processing, which causes substantial memory and computation overheads. We address this deficiency with a novel native hexagonal CNN framework named HexCNN. HexCNN takes hexagon-shaped input and performs forward and backward propagation on the original form of the input based on hexagon-shaped filters, hence avoiding computation and memory overheads caused by imitation. For applications with rectangle-shaped input but require hexagonal processing, HexCNN can be applied by padding the input into hexagon-shape as preprocessing. In this case, we show that the time and space efficiency of HexCNN still outperforms existing hexagonal CNN methods substantially. Experimental results show that compared with the state-of-the-art models, which imitate hexagonal processing but using rectangle-shaped filters, HexCNN reduces the training time by up to 42.2%. Meanwhile, HexCNN saves the memory space cost by up to 25% and 41.7% for loading the input and performing convolution, respectively.
CBHE: Corner-based Building Height Estimation for Complex Street Scene Images
Apr 25, 2019

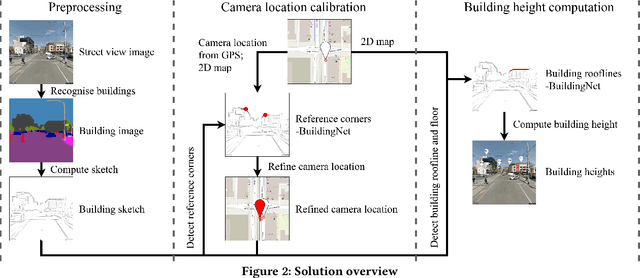

Building height estimation is important in many applications such as 3D city reconstruction, urban planning, and navigation. Recently, a new building height estimation method using street scene images and 2D maps was proposed. This method is more scalable than traditional methods that use high-resolution optical data, LiDAR data, or RADAR data which are expensive to obtain. The method needs to detect building rooflines and then compute building height via the pinhole camera model. We observe that this method has limitations in handling complex street scene images in which buildings overlap with each other and the rooflines are difficult to locate. We propose CBHE, a building height estimation algorithm considering both building corners and rooflines. CBHE first obtains building corner and roofline candidates in street scene images based on building footprints from 2D maps and the camera parameters. Then, we use a deep neural network named BuildingNet to classify and filter corner and roofline candidates. Based on the valid corners and rooflines from BuildingNet, CBHE computes building height via the pinhole camera model. Experimental results show that the proposed BuildingNet yields a higher accuracy on building corner and roofline candidate filtering compared with the state-of-the-art open set classifiers. Meanwhile, CBHE outperforms the baseline algorithm by over 10% in building height estimation accuracy.