 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiGR: Efficient Generative Slate Recommendation via Hierarchical Planning and Multi-Objective Preference Alignment
Dec 31, 2025Slate recommendation, where users are presented with a ranked list of items simultaneously, is widely adopted in online platforms. Recent advances in generative models have shown promise in slate recommendation by modeling sequences of discrete semantic IDs autoregressively. However, existing autoregressive approaches suffer from semantically entangled item tokenization and inefficient sequential decoding that lacks holistic slate planning. To address these limitations, we propose HiGR, an efficient generative slate recommendation framework that integrates hierarchical planning with listwise preference alignment. First, we propose an auto-encoder utilizing residual quantization and contrastive constraints to tokenize items into semantically structured IDs for controllable generation. Second, HiGR decouples generation into a list-level planning stage for global slate intent, followed by an item-level decoding stage for specific item selection. Third, we introduce a listwise preference alignment objective to directly optimize slate quality using implicit user feedback. Experiments on our large-scale commercial media platform demonstrate that HiGR delivers consistent improvements in both offline evaluations and online deployment. Specifically, it outperforms state-of-the-art methods by over 10% in offline recommendation quality with a 5x inference speedup, while further achieving a 1.22% and 1.73% increase in Average Watch Time and Average Video Views in online A/B tests.
Interactive Spatiotemporal Token Attention Network for Skeleton-based General Interactive Action Recognition
Jul 14, 2023Recognizing interactive action plays an important role in human-robot interaction and collaboration. Previous methods use late fusion and co-attention mechanism to capture interactive relations, which have limited learning capability or inefficiency to adapt to more interacting entities. With assumption that priors of each entity are already known, they also lack evaluations on a more general setting addressing the diversity of subjects. To address these problems, we propose an Interactive Spatiotemporal Token Attention Network (ISTA-Net), which simultaneously model spatial, temporal, and interactive relations. Specifically, our network contains a tokenizer to partition Interactive Spatiotemporal Tokens (ISTs), which is a unified way to represent motions of multiple diverse entities. By extending the entity dimension, ISTs provide better interactive representations. To jointly learn along three dimensions in ISTs, multi-head self-attention blocks integrated with 3D convolutions are designed to capture inter-token correlations. When modeling correlations, a strict entity ordering is usually irrelevant for recognizing interactive actions. To this end, Entity Rearrangement is proposed to eliminate the orderliness in ISTs for interchangeable entities. Extensive experiments on four datasets verify the effectiveness of ISTA-Net by outperforming state-of-the-art methods. Our code is publicly available at https://github.com/Necolizer/ISTA-Net
IGFormer: Interaction Graph Transformer for Skeleton-based Human Interaction Recognition
Jul 25, 2022
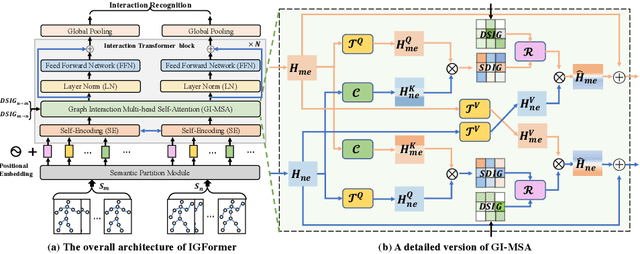
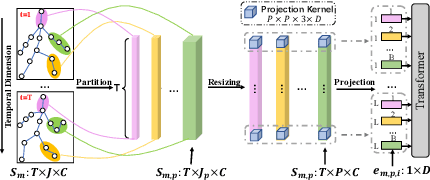
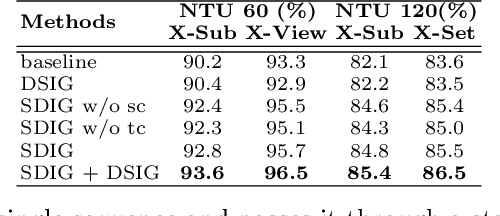
Human interaction recognition is very important in many applications. One crucial cue in recognizing an interaction is the interactive body parts. In this work, we propose a novel Interaction Graph Transformer (IGFormer) network for skeleton-based interaction recognition via modeling the interactive body parts as graphs. More specifically, the proposed IGFormer constructs interaction graphs according to the semantic and distance correlations between the interactive body parts, and enhances the representation of each person by aggregating the information of the interactive body parts based on the learned graphs. Furthermore, we propose a Semantic Partition Module to transform each human skeleton sequence into a Body-Part-Time sequence to better capture the spatial and temporal information of the skeleton sequence for learning the graphs. Extensive experiments on three benchmark datasets demonstrate that our model outperforms the state-of-the-art with a significant margin.
Graph Pooling via Coarsened Graph Infomax
May 31, 2021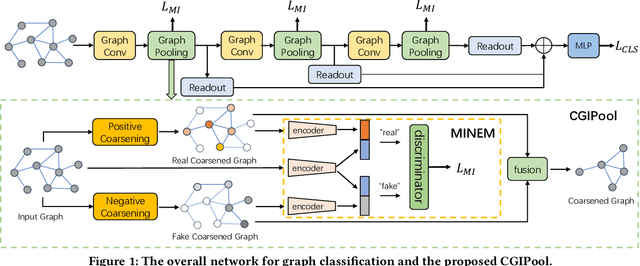
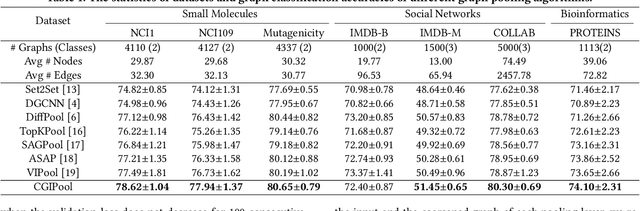
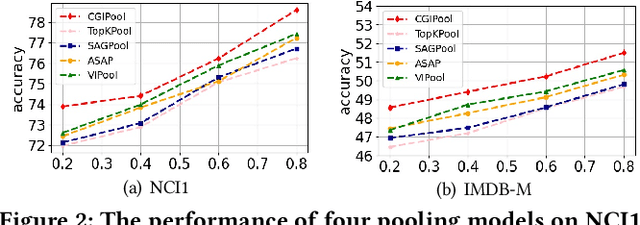
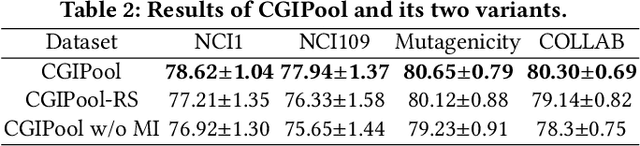
Graph pooling that summaries the information in a large graph into a compact form is essential in hierarchical graph representation learning. Existing graph pooling methods either suffer from high computational complexity or cannot capture the global dependencies between graphs before and after pooling. To address the problems of existing graph pooling methods, we propose Coarsened Graph Infomax Pooling (CGIPool) that maximizes the mutual information between the input and the coarsened graph of each pooling layer to preserve graph-level dependencies. To achieve mutual information neural maximization, we apply contrastive learning and propose a self-attention-based algorithm for learning positive and negative samples. Extensive experimental results on seven datasets illustrate the superiority of CGIPool comparing to the state-of-the-art methods.