 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch Self-play: Pushing the Frontier of Agent Capability without Supervision
Oct 21, 2025Reinforcement learning with verifiable rewards (RLVR) has become the mainstream technique for training LLM agents. However, RLVR highly depends on well-crafted task queries and corresponding ground-truth answers to provide accurate rewards, which requires massive human efforts and hinders the RL scaling processes, especially under agentic scenarios. Although a few recent works explore task synthesis methods, the difficulty of generated agentic tasks can hardly be controlled to provide effective RL training advantages. To achieve agentic RLVR with higher scalability, we explore self-play training for deep search agents, in which the learning LLM utilizes multi-turn search engine calling and acts simultaneously as both a task proposer and a problem solver. The task proposer aims to generate deep search queries with well-defined ground-truth answers and increasing task difficulty. The problem solver tries to handle the generated search queries and output the correct answer predictions. To ensure that each generated search query has accurate ground truth, we collect all the searching results from the proposer's trajectory as external knowledge, then conduct retrieval-augmentation generation (RAG) to test whether the proposed query can be correctly answered with all necessary search documents provided. In this search self-play (SSP) game, the proposer and the solver co-evolve their agent capabilities through both competition and cooperation. With substantial experimental results, we find that SSP can significantly improve search agents' performance uniformly on various benchmarks without any supervision under both from-scratch and continuous RL training setups. The code is at https://github.com/Alibaba-Quark/SSP.
CHASE: Learning Convex Hull Adaptive Shift for Skeleton-based Multi-Entity Action Recognition
Oct 09, 2024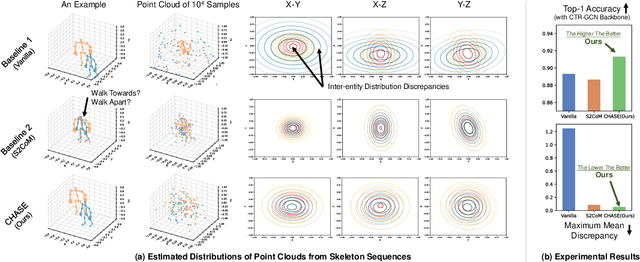
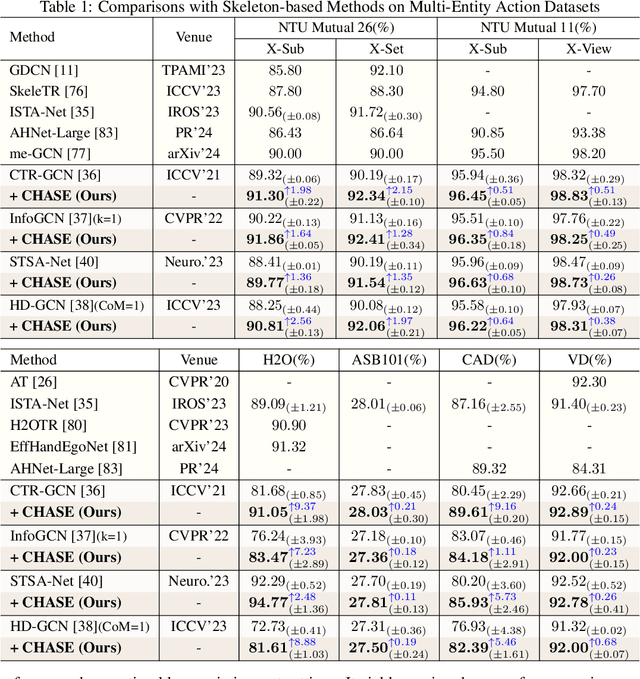
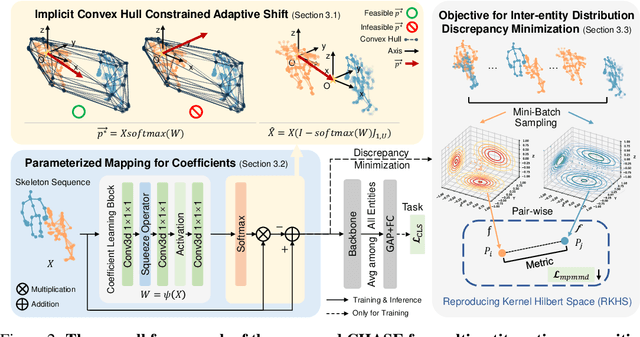
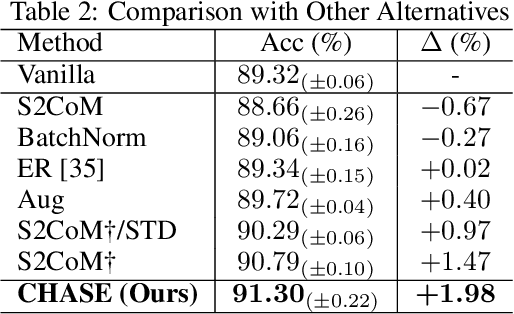
Skeleton-based multi-entity action recognition is a challenging task aiming to identify interactive actions or group activities involving multiple diverse entities. Existing models for individuals often fall short in this task due to the inherent distribution discrepancies among entity skeletons, leading to suboptimal backbone optimization. To this end, we introduce a Convex Hull Adaptive Shift based multi-Entity action recognition method (CHASE), which mitigates inter-entity distribution gaps and unbiases subsequent backbones. Specifically, CHASE comprises a learnable parameterized network and an auxiliary objective. The parameterized network achieves plausible, sample-adaptive repositioning of skeleton sequences through two key components. First, the Implicit Convex Hull Constrained Adaptive Shift ensures that the new origin of the coordinate system is within the skeleton convex hull. Second, the Coefficient Learning Block provides a lightweight parameterization of the mapping from skeleton sequences to their specific coefficients in convex combinations. Moreover, to guide the optimization of this network for discrepancy minimization, we propose the Mini-batch Pair-wise Maximum Mean Discrepancy as the additional objective. CHASE operates as a sample-adaptive normalization method to mitigate inter-entity distribution discrepancies, thereby reducing data bias and improving the subsequent classifier's multi-entity action recognition performance. Extensive experiments on six datasets, including NTU Mutual 11/26, H2O, Assembly101, Collective Activity and Volleyball, consistently verify our approach by seamlessly adapting to single-entity backbones and boosting their performance in multi-entity scenarios. Our code is publicly available at https://github.com/Necolizer/CHASE .
A Survey on Backbones for Deep Video Action Recognition
May 09, 2024
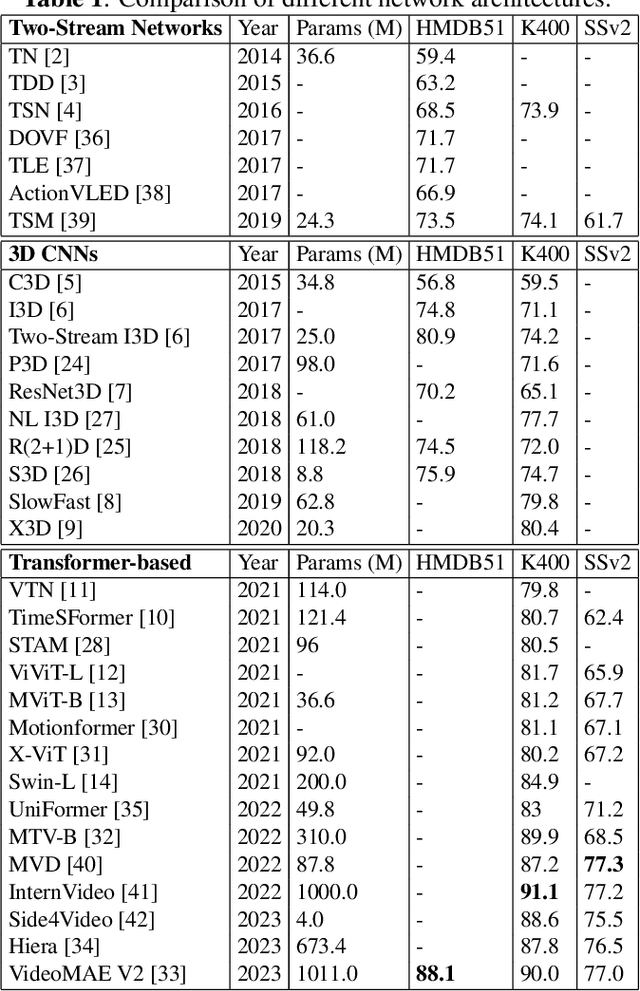
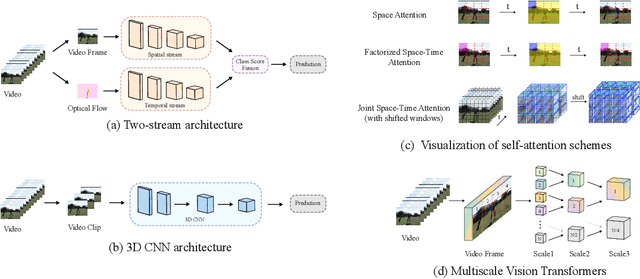
Action recognition is a key technology in building interactive metaverses. With the rapid development of deep learning, methods in action recognition have also achieved great advancement. Researchers design and implement the backbones referring to multiple standpoints, which leads to the diversity of methods and encountering new challenges. This paper reviews several action recognition methods based on deep neural networks. We introduce these methods in three parts: 1) Two-Streams networks and their variants, which, specifically in this paper, use RGB video frame and optical flow modality as input; 2) 3D convolutional networks, which make efforts in taking advantage of RGB modality directly while extracting different motion information is no longer necessary; 3) Transformer-based methods, which introduce the model from natural language processing into computer vision and video understanding. We offer objective sights in this review and hopefully provide a reference for future research.
Explore Human Parsing Modality for Action Recognition
Jan 04, 2024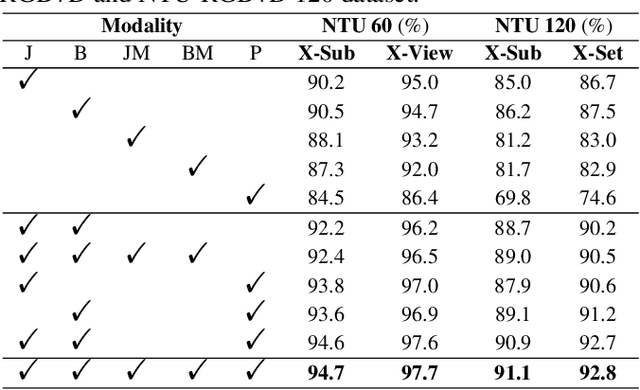

Multimodal-based action recognition methods have achieved high success using pose and RGB modality. However, skeletons sequences lack appearance depiction and RGB images suffer irrelevant noise due to modality limitations. To address this, we introduce human parsing feature map as a novel modality, since it can selectively retain effective semantic features of the body parts, while filtering out most irrelevant noise. We propose a new dual-branch framework called Ensemble Human Parsing and Pose Network (EPP-Net), which is the first to leverage both skeletons and human parsing modalities for action recognition. The first human pose branch feeds robust skeletons in graph convolutional network to model pose features, while the second human parsing branch also leverages depictive parsing feature maps to model parsing festures via convolutional backbones. The two high-level features will be effectively combined through a late fusion strategy for better action recognition. Extensive experiments on NTU RGB+D and NTU RGB+D 120 benchmarks consistently verify the effectiveness of our proposed EPP-Net, which outperforms the existing action recognition methods. Our code is available at: https://github.com/liujf69/EPP-Net-Action.
Facial Prior Based First Order Motion Model for Micro-expression Generation
Aug 08, 2023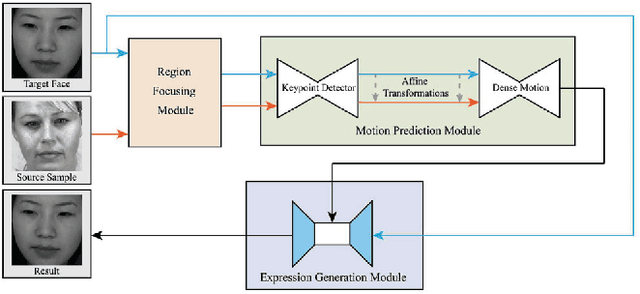
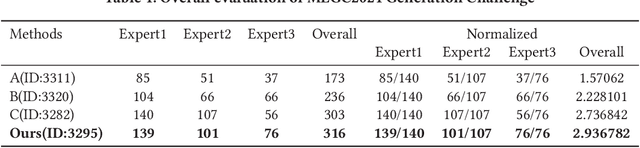

Spotting facial micro-expression from videos finds various potential applications in fields including clinical diagnosis and interrogation, meanwhile this task is still difficult due to the limited scale of training data. To solve this problem, this paper tries to formulate a new task called micro-expression generation and then presents a strong baseline which combines the first order motion model with facial prior knowledge. Given a target face, we intend to drive the face to generate micro-expression videos according to the motion patterns of source videos. Specifically, our new model involves three modules. First, we extract facial prior features from a region focusing module. Second, we estimate facial motion using key points and local affine transformations with a motion prediction module. Third, expression generation module is used to drive the target face to generate videos. We train our model on public CASME II, SAMM and SMIC datasets and then use the model to generate new micro-expression videos for evaluation. Our model achieves the first place in the Facial Micro-Expression Challenge 2021 (MEGC2021), where our superior performance is verified by three experts with Facial Action Coding System certification. Source code is provided in https://github.com/Necolizer/Facial-Prior-Based-FOMM.
Integrating Human Parsing and Pose Network for Human Action Recognition
Jul 16, 2023



Human skeletons and RGB sequences are both widely-adopted input modalities for human action recognition. However, skeletons lack appearance features and color data suffer large amount of irrelevant depiction. To address this, we introduce human parsing feature map as a novel modality, since it can selectively retain spatiotemporal features of the body parts, while filtering out noises regarding outfits, backgrounds, etc. We propose an Integrating Human Parsing and Pose Network (IPP-Net) for action recognition, which is the first to leverage both skeletons and human parsing feature maps in dual-branch approach. The human pose branch feeds compact skeletal representations of different modalities in graph convolutional network to model pose features. In human parsing branch, multi-frame body-part parsing features are extracted with human detector and parser, which is later learnt using a convolutional backbone. A late ensemble of two branches is adopted to get final predictions, considering both robust keypoints and rich semantic body-part features. Extensive experiments on NTU RGB+D and NTU RGB+D 120 benchmarks consistently verify the effectiveness of the proposed IPP-Net, which outperforms the existing action recognition methods. Our code is publicly available at https://github.com/liujf69/IPP-Net-Parsing .
Interactive Spatiotemporal Token Attention Network for Skeleton-based General Interactive Action Recognition
Jul 14, 2023Recognizing interactive action plays an important role in human-robot interaction and collaboration. Previous methods use late fusion and co-attention mechanism to capture interactive relations, which have limited learning capability or inefficiency to adapt to more interacting entities. With assumption that priors of each entity are already known, they also lack evaluations on a more general setting addressing the diversity of subjects. To address these problems, we propose an Interactive Spatiotemporal Token Attention Network (ISTA-Net), which simultaneously model spatial, temporal, and interactive relations. Specifically, our network contains a tokenizer to partition Interactive Spatiotemporal Tokens (ISTs), which is a unified way to represent motions of multiple diverse entities. By extending the entity dimension, ISTs provide better interactive representations. To jointly learn along three dimensions in ISTs, multi-head self-attention blocks integrated with 3D convolutions are designed to capture inter-token correlations. When modeling correlations, a strict entity ordering is usually irrelevant for recognizing interactive actions. To this end, Entity Rearrangement is proposed to eliminate the orderliness in ISTs for interchangeable entities. Extensive experiments on four datasets verify the effectiveness of ISTA-Net by outperforming state-of-the-art methods. Our code is publicly available at https://github.com/Necolizer/ISTA-Net
RM-PRT: Realistic Robotic Manipulation Simulator and Benchmark with Progressive Reasoning Tasks
Jun 21, 2023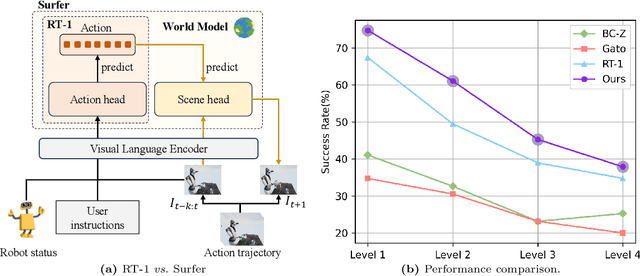

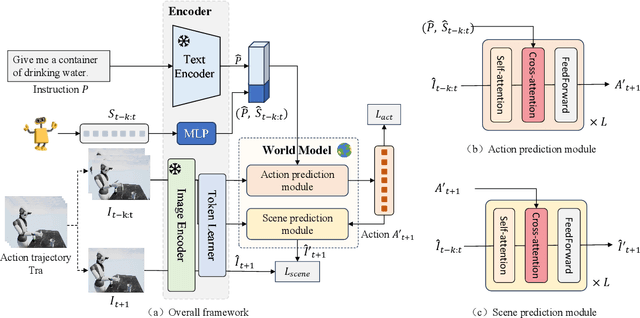
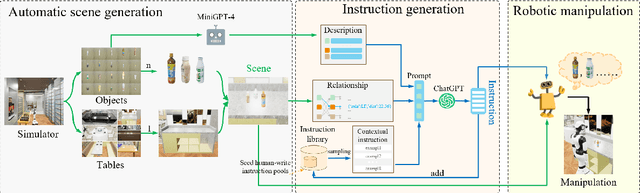
Recently, the advent of pre-trained large-scale language models (LLMs) like ChatGPT and GPT-4 have significantly advanced the machine's natural language understanding capabilities. This breakthrough has allowed us to seamlessly integrate these open-source LLMs into a unified robot simulator environment to help robots accurately understand and execute human natural language instructions. To this end, in this work, we introduce a realistic robotic manipulation simulator and build a Robotic Manipulation with Progressive Reasoning Tasks (RM-PRT) benchmark on this basis. Specifically, the RM-PRT benchmark builds a new high-fidelity digital twin scene based on Unreal Engine 5, which includes 782 categories, 2023 objects, and 15K natural language instructions generated by ChatGPT for a detailed evaluation of robot manipulation. We propose a general pipeline for the RM-PRT benchmark that takes as input multimodal prompts containing natural language instructions and automatically outputs actions containing the movement and position transitions. We set four natural language understanding tasks with progressive reasoning levels and evaluate the robot's ability to understand natural language instructions in two modes of adsorption and grasping. In addition, we also conduct a comprehensive analysis and comparison of the differences and advantages of 10 different LLMs in instruction understanding and generation quality. We hope the new simulator and benchmark will facilitate future research on language-guided robotic manipulation. Project website: https://necolizer.github.io/RM-PRT/ .