 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Shaper: A Unified Framework for 360° Panoramic Editing
Jan 30, 2026Being able to edit panoramic images is crucial for creating realistic 360° visual experiences. However, existing perspective-based image editing methods fail to model the spatial structure of panoramas. Conventional cube-map decompositions attempt to overcome this problem but inevitably break global consistency due to their mismatch with spherical geometry. Motivated by this insight, we reformulate panoramic editing directly in the equirectangular projection (ERP) domain and present World-Shaper, a unified geometry-aware framework that bridges panoramic generation and editing within a single editing-centric design. To overcome the scarcity of paired data, we adopt a generate-then-edit paradigm, where controllable panoramic generation serves as an auxiliary stage to synthesize diverse paired examples for supervised editing learning. To address geometric distortion, we introduce a geometry-aware learning strategy that explicitly enforces position-aware shape supervision and implicitly internalizes panoramic priors through progressive training. Extensive experiments on our new benchmark, PEBench, demonstrate that our method achieves superior geometric consistency, editing fidelity, and text controllability compared to SOTA methods, enabling coherent and flexible 360° visual world creation with unified editing control. Code, model, and data will be released at our project page: https://world-shaper-project.github.io/
Template-Free Retrosynthesis with Graph-Prior Augmented Transformers
Dec 15, 2025


Retrosynthesis reaction prediction aims to infer plausible reactant molecules for a given product and is a important problem in computer-aided organic synthesis. Despite recent progress, many existing models still fall short of the accuracy and robustness required for practical deployment. In this paper, we present a template-free, Transformer-based framework that removes the need for handcrafted reaction templates or additional chemical rule engines. Our model injects molecular graph information into the attention mechanism to jointly exploit SMILES sequences and structural cues, and further applies a paired data augmentation strategy to enhance training diversity and scale. Extensive experiments on the USPTO-50K benchmark demonstrate that our approach achieves state-of-the-art performance among template-free methods and substantially outperforms a vanilla Transformer baseline.
Hierarchical Cross-Modal Alignment for Open-Vocabulary 3D Object Detection
Mar 10, 2025



Open-vocabulary 3D object detection (OV-3DOD) aims at localizing and classifying novel objects beyond closed sets. The recent success of vision-language models (VLMs) has demonstrated their remarkable capabilities to understand open vocabularies. Existing works that leverage VLMs for 3D object detection (3DOD) generally resort to representations that lose the rich scene context required for 3D perception. To address this problem, we propose in this paper a hierarchical framework, named HCMA, to simultaneously learn local object and global scene information for OV-3DOD. Specifically, we first design a Hierarchical Data Integration (HDI) approach to obtain coarse-to-fine 3D-image-text data, which is fed into a VLM to extract object-centric knowledge. To facilitate the association of feature hierarchies, we then propose an Interactive Cross-Modal Alignment (ICMA) strategy to establish effective intra-level and inter-level feature connections. To better align features across different levels, we further propose an Object-Focusing Context Adjustment (OFCA) module to refine multi-level features by emphasizing object-related features. Extensive experiments demonstrate that the proposed method outperforms SOTA methods on the existing OV-3DOD benchmarks. It also achieves promising OV-3DOD results even without any 3D annotations.
OpenScan: A Benchmark for Generalized Open-Vocabulary 3D Scene Understanding
Aug 20, 2024



Open-vocabulary 3D scene understanding (OV-3D) aims to localize and classify novel objects beyond the closed object classes. However, existing approaches and benchmarks primarily focus on the open vocabulary problem within the context of object classes, which is insufficient to provide a holistic evaluation to what extent a model understands the 3D scene. In this paper, we introduce a more challenging task called Generalized Open-Vocabulary 3D Scene Understanding (GOV-3D) to explore the open vocabulary problem beyond object classes. It encompasses an open and diverse set of generalized knowledge, expressed as linguistic queries of fine-grained and object-specific attributes. To this end, we contribute a new benchmark named OpenScan, which consists of 3D object attributes across eight representative linguistic aspects, including affordance, property, material, and more. We further evaluate state-of-the-art OV-3D methods on our OpenScan benchmark, and discover that these methods struggle to comprehend the abstract vocabularies of the GOV-3D task, a challenge that cannot be addressed by simply scaling up object classes during training. We highlight the limitations of existing methodologies and explore a promising direction to overcome the identified shortcomings. Data and code are available at https://github.com/YoujunZhao/OpenScan
A Survey on Backbones for Deep Video Action Recognition
May 09, 2024
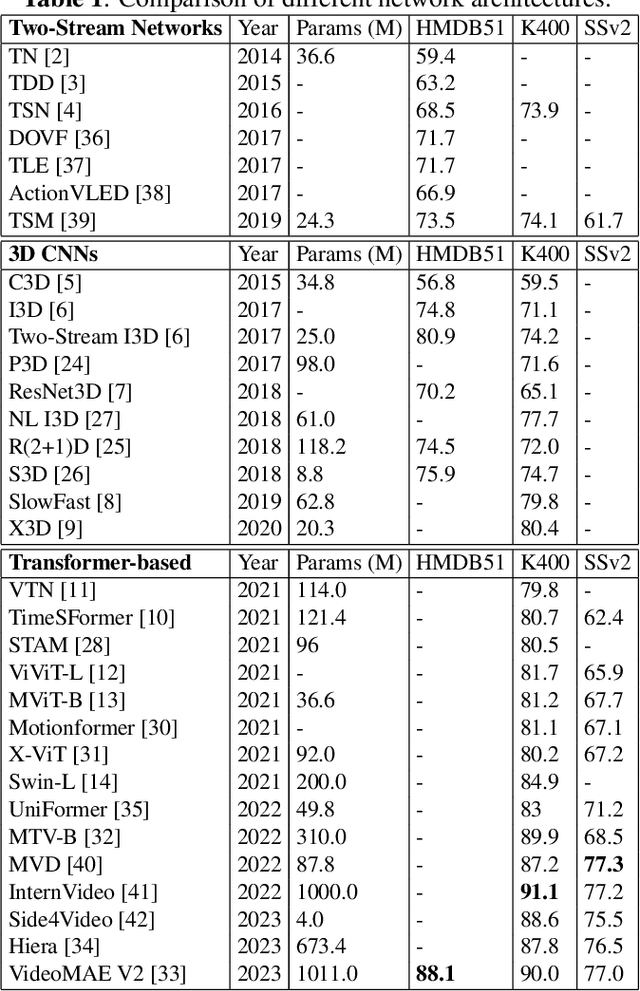
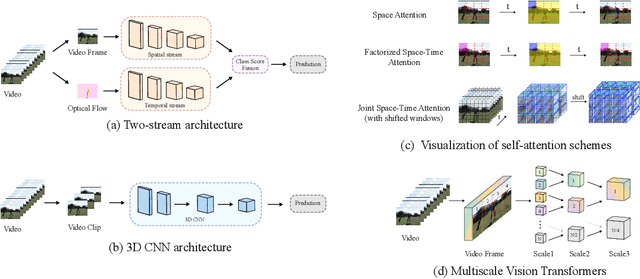
Action recognition is a key technology in building interactive metaverses. With the rapid development of deep learning, methods in action recognition have also achieved great advancement. Researchers design and implement the backbones referring to multiple standpoints, which leads to the diversity of methods and encountering new challenges. This paper reviews several action recognition methods based on deep neural networks. We introduce these methods in three parts: 1) Two-Streams networks and their variants, which, specifically in this paper, use RGB video frame and optical flow modality as input; 2) 3D convolutional networks, which make efforts in taking advantage of RGB modality directly while extracting different motion information is no longer necessary; 3) Transformer-based methods, which introduce the model from natural language processing into computer vision and video understanding. We offer objective sights in this review and hopefully provide a reference for future research.
Facial Prior Based First Order Motion Model for Micro-expression Generation
Aug 08, 2023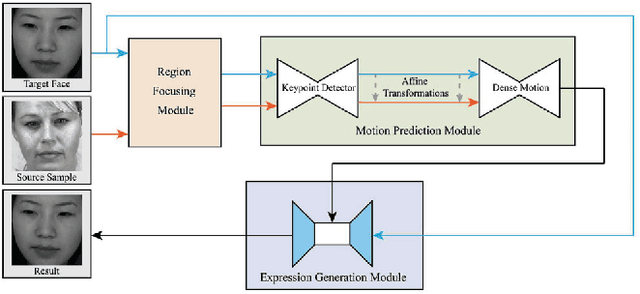
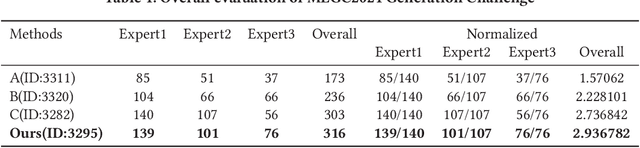

Spotting facial micro-expression from videos finds various potential applications in fields including clinical diagnosis and interrogation, meanwhile this task is still difficult due to the limited scale of training data. To solve this problem, this paper tries to formulate a new task called micro-expression generation and then presents a strong baseline which combines the first order motion model with facial prior knowledge. Given a target face, we intend to drive the face to generate micro-expression videos according to the motion patterns of source videos. Specifically, our new model involves three modules. First, we extract facial prior features from a region focusing module. Second, we estimate facial motion using key points and local affine transformations with a motion prediction module. Third, expression generation module is used to drive the target face to generate videos. We train our model on public CASME II, SAMM and SMIC datasets and then use the model to generate new micro-expression videos for evaluation. Our model achieves the first place in the Facial Micro-Expression Challenge 2021 (MEGC2021), where our superior performance is verified by three experts with Facial Action Coding System certification. Source code is provided in https://github.com/Necolizer/Facial-Prior-Based-FOMM.