 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Backbones for Deep Video Action Recognition
May 09, 2024
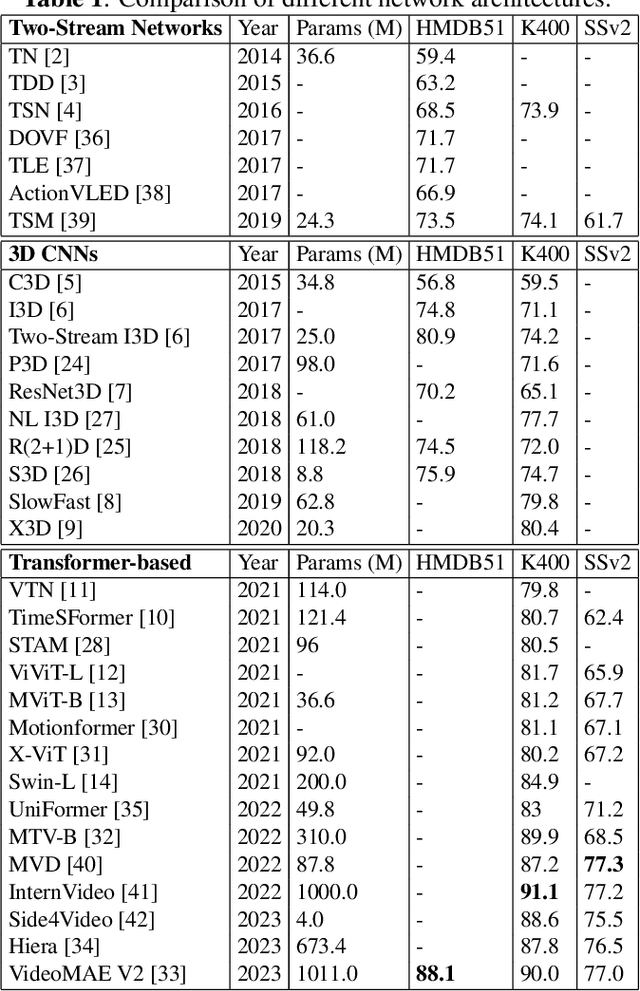
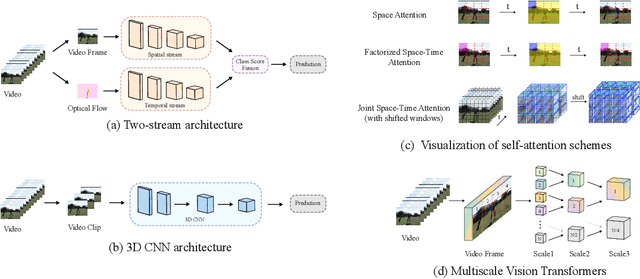
Action recognition is a key technology in building interactive metaverses. With the rapid development of deep learning, methods in action recognition have also achieved great advancement. Researchers design and implement the backbones referring to multiple standpoints, which leads to the diversity of methods and encountering new challenges. This paper reviews several action recognition methods based on deep neural networks. We introduce these methods in three parts: 1) Two-Streams networks and their variants, which, specifically in this paper, use RGB video frame and optical flow modality as input; 2) 3D convolutional networks, which make efforts in taking advantage of RGB modality directly while extracting different motion information is no longer necessary; 3) Transformer-based methods, which introduce the model from natural language processing into computer vision and video understanding. We offer objective sights in this review and hopefully provide a reference for future research.
Facial Prior Based First Order Motion Model for Micro-expression Generation
Aug 08, 2023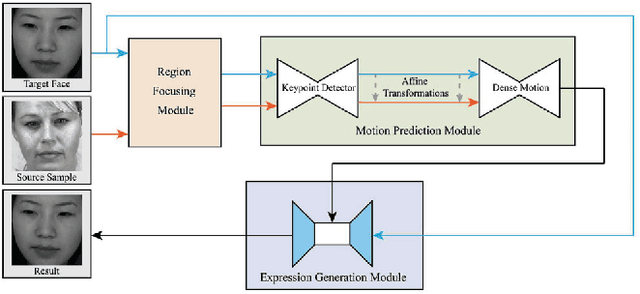
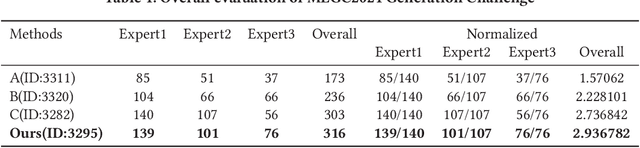

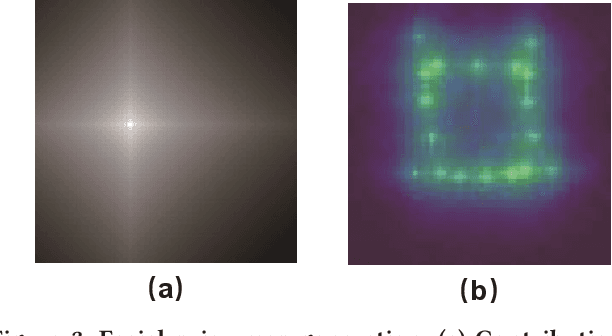
Spotting facial micro-expression from videos finds various potential applications in fields including clinical diagnosis and interrogation, meanwhile this task is still difficult due to the limited scale of training data. To solve this problem, this paper tries to formulate a new task called micro-expression generation and then presents a strong baseline which combines the first order motion model with facial prior knowledge. Given a target face, we intend to drive the face to generate micro-expression videos according to the motion patterns of source videos. Specifically, our new model involves three modules. First, we extract facial prior features from a region focusing module. Second, we estimate facial motion using key points and local affine transformations with a motion prediction module. Third, expression generation module is used to drive the target face to generate videos. We train our model on public CASME II, SAMM and SMIC datasets and then use the model to generate new micro-expression videos for evaluation. Our model achieves the first place in the Facial Micro-Expression Challenge 2021 (MEGC2021), where our superior performance is verified by three experts with Facial Action Coding System certification. Source code is provided in https://github.com/Necolizer/Facial-Prior-Based-FOMM.
Interactive Spatiotemporal Token Attention Network for Skeleton-based General Interactive Action Recognition
Jul 14, 2023Recognizing interactive action plays an important role in human-robot interaction and collaboration. Previous methods use late fusion and co-attention mechanism to capture interactive relations, which have limited learning capability or inefficiency to adapt to more interacting entities. With assumption that priors of each entity are already known, they also lack evaluations on a more general setting addressing the diversity of subjects. To address these problems, we propose an Interactive Spatiotemporal Token Attention Network (ISTA-Net), which simultaneously model spatial, temporal, and interactive relations. Specifically, our network contains a tokenizer to partition Interactive Spatiotemporal Tokens (ISTs), which is a unified way to represent motions of multiple diverse entities. By extending the entity dimension, ISTs provide better interactive representations. To jointly learn along three dimensions in ISTs, multi-head self-attention blocks integrated with 3D convolutions are designed to capture inter-token correlations. When modeling correlations, a strict entity ordering is usually irrelevant for recognizing interactive actions. To this end, Entity Rearrangement is proposed to eliminate the orderliness in ISTs for interchangeable entities. Extensive experiments on four datasets verify the effectiveness of ISTA-Net by outperforming state-of-the-art methods. Our code is publicly available at https://github.com/Necolizer/ISTA-Net