 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising-GS: Gaussian Splatting with Spatial-aware Denoising
May 14, 2026Recent advances in 3D Gaussian Splatting (3DGS) have achieved remarkable success in high-fidelity Novel View Synthesis (NVS), yet the optimization process inevitably introduces noisy Gaussian primitives due to the sparse and incomplete initialization from Structure-from-Motion (SfM) point clouds. Most existing methods focus solely on adjusting the positions of primitives during optimization, while neglecting the underlying spatial structure. To this end, we introduce a new perspective by formulating the optimization of 3DGS as a primitive denoising process and propose Denoising-GS, a spatial-aware denoising framework for Gaussian primitives by taking both the positions and spatial structure into consideration. Specifically, we design an optimizer that preserves the spatial optimization flow of primitives, facilitating coherent and directed denoising rather than random perturbations. Building upon this, the Spatial Gradient-based Denoising strategy jointly considers the spatial supports of primitives to ensure gradient-consistent updates. Furthermore, the Uncertainty-based Denoising module estimates primitive-wise uncertainty to prune redundant or noisy primitives, while the Spatial Coherence Refinement strategy selectively splits primitives in sparse regions to maintain structural completeness. Experiments conducted on three benchmark datasets demonstrate that Denoising-GS consistently enhances NVS fidelity while maintaining representation compactness, achieving state-of-the-art performance across all benchmarks. Source code and models will be made publicly available.
Do Multimodal Large Language Models See Like Humans?
Dec 12, 2024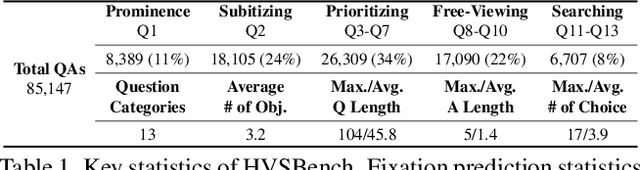

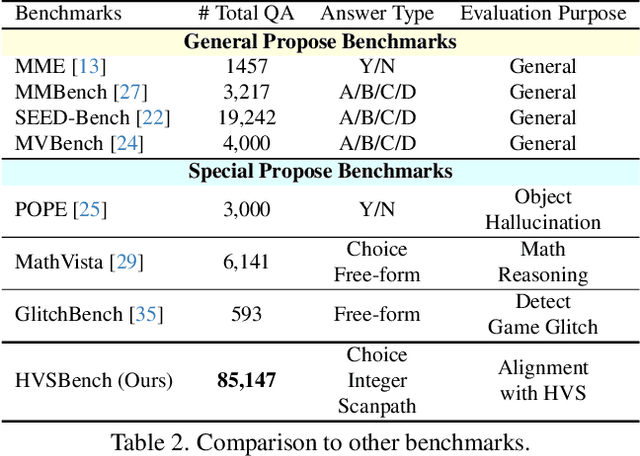

Multimodal Large Language Models (MLLMs) have achieved impressive results on various vision tasks, leveraging recent advancements in large language models. However, a critical question remains unaddressed: do MLLMs perceive visual information similarly to humans? Current benchmarks lack the ability to evaluate MLLMs from this perspective. To address this challenge, we introduce HVSBench, a large-scale benchmark designed to assess the alignment between MLLMs and the human visual system (HVS) on fundamental vision tasks that mirror human vision. HVSBench curated over 85K multimodal samples, spanning 13 categories and 5 fields in HVS, including Prominence, Subitizing, Prioritizing, Free-Viewing, and Searching. Extensive experiments demonstrate the effectiveness of our benchmark in providing a comprehensive evaluation of MLLMs. Specifically, we evaluate 13 MLLMs, revealing that even the best models show significant room for improvement, with most achieving only moderate results. Our experiments reveal that HVSBench presents a new and significant challenge for cutting-edge MLLMs. We believe that HVSBench will facilitate research on human-aligned and explainable MLLMs, marking a key step in understanding how MLLMs perceive and process visual information.
OpenScan: A Benchmark for Generalized Open-Vocabulary 3D Scene Understanding
Aug 20, 2024



Open-vocabulary 3D scene understanding (OV-3D) aims to localize and classify novel objects beyond the closed object classes. However, existing approaches and benchmarks primarily focus on the open vocabulary problem within the context of object classes, which is insufficient to provide a holistic evaluation to what extent a model understands the 3D scene. In this paper, we introduce a more challenging task called Generalized Open-Vocabulary 3D Scene Understanding (GOV-3D) to explore the open vocabulary problem beyond object classes. It encompasses an open and diverse set of generalized knowledge, expressed as linguistic queries of fine-grained and object-specific attributes. To this end, we contribute a new benchmark named OpenScan, which consists of 3D object attributes across eight representative linguistic aspects, including affordance, property, material, and more. We further evaluate state-of-the-art OV-3D methods on our OpenScan benchmark, and discover that these methods struggle to comprehend the abstract vocabularies of the GOV-3D task, a challenge that cannot be addressed by simply scaling up object classes during training. We highlight the limitations of existing methodologies and explore a promising direction to overcome the identified shortcomings. Data and code are available at https://github.com/YoujunZhao/OpenScan
Robust Point Cloud Segmentation with Noisy Annotations
Dec 06, 2022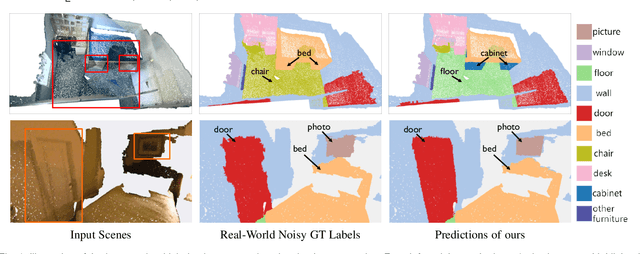

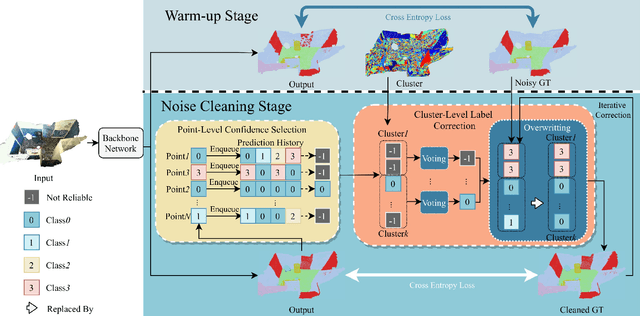
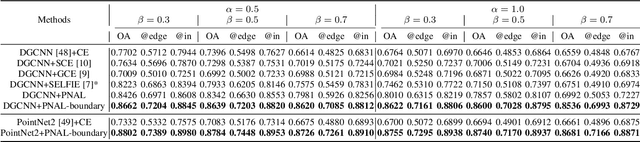
Point cloud segmentation is a fundamental task in 3D. Despite recent progress on point cloud segmentation with the power of deep networks, current learning methods based on the clean label assumptions may fail with noisy labels. Yet, class labels are often mislabeled at both instance-level and boundary-level in real-world datasets. In this work, we take the lead in solving the instance-level label noise by proposing a Point Noise-Adaptive Learning (PNAL) framework. Compared to noise-robust methods on image tasks, our framework is noise-rate blind, to cope with the spatially variant noise rate specific to point clouds. Specifically, we propose a point-wise confidence selection to obtain reliable labels from the historical predictions of each point. A cluster-wise label correction is proposed with a voting strategy to generate the best possible label by considering the neighbor correlations. To handle boundary-level label noise, we also propose a variant ``PNAL-boundary " with a progressive boundary label cleaning strategy. Extensive experiments demonstrate its effectiveness on both synthetic and real-world noisy datasets. Even with $60\%$ symmetric noise and high-level boundary noise, our framework significantly outperforms its baselines, and is comparable to the upper bound trained on completely clean data. Moreover, we cleaned the popular real-world dataset ScanNetV2 for rigorous experiment. Our code and data is available at https://github.com/pleaseconnectwifi/PNAL.
Improving Commonsense in Vision-Language Models via Knowledge Graph Riddles
Nov 29, 2022This paper focuses on analyzing and improving the commonsense ability of recent popular vision-language (VL) models. Despite the great success, we observe that existing VL-models still lack commonsense knowledge/reasoning ability (e.g., "Lemons are sour"), which is a vital component towards artificial general intelligence. Through our analysis, we find one important reason is that existing large-scale VL datasets do not contain much commonsense knowledge, which motivates us to improve the commonsense of VL-models from the data perspective. Rather than collecting a new VL training dataset, we propose a more scalable strategy, i.e., "Data Augmentation with kNowledge graph linearization for CommonsensE capability" (DANCE). It can be viewed as one type of data augmentation technique, which can inject commonsense knowledge into existing VL datasets on the fly during training. More specifically, we leverage the commonsense knowledge graph (e.g., ConceptNet) and create variants of text description in VL datasets via bidirectional sub-graph sequentialization. For better commonsense evaluation, we further propose the first retrieval-based commonsense diagnostic benchmark. By conducting extensive experiments on some representative VL-models, we demonstrate that our DANCE technique is able to significantly improve the commonsense ability while maintaining the performance on vanilla retrieval tasks. The code and data are available at https://github.com/pleaseconnectwifi/DANCE
3D Question Answering
Dec 15, 2021

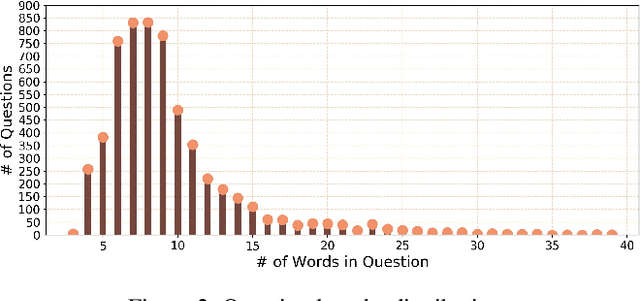

Visual Question Answering (VQA) has witnessed tremendous progress in recent years. However, most efforts only focus on the 2D image question answering tasks. In this paper, we present the first attempt at extending VQA to the 3D domain, which can facilitate artificial intelligence's perception of 3D real-world scenarios. Different from image based VQA, 3D Question Answering (3DQA) takes the color point cloud as input and requires both appearance and 3D geometry comprehension ability to answer the 3D-related questions. To this end, we propose a novel transformer-based 3DQA framework \textbf{``3DQA-TR"}, which consists of two encoders for exploiting the appearance and geometry information, respectively. The multi-modal information of appearance, geometry, and the linguistic question can finally attend to each other via a 3D-Linguistic Bert to predict the target answers. To verify the effectiveness of our proposed 3DQA framework, we further develop the first 3DQA dataset \textbf{``ScanQA"}, which builds on the ScanNet dataset and contains $\sim$6K questions, $\sim$30K answers for $806$ scenes. Extensive experiments on this dataset demonstrate the obvious superiority of our proposed 3DQA framework over existing VQA frameworks, and the effectiveness of our major designs. Our code and dataset will be made publicly available to facilitate the research in this direction.
Learning with Noisy Labels for Robust Point Cloud Segmentation
Aug 05, 2021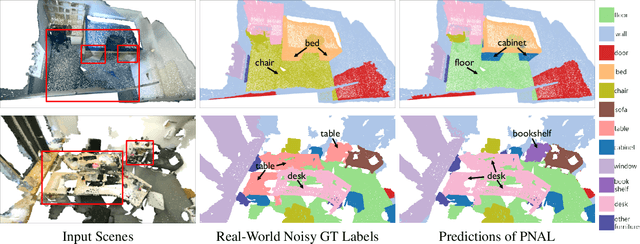
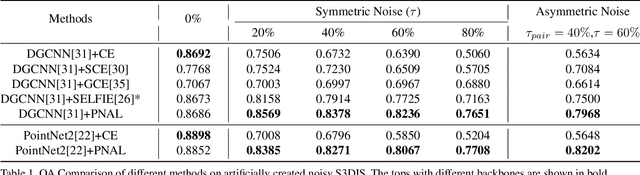
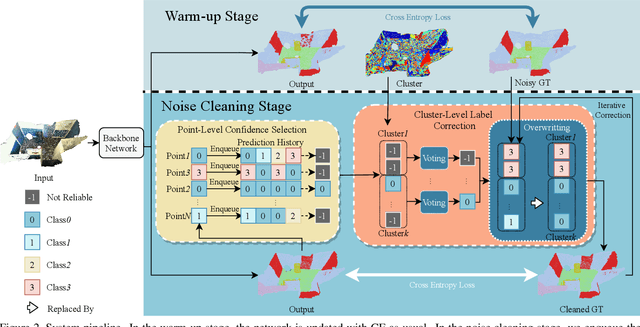
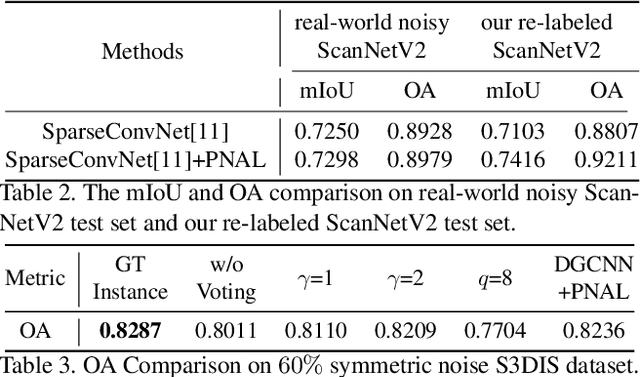
Point cloud segmentation is a fundamental task in 3D. Despite recent progress on point cloud segmentation with the power of deep networks, current deep learning methods based on the clean label assumptions may fail with noisy labels. Yet, object class labels are often mislabeled in real-world point cloud datasets. In this work, we take the lead in solving this issue by proposing a novel Point Noise-Adaptive Learning (PNAL) framework. Compared to existing noise-robust methods on image tasks, our PNAL is noise-rate blind, to cope with the spatially variant noise rate problem specific to point clouds. Specifically, we propose a novel point-wise confidence selection to obtain reliable labels based on the historical predictions of each point. A novel cluster-wise label correction is proposed with a voting strategy to generate the best possible label taking the neighbor point correlations into consideration. We conduct extensive experiments to demonstrate the effectiveness of PNAL on both synthetic and real-world noisy datasets. In particular, even with $60\%$ symmetric noisy labels, our proposed method produces much better results than its baseline counterpart without PNAL and is comparable to the ideal upper bound trained on a completely clean dataset. Moreover, we fully re-labeled the validation set of a popular but noisy real-world scene dataset ScanNetV2 to make it clean, for rigorous experiment and future research. Our code and data are available at \url{https://shuquanye.com/PNAL_website/}.
Exemplar-Based 3D Portrait Stylization
Apr 29, 2021

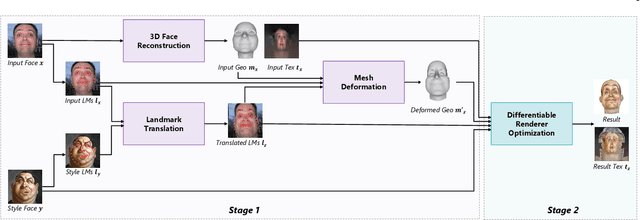

Exemplar-based portrait stylization is widely attractive and highly desired. Despite recent successes, it remains challenging, especially when considering both texture and geometric styles. In this paper, we present the first framework for one-shot 3D portrait style transfer, which can generate 3D face models with both the geometry exaggerated and the texture stylized while preserving the identity from the original content. It requires only one arbitrary style image instead of a large set of training examples for a particular style, provides geometry and texture outputs that are fully parameterized and disentangled, and enables further graphics applications with the 3D representations. The framework consists of two stages. In the first geometric style transfer stage, we use facial landmark translation to capture the coarse geometry style and guide the deformation of the dense 3D face geometry. In the second texture style transfer stage, we focus on performing style transfer on the canonical texture by adopting a differentiable renderer to optimize the texture in a multi-view framework. Experiments show that our method achieves robustly good results on different artistic styles and outperforms existing methods. We also demonstrate the advantages of our method via various 2D and 3D graphics applications. Project page is https://halfjoe.github.io/projs/3DPS/index.html.