 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Multimodal Large Language Models See Like Humans?
Paper and Code
Dec 12, 2024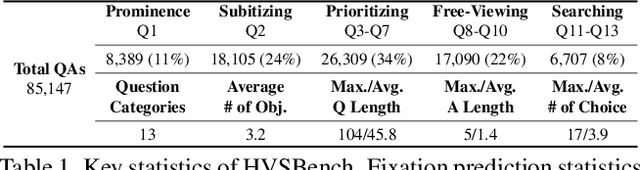

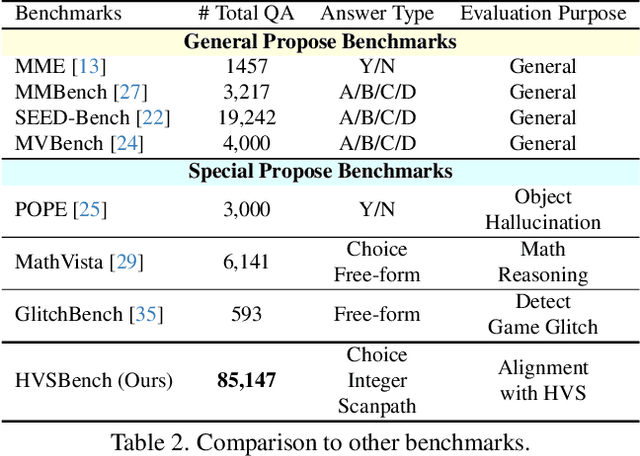

Multimodal Large Language Models (MLLMs) have achieved impressive results on various vision tasks, leveraging recent advancements in large language models. However, a critical question remains unaddressed: do MLLMs perceive visual information similarly to humans? Current benchmarks lack the ability to evaluate MLLMs from this perspective. To address this challenge, we introduce HVSBench, a large-scale benchmark designed to assess the alignment between MLLMs and the human visual system (HVS) on fundamental vision tasks that mirror human vision. HVSBench curated over 85K multimodal samples, spanning 13 categories and 5 fields in HVS, including Prominence, Subitizing, Prioritizing, Free-Viewing, and Searching. Extensive experiments demonstrate the effectiveness of our benchmark in providing a comprehensive evaluation of MLLMs. Specifically, we evaluate 13 MLLMs, revealing that even the best models show significant room for improvement, with most achieving only moderate results. Our experiments reveal that HVSBench presents a new and significant challenge for cutting-edge MLLMs. We believe that HVSBench will facilitate research on human-aligned and explainable MLLMs, marking a key step in understanding how MLLMs perceive and process visual information.