 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Question Answering
Paper and Code
Dec 15, 2021

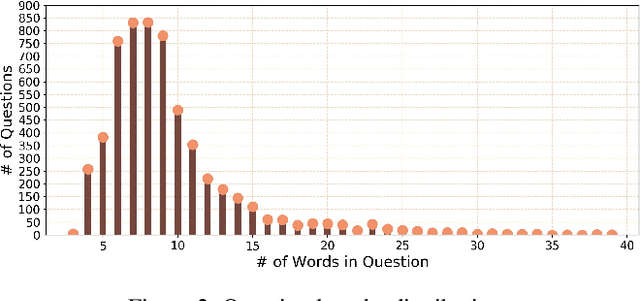

Visual Question Answering (VQA) has witnessed tremendous progress in recent years. However, most efforts only focus on the 2D image question answering tasks. In this paper, we present the first attempt at extending VQA to the 3D domain, which can facilitate artificial intelligence's perception of 3D real-world scenarios. Different from image based VQA, 3D Question Answering (3DQA) takes the color point cloud as input and requires both appearance and 3D geometry comprehension ability to answer the 3D-related questions. To this end, we propose a novel transformer-based 3DQA framework \textbf{``3DQA-TR"}, which consists of two encoders for exploiting the appearance and geometry information, respectively. The multi-modal information of appearance, geometry, and the linguistic question can finally attend to each other via a 3D-Linguistic Bert to predict the target answers. To verify the effectiveness of our proposed 3DQA framework, we further develop the first 3DQA dataset \textbf{``ScanQA"}, which builds on the ScanNet dataset and contains $\sim$6K questions, $\sim$30K answers for $806$ scenes. Extensive experiments on this dataset demonstrate the obvious superiority of our proposed 3DQA framework over existing VQA frameworks, and the effectiveness of our major designs. Our code and dataset will be made publicly available to facilitate the research in this direction.