 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Linearization: Attributed Table Graphs for Table Reasoning
Jan 13, 2026Table reasoning, a task to answer questions by reasoning over data presented in tables, is an important topic due to the prevalence of knowledge stored in tabular formats. Recent solutions use Large Language Models (LLMs), exploiting the semantic understanding and reasoning capabilities of LLMs. A common paradigm of such solutions linearizes tables to form plain texts that are served as input to LLMs. This paradigm has critical issues. It loses table structures, lacks explicit reasoning paths for result explainability, and is subject to the "lost-in-the-middle" issue. To address these issues, we propose Table Graph Reasoner (TABGR), a training-free model that represents tables as an Attributed Table Graph (ATG). The ATG explicitly preserves row-column-cell structures while enabling graph-based reasoning for explainability. We further propose a Question-Guided Personalized PageRank (QG-PPR) mechanism to rerank tabular data and mitigate the lost-in-the-middle issue. Extensive experiments on two commonly used benchmarks show that TABGR consistently outperforms state-of-the-art models by up to 9.7% in accuracy. Our code will be made publicly available upon publication.
CtrTab: Tabular Data Synthesis with High-Dimensional and Limited Data
Mar 09, 2025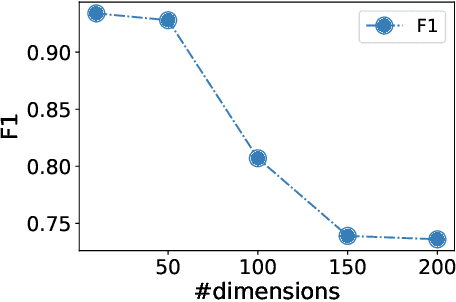
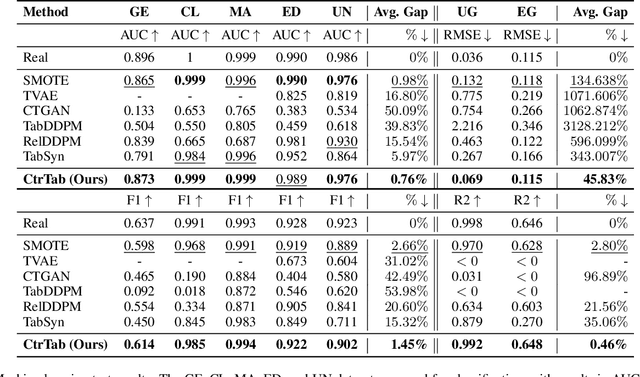
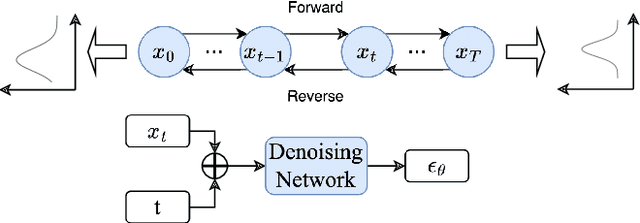
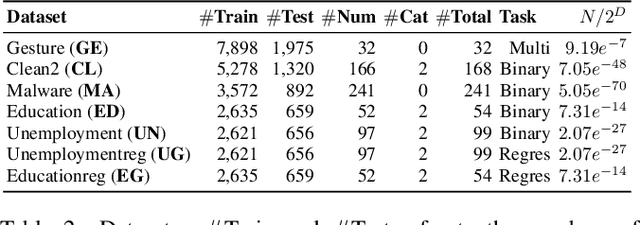
Diffusion-based tabular data synthesis models have yielded promising results. However, we observe that when the data dimensionality increases, existing models tend to degenerate and may perform even worse than simpler, non-diffusion-based models. This is because limited training samples in high-dimensional space often hinder generative models from capturing the distribution accurately. To address this issue, we propose CtrTab-a condition controlled diffusion model for tabular data synthesis-to improve the performance of diffusion-based generative models in high-dimensional, low-data scenarios. Through CtrTab, we inject samples with added Laplace noise as control signals to improve data diversity and show its resemblance to L2 regularization, which enhances model robustness. Experimental results across multiple datasets show that CtrTab outperforms state-of-the-art models, with performance gap in accuracy over 80% on average. Our source code will be released upon paper publication.
Intrinsic and Extrinsic Factor Disentanglement for Recommendation in Various Context Scenarios
Mar 05, 2025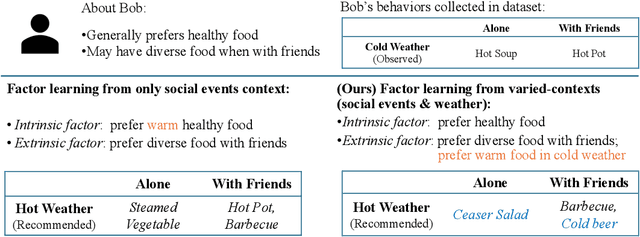
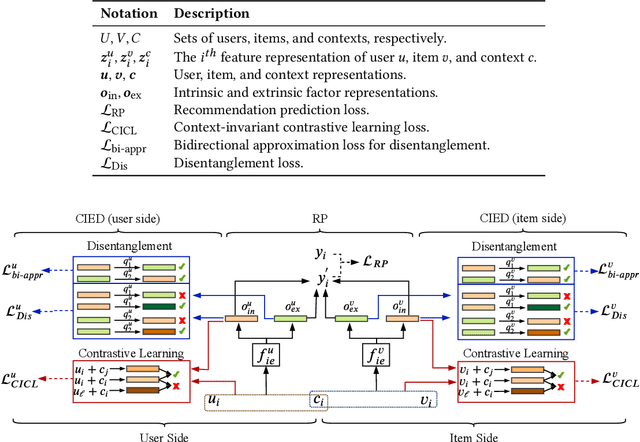
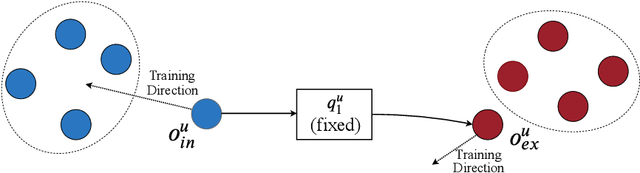
In recommender systems, the patterns of user behaviors (e.g., purchase, click) may vary greatly in different contexts (e.g., time and location). This is because user behavior is jointly determined by two types of factors: intrinsic factors, which reflect consistent user preference, and extrinsic factors, which reflect external incentives that may vary in different contexts. Differentiating between intrinsic and extrinsic factors helps learn user behaviors better. However, existing studies have only considered differentiating them from a single, pre-defined context (e.g., time or location), ignoring the fact that a user's extrinsic factors may be influenced by the interplay of various contexts at the same time. In this paper, we propose the Intrinsic-Extrinsic Disentangled Recommendation (IEDR) model, a generic framework that differentiates intrinsic from extrinsic factors considering various contexts simultaneously, enabling more accurate differentiation of factors and hence the improvement of recommendation accuracy. IEDR contains a context-invariant contrastive learning component to capture intrinsic factors, and a disentanglement component to extract extrinsic factors under the interplay of various contexts. The two components work together to achieve effective factor learning. Extensive experiments on real-world datasets demonstrate IEDR's effectiveness in learning disentangled factors and significantly improving recommendation accuracy by up to 4% in NDCG.
TabSD: Large Free-Form Table Question Answering with SQL-Based Table Decomposition
Feb 19, 2025Question answering on free-form tables (TableQA) is challenging due to the absence of predefined schemas and the presence of noise in large tables. While Large Language Models (LLMs) have shown promise in TableQA, they struggle with large free-form tables and noise sensitivity. To address these challenges, we propose TabSD, a SQL-based decomposition model that enhances LLMs' ability to process large free-form tables. TabSD generates SQL queries to guide the table decomposition, remove noise, and processes sub-tables for better answer generation. Additionally, SQL Verifier refines SQL outputs to enhance decomposition accuracy. We introduce two TableQA datasets with large free-form tables, SLQA and SEQA, which consist solely of large free-form tables and will be publicly available. Experimental results on four benchmark datasets demonstrate that TABSD outperforms the best-existing baseline models by 23.07%, 2.84%, 23.24% and 9.32% in accuracy, respectively, highlighting its effectiveness in handling large and noisy free-form tables.
Accurate and Regret-aware Numerical Problem Solver for Tabular Question Answering
Oct 10, 2024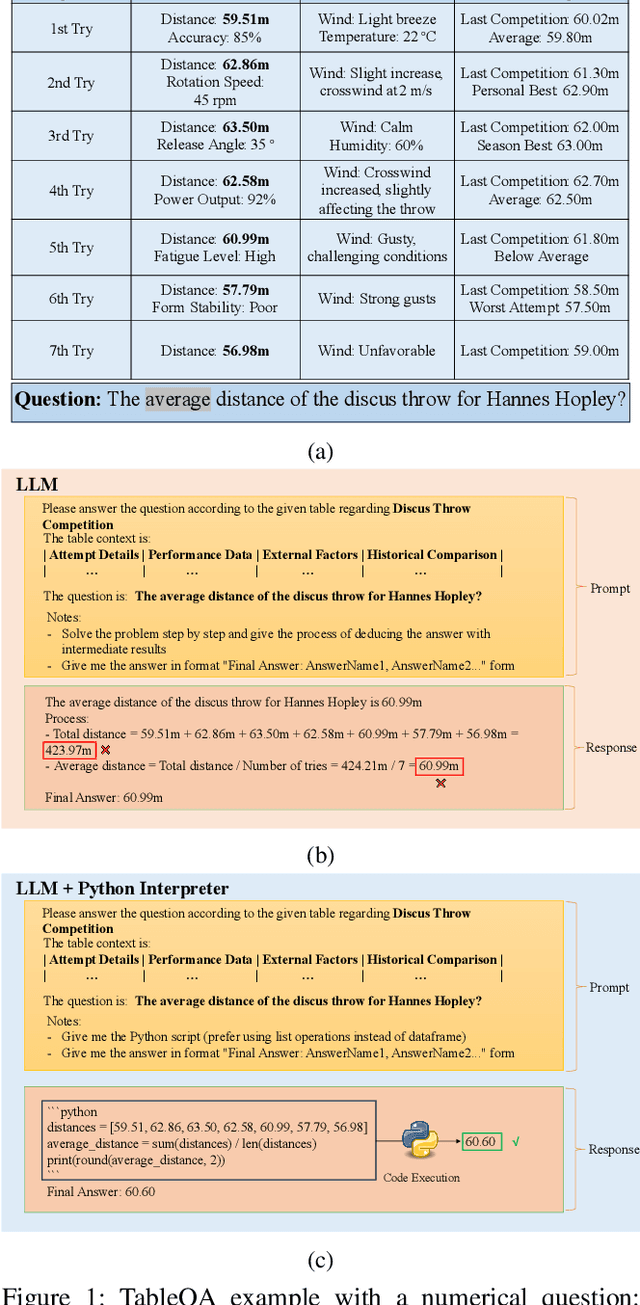
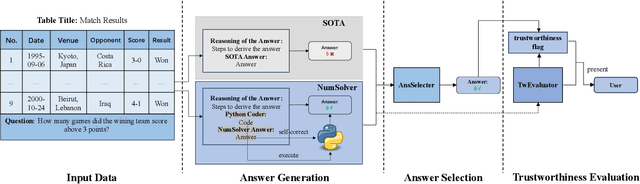
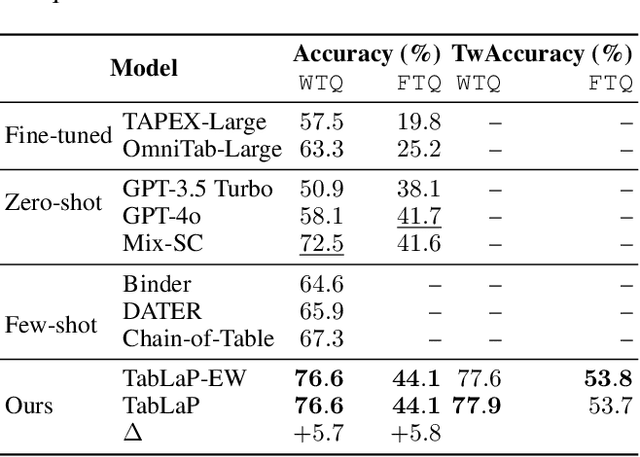
Question answering on free-form tables (a.k.a. TableQA) is a challenging task because of the flexible structure and the complex schema of tables. Recent studies use Large Language Models (LLMs) for this task, exploiting their capability in understanding the questions and tabular data which are typically given in natural language and contains many textual fields, respectively. While this approach has shown promising results, it overlooks the challenges brought by numerical values which are common in tabular data, while LLMs are known to struggle with such values. We aim to address this issue and answer numerical questions. We propose a model named TabLaP that uses LLMs as a planner rather than an answer generator, exploiting LLMs capability in multi-step reasoning while leaving the actual numerical calculations to a Python interpreter for accurate calculation. Recognizing the inaccurate nature of LLMs, we further make a first attempt to quantify the trustworthiness of the answers produced by TabLaP, such that users can use TabLaP in a regret-aware manner. Experimental results on two benchmark datasets show that TabLaP is substantially more accurate than the state-of-the-art models, improving the answer accuracy by 5.7% and 5.8% on the two datasets, respectively.
Detecting Arbitrary Order Beneficial Feature Interactions for Recommender Systems
Jun 28, 2022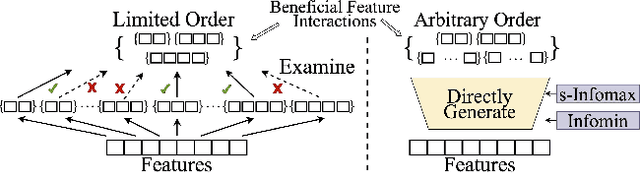
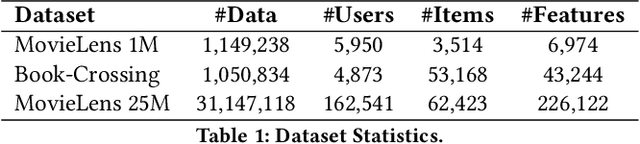
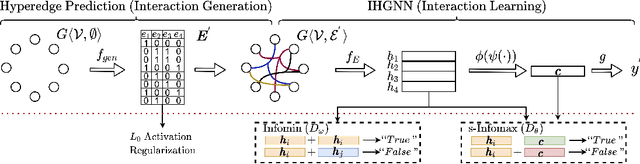
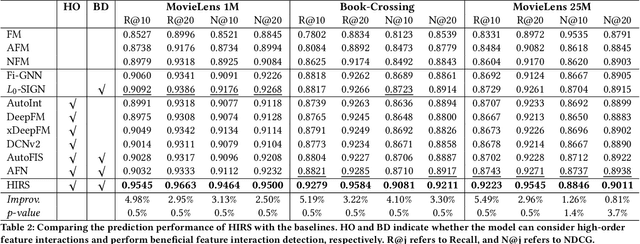
Detecting beneficial feature interactions is essential in recommender systems, and existing approaches achieve this by examining all the possible feature interactions. However, the cost of examining all the possible higher-order feature interactions is prohibitive (exponentially growing with the order increasing). Hence existing approaches only detect limited order (e.g., combinations of up to four features) beneficial feature interactions, which may miss beneficial feature interactions with orders higher than the limitation. In this paper, we propose a hypergraph neural network based model named HIRS. HIRS is the first work that directly generates beneficial feature interactions of arbitrary orders and makes recommendation predictions accordingly. The number of generated feature interactions can be specified to be much smaller than the number of all the possible interactions and hence, our model admits a much lower running time. To achieve an effective algorithm, we exploit three properties of beneficial feature interactions, and propose deep-infomax-based methods to guide the interaction generation. Our experimental results show that HIRS outperforms state-of-the-art algorithms by up to 5% in terms of recommendation accuracy.
Neural Graph Matching based Collaborative Filtering
May 10, 2021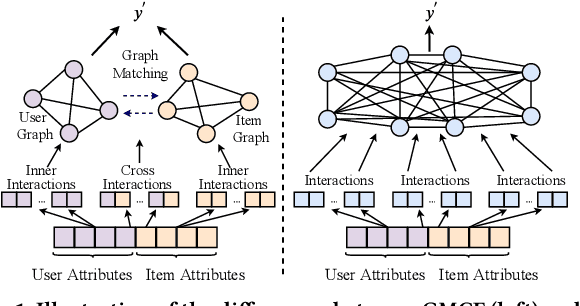
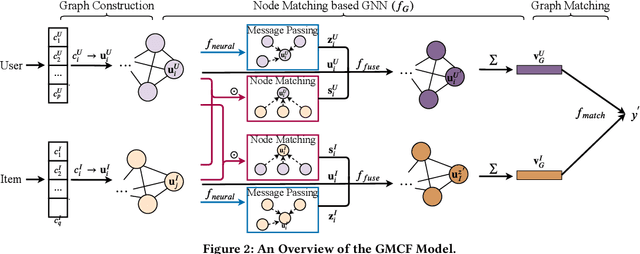
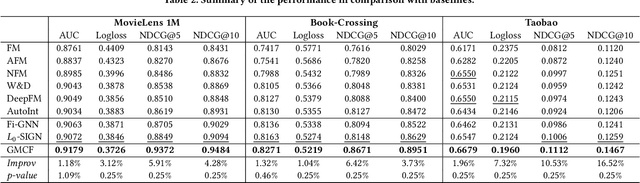
User and item attributes are essential side-information; their interactions (i.e., their co-occurrence in the sample data) can significantly enhance prediction accuracy in various recommender systems. We identify two different types of attribute interactions, inner interactions and cross interactions: inner interactions are those between only user attributes or those between only item attributes; cross interactions are those between user attributes and item attributes. Existing models do not distinguish these two types of attribute interactions, which may not be the most effective way to exploit the information carried by the interactions. To address this drawback, we propose a neural Graph Matching based Collaborative Filtering model (GMCF), which effectively captures the two types of attribute interactions through modeling and aggregating attribute interactions in a graph matching structure for recommendation. In our model, the two essential recommendation procedures, characteristic learning and preference matching, are explicitly conducted through graph learning (based on inner interactions) and node matching (based on cross interactions), respectively. Experimental results show that our model outperforms state-of-the-art models. Further studies verify the effectiveness of GMCF in improving the accuracy of recommendation.