 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Future of Skill: What Is It to Be Skilled at Work?
Nov 14, 2024

In this short paper, we introduce work that is aiming to purposefully venture into this mesh of questions from a different starting point. Interjecting into the conversation, we want to ask: 'What is it to be skilled at work?' Building on work from scholars like Tim Ingold, and strands of longstanding research in workplace studies and CSCW, our interest is in turning the attention to the active work of 'being good', or 'being skilled', at what we as workers do. As we see it, skill provides a counterpoint to the version of intelligence that appears to be easily blackboxed in systems like Slack, and that ultimately reduces much of what people do to work well together. To put it slightly differently, skill - as we will argue below - gives us a way into thinking about work as a much more entangled endeavour, unfolding through multiple and interweaving sets of practices, places, tools and collaborations. In this vein, designing for the future of work seems to be about much more than where work is done or how we might bolt on discrete containers of intelligence. More fruitful would be attending to how we succeed in threading so many entities together to do our jobs well - in 'coming to be skilled'.
Making Data Work Count
Nov 29, 2023In this paper, we examine the work of data annotation. Specifically, we focus on the role of counting or quantification in organising annotation work. Based on an ethnographic study of data annotation in two outsourcing centres in India, we observe that counting practices and its associated logics are an integral part of day-to-day annotation activities. In particular, we call attention to the presumption of total countability observed in annotation - the notion that everything, from tasks, datasets and deliverables, to workers, work time, quality and performance, can be managed by applying the logics of counting. To examine this, we draw on sociological and socio-technical scholarship on quantification and develop the lens of a 'regime of counting' that makes explicit the specific counts, practices, actors and structures that underpin the pervasive counting in annotation. We find that within the AI supply chain and data work, counting regimes aid the assertion of authority by the AI clients (also called requesters) over annotation processes, constituting them as reductive, standardised, and homogenous. We illustrate how this has implications for i) how annotation work and workers get valued, ii) the role human discretion plays in annotation, and iii) broader efforts to introduce accountable and more just practices in AI. Through these implications, we illustrate the limits of operating within the logic of total countability. Instead, we argue for a view of counting as partial - located in distinct geographies, shaped by specific interests and accountable in only limited ways. This, we propose, sets the stage for a fundamentally different orientation to counting and what counts in data annotation.
A Framework to Assess agreement Among Diverse Rater Groups
Nov 09, 2023Recent advancements in conversational AI have created an urgent need for safety guardrails that prevent users from being exposed to offensive and dangerous content. Much of this work relies on human ratings and feedback, but does not account for the fact that perceptions of offense and safety are inherently subjective and that there may be systematic disagreements between raters that align with their socio-demographic identities. Instead, current machine learning approaches largely ignore rater subjectivity and use gold standards that obscure disagreements (e.g., through majority voting). In order to better understand the socio-cultural leanings of such tasks, we propose a comprehensive disagreement analysis framework to measure systematic diversity in perspectives among different rater subgroups. We then demonstrate its utility by applying this framework to a dataset of human-chatbot conversations rated by a demographically diverse pool of raters. Our analysis reveals specific rater groups that have more diverse perspectives than the rest, and informs demographic axes that are crucial to consider for safety annotations.
DICE: Data-Efficient Clinical Event Extraction with Generative Models
Aug 16, 2022


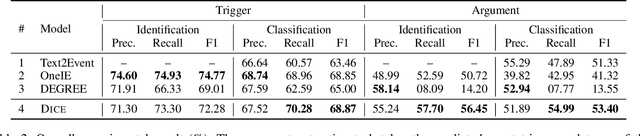
Event extraction in the clinical domain is an under-explored research area. The lack of training data in addition to the high volume of domain-specific jargon that includes long entities with vague boundaries make the task especially challenging. In this paper, we introduce DICE, a robust and data-efficient generative model for clinical event extraction. DICE frames event extraction as a conditional generation problem and utilizes descriptions provided by domain experts to boost the performance under low-resource settings. Furthermore, DICE learns to locate and bound biomedical mentions with an auxiliary mention identification task trained jointly with event extraction tasks to leverage inter-task dependencies and further incorporates the identified mentions as trigger and argument candidates for their respective tasks. We also introduce MACCROBAT-EE, the first clinical event extraction dataset with event argument annotation. Our experiments demonstrate the robustness of DICE under low data settings for the clinical domain and the benefits of incorporating flexible joint training and mention markers into generative approaches.
High-Throughput Approach to Modeling Healthcare Costs Using Electronic Healthcare Records
Nov 18, 2020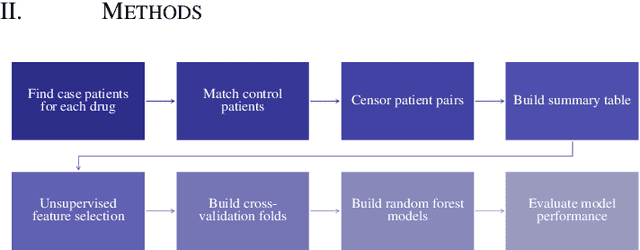
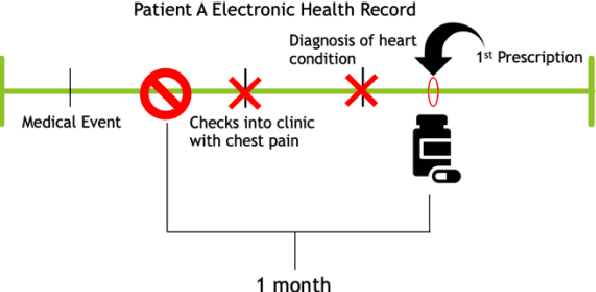
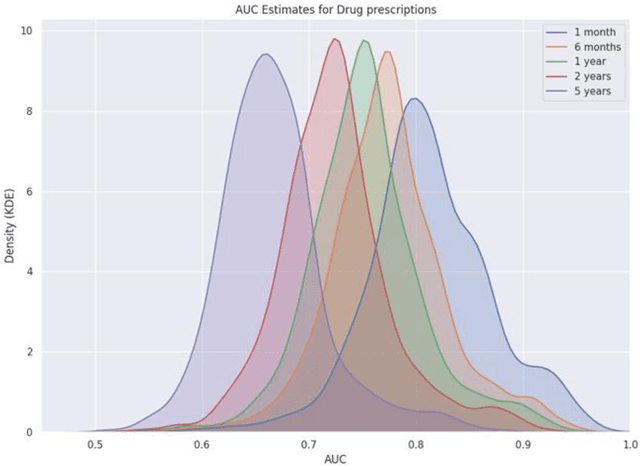
Accurate estimation of healthcare costs is crucial for healthcare systems to plan and effectively negotiate with insurance companies regarding the coverage of patient-care costs. Greater accuracy in estimating healthcare costs would provide mutual benefit for both health systems and the insurers that support these systems by better aligning payment models with patient-care costs. This study presents the results of a generalizable machine learning approach to predicting medical events built from 40 years of data from >860,000 patients pertaining to >6,700 prescription medications, courtesy of Marshfield Clinic in Wisconsin. It was found that models built using this approach performed well when compared to similar studies predicting physician prescriptions of individual medications. In addition to providing a comprehensive predictive model for all drugs in a large healthcare system, the approach taken in this research benefits from potential applicability to a wide variety of other medical events.