 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Subjective Crowd Disagreements for Subjective Data: Uncovering Meaningful CrowdOpinion with Population-level Learning
Jul 07, 2023



Human-annotated data plays a critical role in the fairness of AI systems, including those that deal with life-altering decisions or moderating human-created web/social media content. Conventionally, annotator disagreements are resolved before any learning takes place. However, researchers are increasingly identifying annotator disagreement as pervasive and meaningful. They also question the performance of a system when annotators disagree. Particularly when minority views are disregarded, especially among groups that may already be underrepresented in the annotator population. In this paper, we introduce \emph{CrowdOpinion}\footnote{Accepted for publication at ACL 2023}, an unsupervised learning based approach that uses language features and label distributions to pool similar items into larger samples of label distributions. We experiment with four generative and one density-based clustering method, applied to five linear combinations of label distributions and features. We use five publicly available benchmark datasets (with varying levels of annotator disagreements) from social media (Twitter, Gab, and Reddit). We also experiment in the wild using a dataset from Facebook, where annotations come from the platform itself by users reacting to posts. We evaluate \emph{CrowdOpinion} as a label distribution prediction task using KL-divergence and a single-label problem using accuracy measures.
Domain-specific MT for Low-resource Languages: The case of Bambara-French
Mar 31, 2021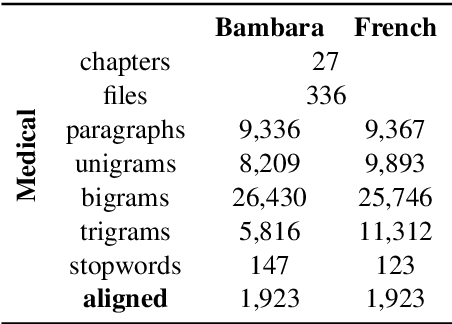
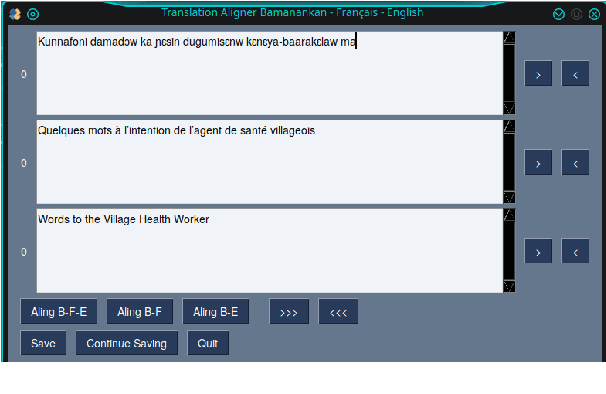
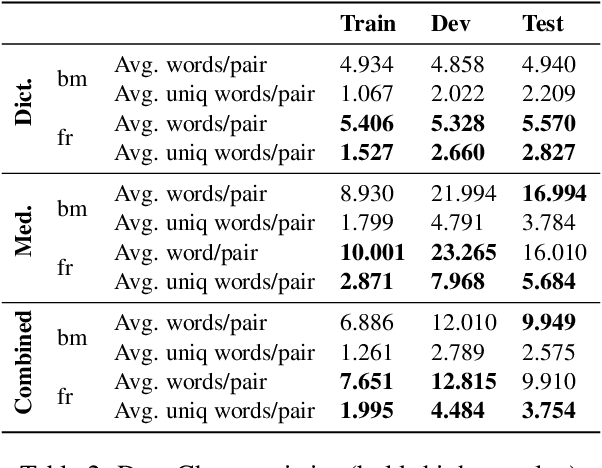
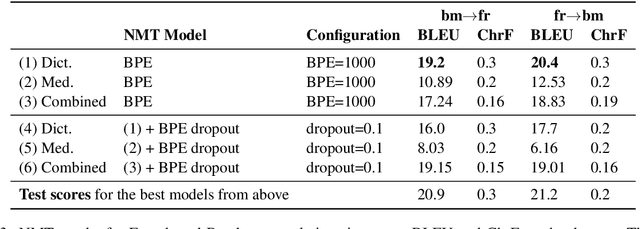
Translating to and from low-resource languages is a challenge for machine translation (MT) systems due to a lack of parallel data. In this paper we address the issue of domain-specific MT for Bambara, an under-resourced Mande language spoken in Mali. We present the first domain-specific parallel dataset for MT of Bambara into and from French. We discuss challenges in working with small quantities of domain-specific data for a low-resource language and we present the results of machine learning experiments on this data.
Neural Machine Translation for Extremely Low-Resource African Languages: A Case Study on Bambara
Nov 10, 2020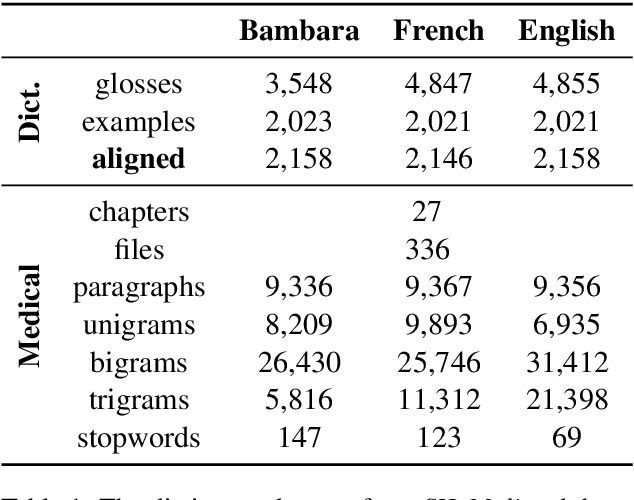
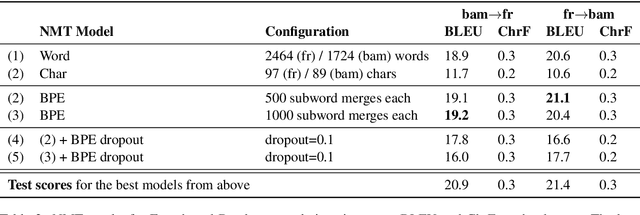
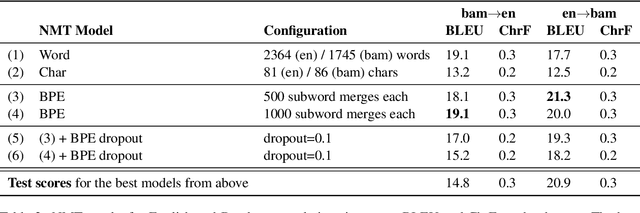
Low-resource languages present unique challenges to (neural) machine translation. We discuss the case of Bambara, a Mande language for which training data is scarce and requires significant amounts of pre-processing. More than the linguistic situation of Bambara itself, the socio-cultural context within which Bambara speakers live poses challenges for automated processing of this language. In this paper, we present the first parallel data set for machine translation of Bambara into and from English and French and the first benchmark results on machine translation to and from Bambara. We discuss challenges in working with low-resource languages and propose strategies to cope with data scarcity in low-resource machine translation (MT).
Assessing Human Translations from French to Bambara for Machine Learning: a Pilot Study
Mar 31, 2020

We present novel methods for assessing the quality of human-translated aligned texts for learning machine translation models of under-resourced languages. Malian university students translated French texts, producing either written or oral translations to Bambara. Our results suggest that similar quality can be obtained from either written or spoken translations for certain kinds of texts. They also suggest specific instructions that human translators should be given in order to improve the quality of their work.