 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Artificial Intelligence, Musical Heritage and the Construction of Peace Narratives: A Case Study in Mali
Jan 21, 2026This study explores the capacity of generative artificial intelligence (Gen AI) to contribute to the construction of peace narratives and the revitalization of musical heritage in Mali. The study has been made in a political and social context where inter-community tensions and social fractures motivate a search for new symbolic frameworks for reconciliation. The study empirically explores three questions: (1) how Gen AI can be used as a tool for musical creation rooted in national languages and traditions; (2) to what extent Gen AI systems enable a balanced hybridization between technological innovation and cultural authenticity; and (3) how AI-assisted musical co-creation can strengthen social cohesion and cultural sovereignty. The experimental results suggest that Gen AI, embedded in a culturally conscious participatory framework, can act as a catalyst for symbolic diplomacy, amplifying local voices instead of standardizing them. However, challenges persist regarding the availability of linguistic corpora, algorithmic censorship, and the ethics of generating compositions derived from copyrighted sources.
Listen, Attend, Understand: a Regularization Technique for Stable E2E Speech Translation Training on High Variance labels
Jan 03, 2026End-to-End Speech Translation often shows slower convergence and worse performance when target transcriptions exhibit high variance and semantic ambiguity. We propose Listen, Attend, Understand (LAU), a semantic regularization technique that constrains the acoustic encoder's latent space during training. By leveraging frozen text embeddings to provide a directional auxiliary loss, LAU injects linguistic groundedness into the acoustic representation without increasing inference cost. We evaluate our method on a Bambara-to-French dataset with 30 hours of Bambara speech translated by non-professionals. Experimental results demonstrate that LAU models achieve comparable performance by standard metrics compared to an E2E-ST system pretrained with 100\% more data and while performing better in preserving semantic meaning. Furthermore, we introduce Total Parameter Drift as a metric to quantify the structural impact of regularization to demonstrate that semantic constraints actively reorganize the encoder's weights to prioritize meaning over literal phonetics. Our findings suggest that LAU is a robust alternative to post-hoc rescoring and a valuable addition to E2E-ST training, especially when training data is scarce and/or noisy.
Kunnafonidilaw ka Cadeau: an ASR dataset of present-day Bambara
Dec 22, 2025



We present Kunkado, a 160-hour Bambara ASR dataset compiled from Malian radio archives to capture present-day spontaneous speech across a wide range of topics. It includes code-switching, disfluencies, background noise, and overlapping speakers that practical ASR systems encounter in real-world use. We finetuned Parakeet-based models on a 33.47-hour human-reviewed subset and apply pragmatic transcript normalization to reduce variability in number formatting, tags, and code-switching annotations. Evaluated on two real-world test sets, finetuning with Kunkado reduces WER from 44.47\% to 37.12\% on one and from 36.07\% to 32.33\% on the other. In human evaluation, the resulting model also outperforms a comparable system with the same architecture trained on 98 hours of cleaner, less realistic speech. We release the data and models to support robust ASR for predominantly oral languages.
Cost Analysis of Human-corrected Transcription for Predominately Oral Languages
Oct 14, 2025
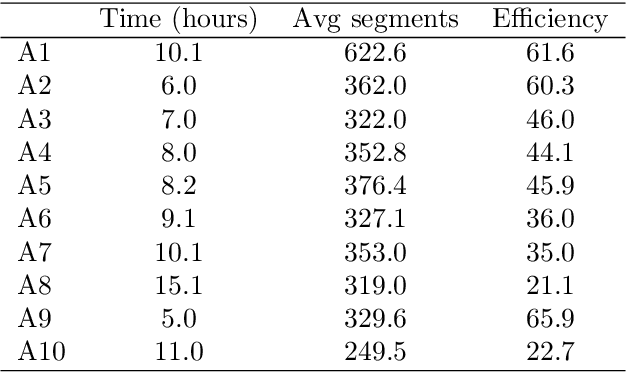

Creating speech datasets for low-resource languages is a critical yet poorly understood challenge, particularly regarding the actual cost in human labor. This paper investigates the time and complexity required to produce high-quality annotated speech data for a subset of low-resource languages, low literacy Predominately Oral Languages, focusing on Bambara, a Manding language of Mali. Through a one-month field study involving ten transcribers with native proficiency, we analyze the correction of ASR-generated transcriptions of 53 hours of Bambara voice data. We report that it takes, on average, 30 hours of human labor to accurately transcribe one hour of speech data under laboratory conditions and 36 hours under field conditions. The study provides a baseline and practical insights for a large class of languages with comparable profiles undertaking the creation of NLP resources.
The Serendipity of Claude AI: Case of the 13 Low-Resource National Languages of Mali
Mar 05, 2025Recent advances in artificial intelligence (AI) and natural language processing (NLP) have improved the representation of underrepresented languages. However, most languages, including Mali's 13 official national languages, continue to be poorly supported or unsupported by automatic translation and generative AI. This situation appears to have slightly improved with certain recent LLM releases. The study evaluated Claude AI's translation performance on each of the 13 national languages of Mali. In addition to ChrF2 and BLEU scores, human evaluators assessed translation accuracy, contextual consistency, robustness to dialect variations, management of linguistic bias, adaptation to a limited corpus, and ease of understanding. The study found that Claude AI performs robustly for languages with very modest language resources and, while unable to produce understandable and coherent texts for Malian languages with minimal resources, still manages to produce results which demonstrate the ability to mimic some elements of the language.
Domain-specific MT for Low-resource Languages: The case of Bambara-French
Mar 31, 2021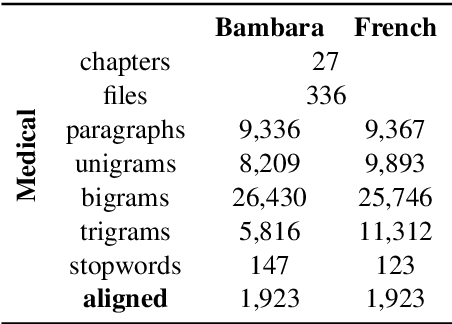
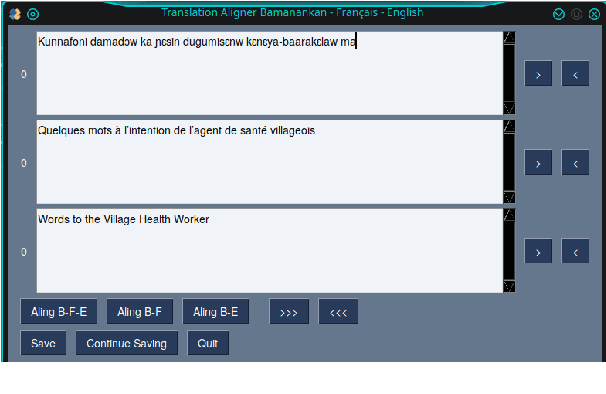
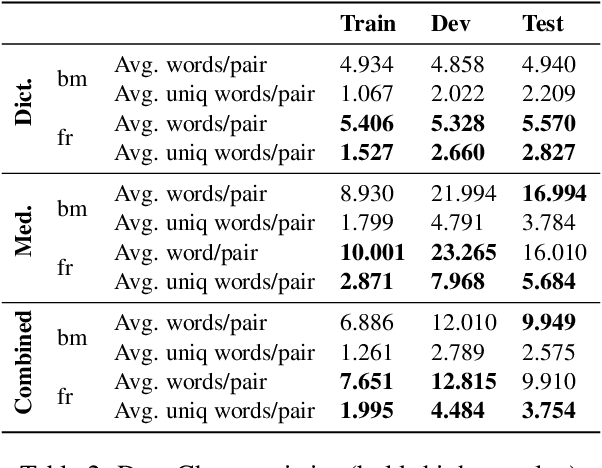
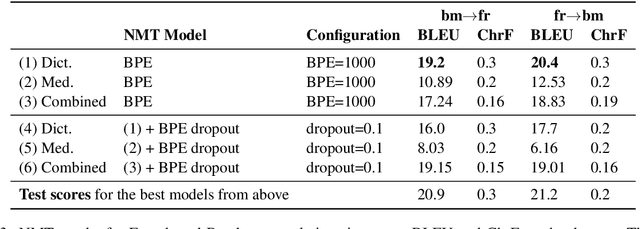
Translating to and from low-resource languages is a challenge for machine translation (MT) systems due to a lack of parallel data. In this paper we address the issue of domain-specific MT for Bambara, an under-resourced Mande language spoken in Mali. We present the first domain-specific parallel dataset for MT of Bambara into and from French. We discuss challenges in working with small quantities of domain-specific data for a low-resource language and we present the results of machine learning experiments on this data.
Neural Machine Translation for Extremely Low-Resource African Languages: A Case Study on Bambara
Nov 10, 2020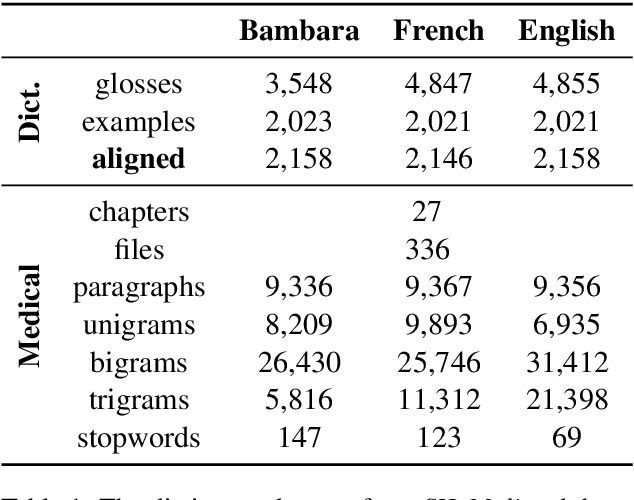
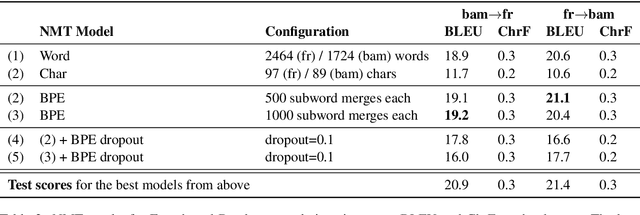
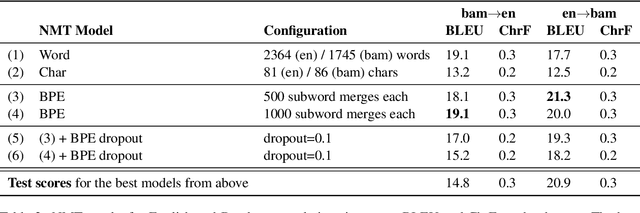
Low-resource languages present unique challenges to (neural) machine translation. We discuss the case of Bambara, a Mande language for which training data is scarce and requires significant amounts of pre-processing. More than the linguistic situation of Bambara itself, the socio-cultural context within which Bambara speakers live poses challenges for automated processing of this language. In this paper, we present the first parallel data set for machine translation of Bambara into and from English and French and the first benchmark results on machine translation to and from Bambara. We discuss challenges in working with low-resource languages and propose strategies to cope with data scarcity in low-resource machine translation (MT).
Assessing Human Translations from French to Bambara for Machine Learning: a Pilot Study
Mar 31, 2020

We present novel methods for assessing the quality of human-translated aligned texts for learning machine translation models of under-resourced languages. Malian university students translated French texts, producing either written or oral translations to Bambara. Our results suggest that similar quality can be obtained from either written or spoken translations for certain kinds of texts. They also suggest specific instructions that human translators should be given in order to improve the quality of their work.