 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORCA: Agentic Reasoning For Hallucination and Adversarial Robustness in Vision-Language Models
Sep 18, 2025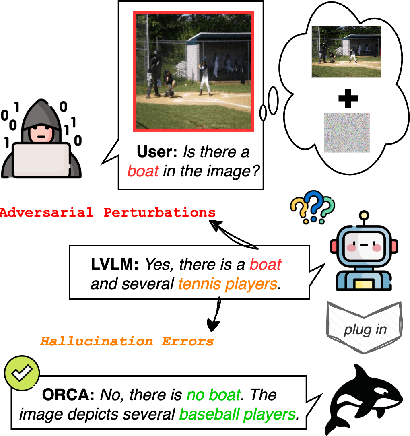



Large Vision-Language Models (LVLMs) exhibit strong multimodal capabilities but remain vulnerable to hallucinations from intrinsic errors and adversarial attacks from external exploitations, limiting their reliability in real-world applications. We present ORCA, an agentic reasoning framework that improves the factual accuracy and adversarial robustness of pretrained LVLMs through test-time structured inference reasoning with a suite of small vision models (less than 3B parameters). ORCA operates via an Observe--Reason--Critique--Act loop, querying multiple visual tools with evidential questions, validating cross-model inconsistencies, and refining predictions iteratively without access to model internals or retraining. ORCA also stores intermediate reasoning traces, which supports auditable decision-making. Though designed primarily to mitigate object-level hallucinations, ORCA also exhibits emergent adversarial robustness without requiring adversarial training or defense mechanisms. We evaluate ORCA across three settings: (1) clean images on hallucination benchmarks, (2) adversarially perturbed images without defense, and (3) adversarially perturbed images with defense applied. On the POPE hallucination benchmark, ORCA improves standalone LVLM performance by +3.64\% to +40.67\% across different subsets. Under adversarial perturbations on POPE, ORCA achieves an average accuracy gain of +20.11\% across LVLMs. When combined with defense techniques on adversarially perturbed AMBER images, ORCA further improves standalone LVLM performance, with gains ranging from +1.20\% to +48.00\% across evaluation metrics. These results demonstrate that ORCA offers a promising path toward building more reliable and robust multimodal systems.
Hydra: An Agentic Reasoning Approach for Enhancing Adversarial Robustness and Mitigating Hallucinations in Vision-Language Models
Apr 19, 2025



To develop trustworthy Vision-Language Models (VLMs), it is essential to address adversarial robustness and hallucination mitigation, both of which impact factual accuracy in high-stakes applications such as defense and healthcare. Existing methods primarily focus on either adversarial defense or hallucination post-hoc correction, leaving a gap in unified robustness strategies. We introduce \textbf{Hydra}, an adaptive agentic framework that enhances plug-in VLMs through iterative reasoning, structured critiques, and cross-model verification, improving both resilience to adversarial perturbations and intrinsic model errors. Hydra employs an Action-Critique Loop, where it retrieves and critiques visual information, leveraging Chain-of-Thought (CoT) and In-Context Learning (ICL) techniques to refine outputs dynamically. Unlike static post-hoc correction methods, Hydra adapts to both adversarial manipulations and intrinsic model errors, making it robust to malicious perturbations and hallucination-related inaccuracies. We evaluate Hydra on four VLMs, three hallucination benchmarks, two adversarial attack strategies, and two adversarial defense methods, assessing performance on both clean and adversarial inputs. Results show that Hydra surpasses plug-in VLMs and state-of-the-art (SOTA) dehallucination methods, even without explicit adversarial defenses, demonstrating enhanced robustness and factual consistency. By bridging adversarial resistance and hallucination mitigation, Hydra provides a scalable, training-free solution for improving the reliability of VLMs in real-world applications.