 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Model Refinement: Muon-Optimized Distillation and Quantization for LLM Deployment
Jan 14, 2026Large Language Models (LLMs) enable advanced natural language processing but face deployment challenges on resource-constrained edge devices due to high computational, memory, and energy demands. Optimizing these models requires addressing three key challenges: acquiring task-specific data, fine-tuning for performance, and compressing models to accelerate inference while reducing resource demands. We propose an integrated framework combining GPTQ-based quantization, low-rank adaptation (LoRA), and a specialized data distillation process to significantly reduce model size and complexity while preserving or enhancing task-specific performance. By leveraging data distillation, knowledge distillation via Kullback-Leibler divergence, Bayesian hyperparameter optimization, and the Muon optimizer, our pipeline achieves up to 2x memory compression (e.g., reducing a 6GB model to 3GB) and enables efficient inference for specialized tasks. Empirical results demonstrate superior performance on standard LLM benchmarks compared to GPTQ quantization alone, with the Muon optimizer notably enhancing fine-tuned models' resistance to accuracy decay during quantization.
GFT: Graph Feature Tuning for Efficient Point Cloud Analysis
Nov 13, 2025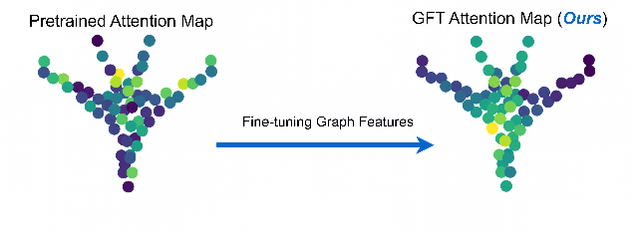
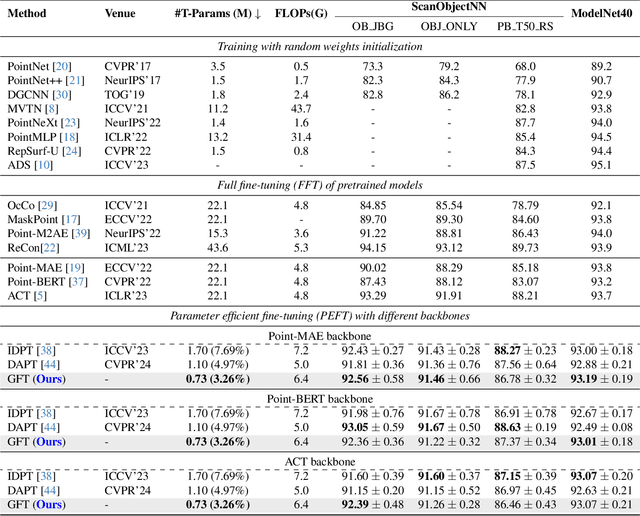
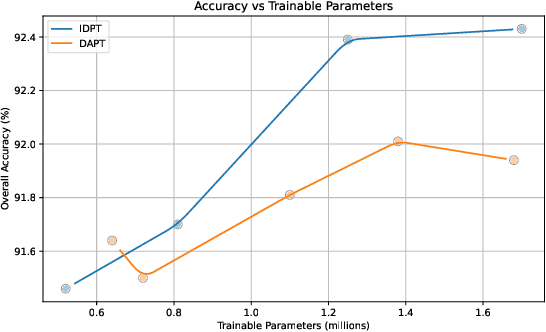
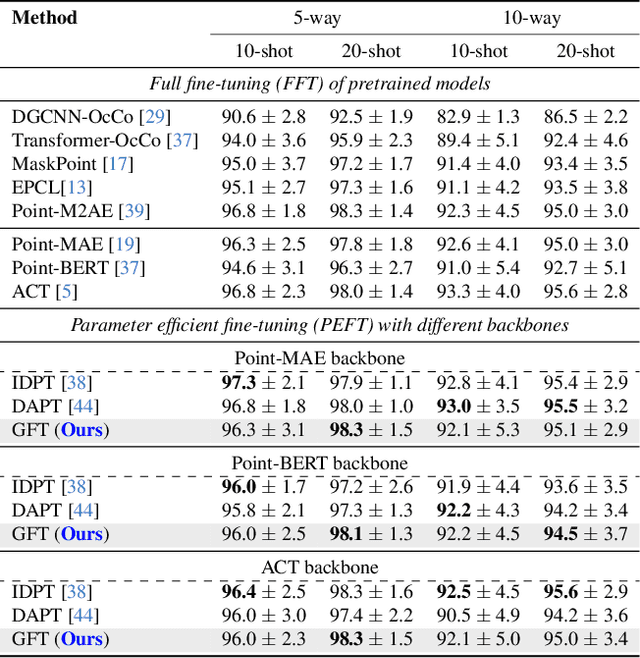
Parameter-efficient fine-tuning (PEFT) significantly reduces computational and memory costs by updating only a small subset of the model's parameters, enabling faster adaptation to new tasks with minimal loss in performance. Previous studies have introduced PEFTs tailored for point cloud data, as general approaches are suboptimal. To further reduce the number of trainable parameters, we propose a point-cloud-specific PEFT, termed Graph Features Tuning (GFT), which learns a dynamic graph from initial tokenized inputs of the transformer using a lightweight graph convolution network and passes these graph features to deeper layers via skip connections and efficient cross-attention modules. Extensive experiments on object classification and segmentation tasks show that GFT operates in the same domain, rivalling existing methods, while reducing the trainable parameters. Code is at https://github.com/manishdhakal/GFT.
On Accelerating Edge AI: Optimizing Resource-Constrained Environments
Jan 25, 2025Resource-constrained edge deployments demand AI solutions that balance high performance with stringent compute, memory, and energy limitations. In this survey, we present a comprehensive overview of the primary strategies for accelerating deep learning models under such constraints. First, we examine model compression techniques-pruning, quantization, tensor decomposition, and knowledge distillation-that streamline large models into smaller, faster, and more efficient variants. Next, we explore Neural Architecture Search (NAS), a class of automated methods that discover architectures inherently optimized for particular tasks and hardware budgets. We then discuss compiler and deployment frameworks, such as TVM, TensorRT, and OpenVINO, which provide hardware-tailored optimizations at inference time. By integrating these three pillars into unified pipelines, practitioners can achieve multi-objective goals, including latency reduction, memory savings, and energy efficiency-all while maintaining competitive accuracy. We also highlight emerging frontiers in hierarchical NAS, neurosymbolic approaches, and advanced distillation tailored to large language models, underscoring open challenges like pre-training pruning for massive networks. Our survey offers practical insights, identifies current research gaps, and outlines promising directions for building scalable, platform-independent frameworks to accelerate deep learning models at the edge.
Semantic Edge Computing and Semantic Communications in 6G Networks: A Unifying Survey and Research Challenges
Nov 27, 2024Semantic Edge Computing (SEC) and Semantic Communications (SemComs) have been proposed as viable approaches to achieve real-time edge-enabled intelligence in sixth-generation (6G) wireless networks. On one hand, SemCom leverages the strength of Deep Neural Networks (DNNs) to encode and communicate the semantic information only, while making it robust to channel distortions by compensating for wireless effects. Ultimately, this leads to an improvement in the communication efficiency. On the other hand, SEC has leveraged distributed DNNs to divide the computation of a DNN across different devices based on their computational and networking constraints. Although significant progress has been made in both fields, the literature lacks a systematic view to connect both fields. In this work, we fulfill the current gap by unifying the SEC and SemCom fields. We summarize the research problems in these two fields and provide a comprehensive review of the state of the art with a focus on their technical strengths and challenges.
Computational complexity reduction of deep neural networks
Jul 29, 2022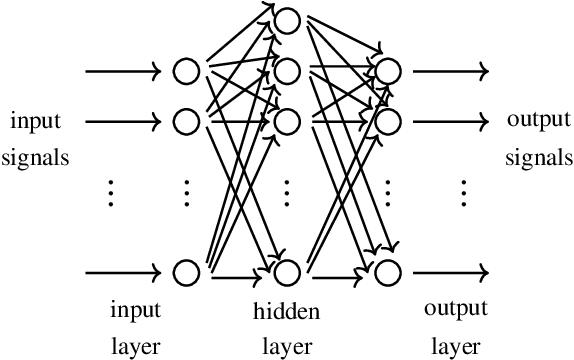
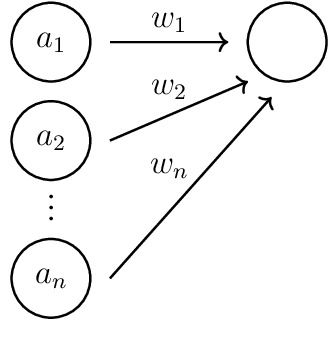
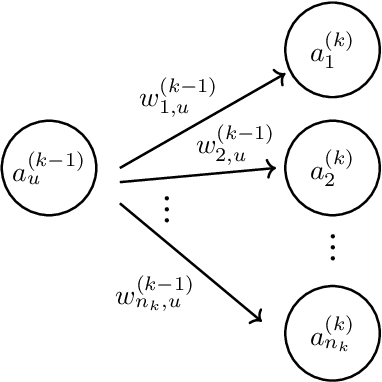
Deep neural networks (DNN) have been widely used and play a major role in the field of computer vision and autonomous navigation. However, these DNNs are computationally complex and their deployment over resource-constrained platforms is difficult without additional optimizations and customization. In this manuscript, we describe an overview of DNN architecture and propose methods to reduce computational complexity in order to accelerate training and inference speeds to fit them on edge computing platforms with low computational resources.
* 10 pages, 9 figures
Genetic optimization algorithms applied toward mission computability models
May 27, 2020Genetic algorithms are modeled after the biological evolutionary processes that use natural selection to select the best species to survive. They are heuristics based and low cost to compute. Genetic algorithms use selection, crossover, and mutation to obtain a feasible solution to computational problems. In this paper, we describe our genetic optimization algorithms to a mission-critical and constraints-aware computation problem.
Solving machine learning optimization problems using quantum computers
Nov 17, 2019

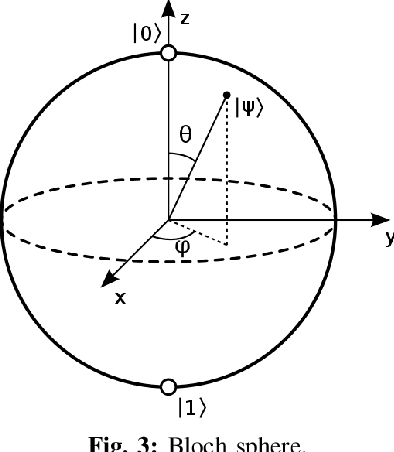
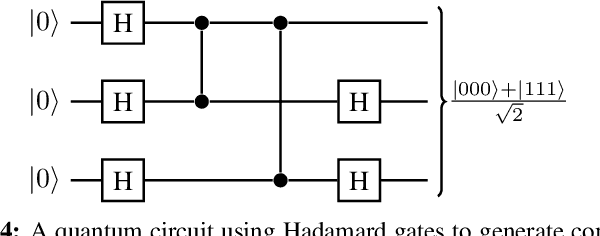
Classical optimization algorithms in machine learning often take a long time to compute when applied to a multi-dimensional problem and require a huge amount of CPU and GPU resource. Quantum parallelism has a potential to speed up machine learning algorithms. We describe a generic mathematical model to leverage quantum parallelism to speed-up machine learning algorithms. We also apply quantum machine learning and quantum parallelism applied to a $3$-dimensional image that vary with time.
Optimization problems with low SWaP tactical Computing
Feb 13, 2019In a resource-constrained, contested environment, computing resources need to be aware of possible size, weight, and power (SWaP) restrictions. SWaP-aware computational efficiency depends upon optimization of computational resources and intelligent time versus efficiency tradeoffs in decision making. In this paper we address the complexity of various optimization strategies related to low SWaP computing. Due to these restrictions, only a small subset of less complicated and fast computable algorithms can be used for tactical, adaptive computing.
Complexity and mission computability of adaptive computing systems
Aug 29, 2018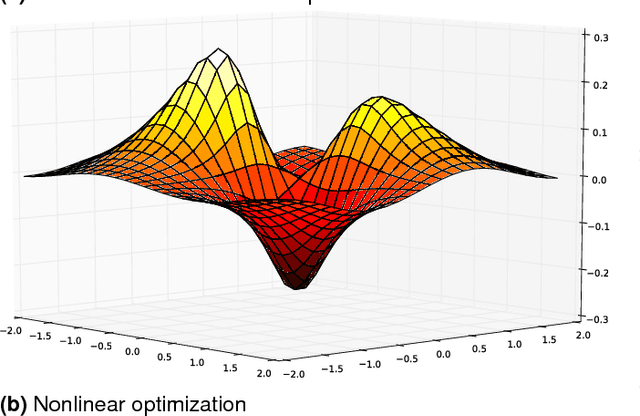
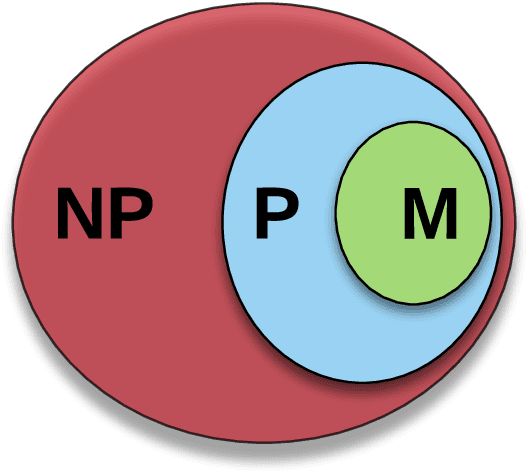
There is a subset of computational problems that are computable in polynomial time for which an existing algorithm may not complete due to a lack of high performance technology on a mission field. We define a subclass of deterministic polynomial time complexity class called mission class, as many polynomial problems are not computable in mission time. By focusing on such subclass of languages in the context for successful military applications, we also discuss their computational and communicational constraints. We investigate feasible (non)linear models that will minimize energy and maximize memory, efficiency, and computational power, and also provide an approximate solution obtained within a pre-determined length of computation time using limited resources so that an optimal solution to a language could be determined.