 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the impact of stereo processing -- a study for extending the Open Dataset of Audio Quality (ODAQ)
Dec 16, 2025In this paper, we present an initial study for extending Open Dataset of Audio Quality (ODAQ) towards the impact of stereo processing. Monaural artifacts from ODAQ were adapted in combinations with left-right (LR) and mid-side (MS) stereo processing, across stimuli including solo instruments, typical wide stereo mixes and and hard-panned mixes. Listening tests in different presentation context -- with and without direct comparison of MS and LR conditions -- were conducted to collect subjective data beyond monaural artifacts while also scrutinizing the listening test methodology. The ODAQ dataset is extended with new material along with subjective scores from 16 expert listeners. The listening test results show substantial influences of the stimuli's spatial characteristics as well as the presentation context. Notably, several significant disparities between LR and MS only occur when presented in direct comparison. The findings suggest that listeners primarily assess timbral impairments when spatial characteristics are consistent and focus on stereo image only when timbral quality is similar. The rating of an additional mono anchor was overall consistent across different stereo characteristics, averaging at 65 on the MUSHRA scale, further corroborating that listeners prioritize timbral over spatial impressions.
Expanding and Analyzing ODAQ -- the Open Dataset of Audio Quality
Apr 01, 2025The Open Dataset of Audio Quality (ODAQ) was recently introduced to address the scarcity of openly available audio datasets with corresponding subjective quality scores. The dataset, released under permissive licenses, comprises audio material processed using six different signal processing methods operating at five quality levels, along with corresponding subjective test results. To expand the dataset, we provided listener training to university students to conduct further subjective tests and obtained results consistent with previous expert listeners. We also showed how different training approaches affect the use of absolute scales and anchors. The expanded dataset now comprises results from three international laboratories providing a total of 42 listeners and 10080 subjective scores. This paper provides the details of the expansion and an in-depth analysis. As part of this analysis, we initiate the use of ODAQ as a benchmark to evaluate objective audio quality metrics in their ability to predict subjective scores
InTune: Reinforcement Learning-based Data Pipeline Optimization for Deep Recommendation Models
Aug 13, 2023



Deep learning-based recommender models (DLRMs) have become an essential component of many modern recommender systems. Several companies are now building large compute clusters reserved only for DLRM training, driving new interest in cost- and time- saving optimizations. The systems challenges faced in this setting are unique; while typical deep learning training jobs are dominated by model execution, the most important factor in DLRM training performance is often online data ingestion. In this paper, we explore the unique characteristics of this data ingestion problem and provide insights into DLRM training pipeline bottlenecks and challenges. We study real-world DLRM data processing pipelines taken from our compute cluster at Netflix to observe the performance impacts of online ingestion and to identify shortfalls in existing pipeline optimizers. We find that current tooling either yields sub-optimal performance, frequent crashes, or else requires impractical cluster re-organization to adopt. Our studies lead us to design and build a new solution for data pipeline optimization, InTune. InTune employs a reinforcement learning (RL) agent to learn how to distribute the CPU resources of a trainer machine across a DLRM data pipeline to more effectively parallelize data loading and improve throughput. Our experiments show that InTune can build an optimized data pipeline configuration within only a few minutes, and can easily be integrated into existing training workflows. By exploiting the responsiveness and adaptability of RL, InTune achieves higher online data ingestion rates than existing optimizers, thus reducing idle times in model execution and increasing efficiency. We apply InTune to our real-world cluster, and find that it increases data ingestion throughput by as much as 2.29X versus state-of-the-art data pipeline optimizers while also improving both CPU & GPU utilization.
Gradient Boosted Decision Tree Neural Network
Nov 05, 2019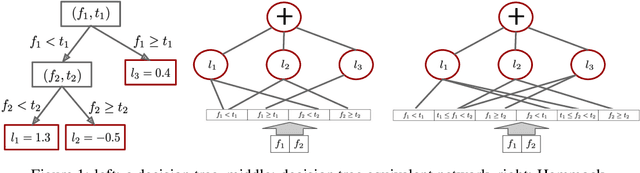
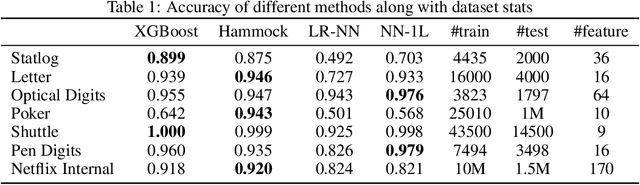
In this paper we propose a method to build a neural network that is similar to an ensemble of decision trees. We first illustrate how to convert a learned ensemble of decision trees to a single neural network with one hidden layer and an input transformation. We then relax some properties of this network such as thresholds and activation functions to train an approximately equivalent decision tree ensemble. The final model, Hammock, is surprisingly simple: a fully connected two layers neural network where the input is quantized and one-hot encoded. Experiments on large and small datasets show this simple method can achieve performance similar to that of Gradient Boosted Decision Trees.