 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Hashing with Hash-Consistent Large Margin Proxy Embeddings
Jul 27, 2020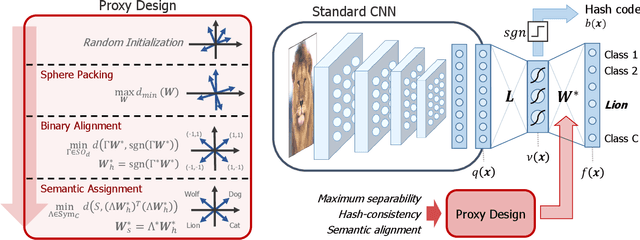
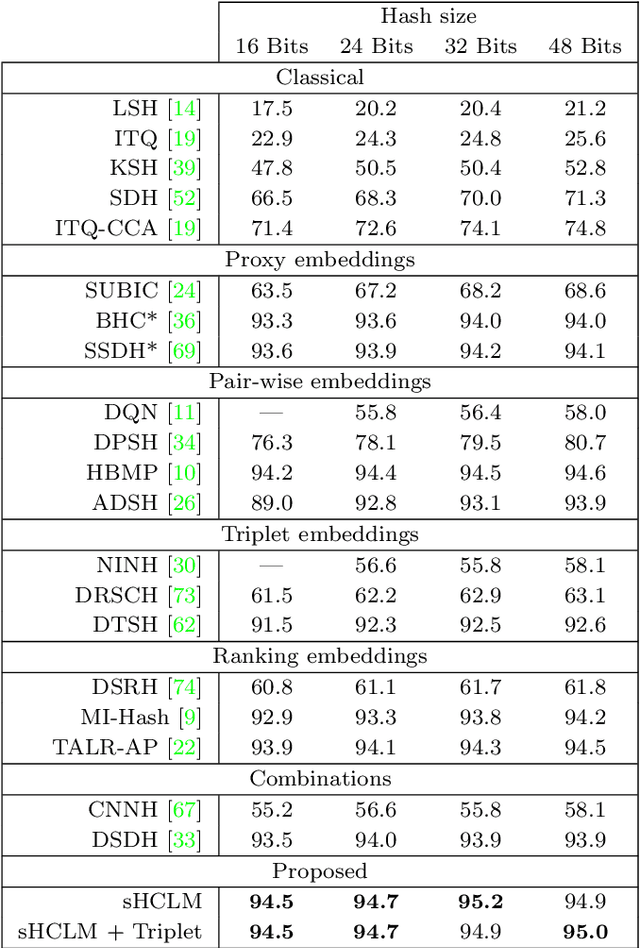
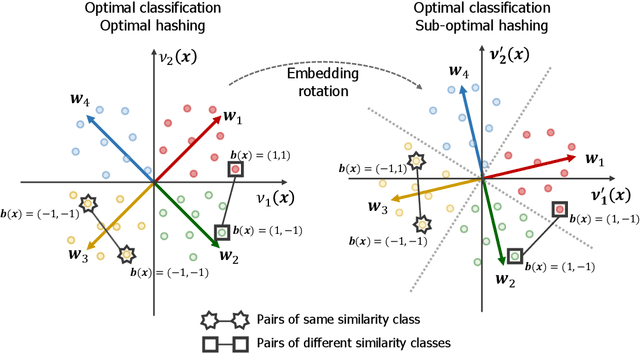
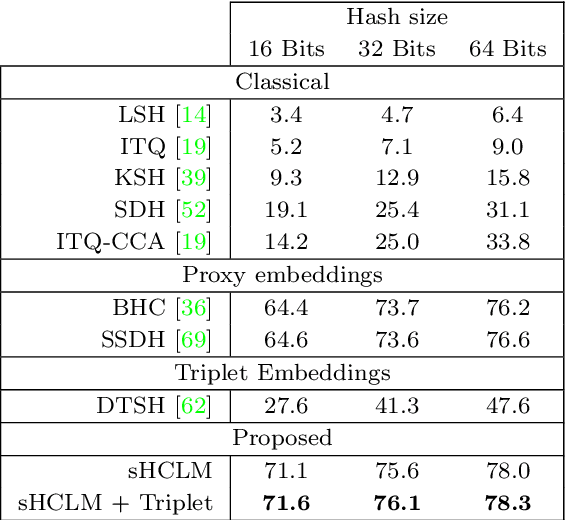
Image hash codes are produced by binarizing the embeddings of convolutional neural networks (CNN) trained for either classification or retrieval. While proxy embeddings achieve good performance on both tasks, they are non-trivial to binarize, due to a rotational ambiguity that encourages non-binary embeddings. The use of a fixed set of proxies (weights of the CNN classification layer) is proposed to eliminate this ambiguity, and a procedure to design proxy sets that are nearly optimal for both classification and hashing is introduced. The resulting hash-consistent large margin (HCLM) proxies are shown to encourage saturation of hashing units, thus guaranteeing a small binarization error, while producing highly discriminative hash-codes. A semantic extension (sHCLM), aimed to improve hashing performance in a transfer scenario, is also proposed. Extensive experiments show that sHCLM embeddings achieve significant improvements over state-of-the-art hashing procedures on several small and large datasets, both within and beyond the set of training classes.
Gradient Boosted Decision Tree Neural Network
Nov 05, 2019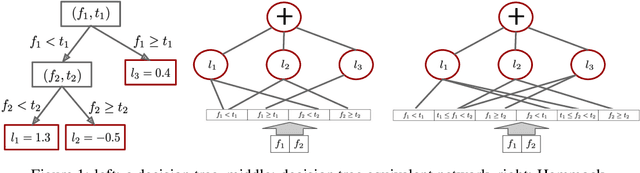
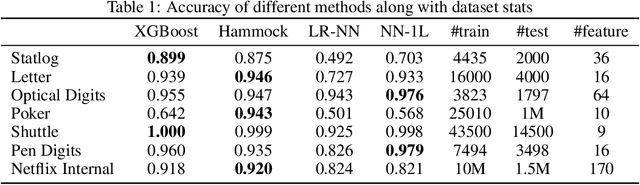
In this paper we propose a method to build a neural network that is similar to an ensemble of decision trees. We first illustrate how to convert a learned ensemble of decision trees to a single neural network with one hidden layer and an input transformation. We then relax some properties of this network such as thresholds and activation functions to train an approximately equivalent decision tree ensemble. The final model, Hammock, is surprisingly simple: a fully connected two layers neural network where the input is quantized and one-hot encoded. Experiments on large and small datasets show this simple method can achieve performance similar to that of Gradient Boosted Decision Trees.
Learning Complexity-Aware Cascades for Deep Pedestrian Detection
Jul 19, 2015
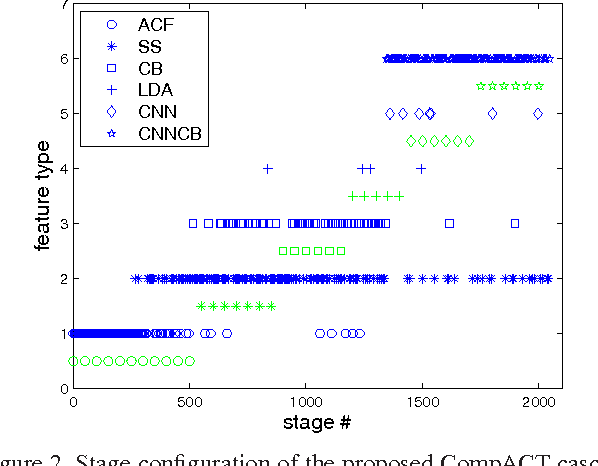
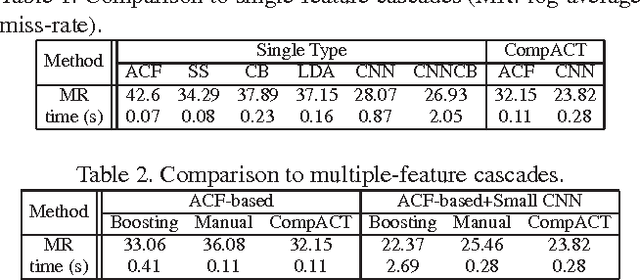

The design of complexity-aware cascaded detectors, combining features of very different complexities, is considered. A new cascade design procedure is introduced, by formulating cascade learning as the Lagrangian optimization of a risk that accounts for both accuracy and complexity. A boosting algorithm, denoted as complexity aware cascade training (CompACT), is then derived to solve this optimization. CompACT cascades are shown to seek an optimal trade-off between accuracy and complexity by pushing features of higher complexity to the later cascade stages, where only a few difficult candidate patches remain to be classified. This enables the use of features of vastly different complexities in a single detector. In result, the feature pool can be expanded to features previously impractical for cascade design, such as the responses of a deep convolutional neural network (CNN). This is demonstrated through the design of a pedestrian detector with a pool of features whose complexities span orders of magnitude. The resulting cascade generalizes the combination of a CNN with an object proposal mechanism: rather than a pre-processing stage, CompACT cascades seamlessly integrate CNNs in their stages. This enables state of the art performance on the Caltech and KITTI datasets, at fairly fast speeds.
Multi-view Face Detection Using Deep Convolutional Neural Networks
Apr 20, 2015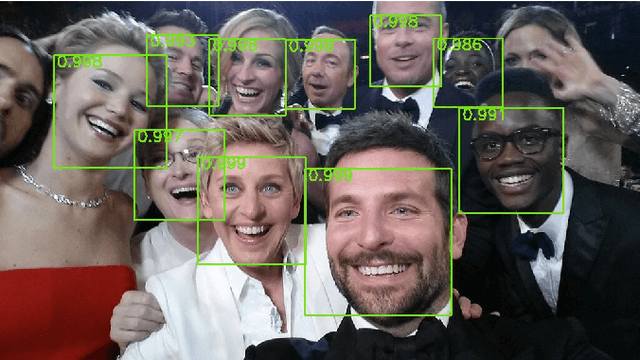
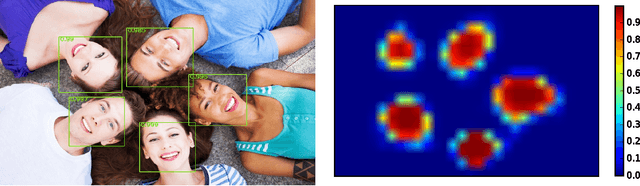

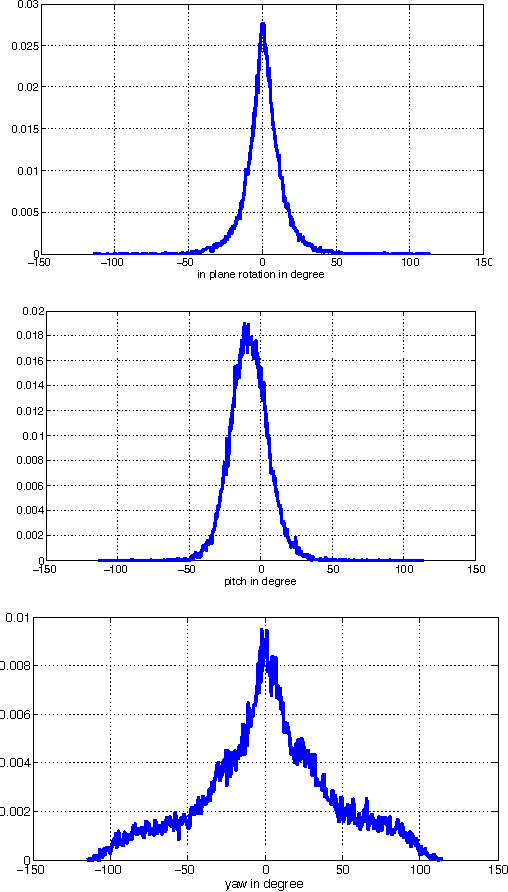
In this paper we consider the problem of multi-view face detection. While there has been significant research on this problem, current state-of-the-art approaches for this task require annotation of facial landmarks, e.g. TSM [25], or annotation of face poses [28, 22]. They also require training dozens of models to fully capture faces in all orientations, e.g. 22 models in HeadHunter method [22]. In this paper we propose Deep Dense Face Detector (DDFD), a method that does not require pose/landmark annotation and is able to detect faces in a wide range of orientations using a single model based on deep convolutional neural networks. The proposed method has minimal complexity; unlike other recent deep learning object detection methods [9], it does not require additional components such as segmentation, bounding-box regression, or SVM classifiers. Furthermore, we analyzed scores of the proposed face detector for faces in different orientations and found that 1) the proposed method is able to detect faces from different angles and can handle occlusion to some extent, 2) there seems to be a correlation between dis- tribution of positive examples in the training set and scores of the proposed face detector. The latter suggests that the proposed methods performance can be further improved by using better sampling strategies and more sophisticated data augmentation techniques. Evaluations on popular face detection benchmark datasets show that our single-model face detector algorithm has similar or better performance compared to the previous methods, which are more complex and require annotations of either different poses or facial landmarks.