 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaturn: Efficient Multi-Large-Model Deep Learning
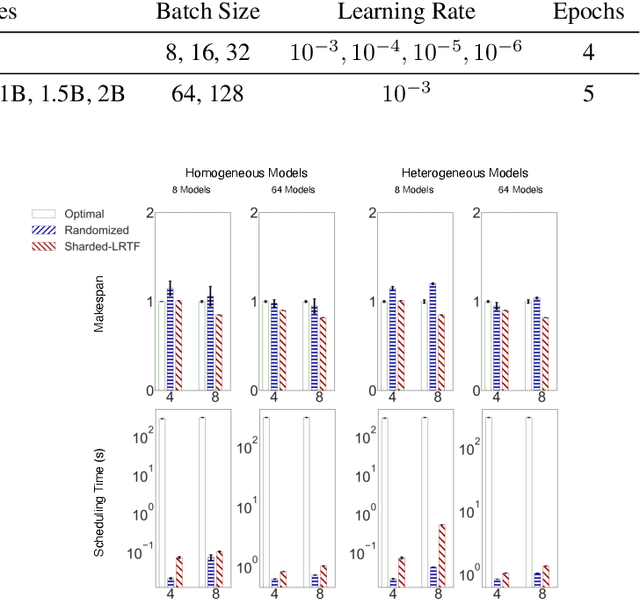
Nov 06, 2023In this paper, we propose Saturn, a new data system to improve the efficiency of multi-large-model training (e.g., during model selection/hyperparameter optimization). We first identify three key interconnected systems challenges for users building large models in this setting -- parallelism technique selection, distribution of GPUs over jobs, and scheduling. We then formalize these as a joint problem, and build a new system architecture to tackle these challenges simultaneously. Our evaluations show that our joint-optimization approach yields 39-49% lower model selection runtimes than typical current DL practice.
Saturn: An Optimized Data System for Large Model Deep Learning Workloads
Sep 03, 2023
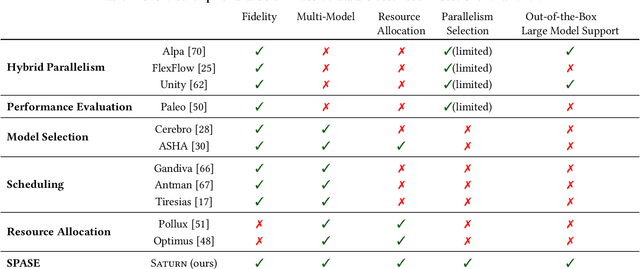

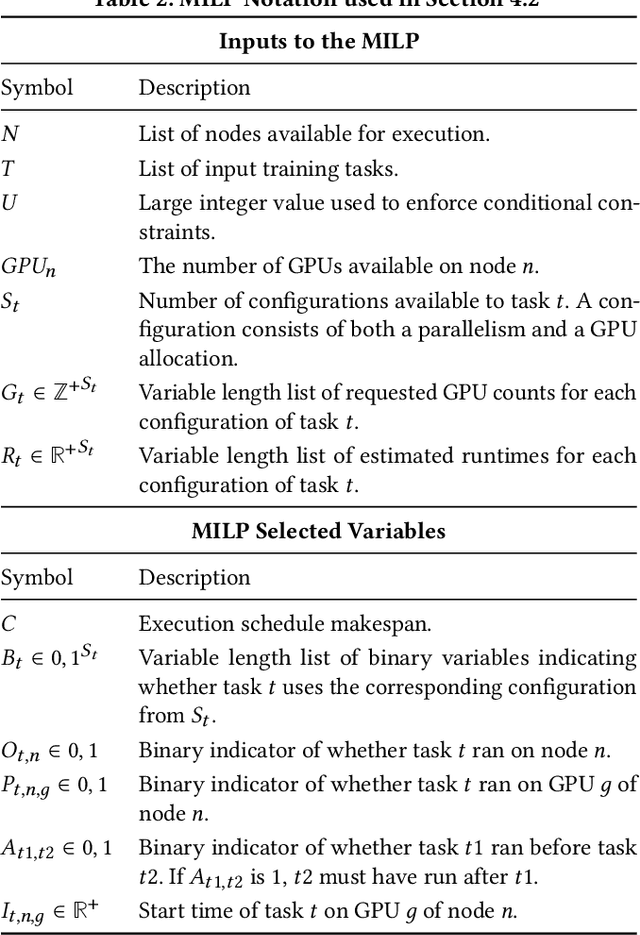
Large language models such as GPT-3 & ChatGPT have transformed deep learning (DL), powering applications that have captured the public's imagination. These models are rapidly being adopted across domains for analytics on various modalities, often by finetuning pre-trained base models. Such models need multiple GPUs due to both their size and computational load, driving the development of a bevy of "model parallelism" techniques & tools. Navigating such parallelism choices, however, is a new burden for end users of DL such as data scientists, domain scientists, etc. who may lack the necessary systems knowhow. The need for model selection, which leads to many models to train due to hyper-parameter tuning or layer-wise finetuning, compounds the situation with two more burdens: resource apportioning and scheduling. In this work, we tackle these three burdens for DL users in a unified manner by formalizing them as a joint problem that we call SPASE: Select a Parallelism, Allocate resources, and SchedulE. We propose a new information system architecture to tackle the SPASE problem holistically, representing a key step toward enabling wider adoption of large DL models. We devise an extensible template for existing parallelism schemes and combine it with an automated empirical profiler for runtime estimation. We then formulate SPASE as an MILP. We find that direct use of an MILP-solver is significantly more effective than several baseline heuristics. We optimize the system runtime further with an introspective scheduling approach. We implement all these techniques into a new data system we call Saturn. Experiments with benchmark DL workloads show that Saturn achieves 39-49% lower model selection runtimes than typical current DL practice.
InTune: Reinforcement Learning-based Data Pipeline Optimization for Deep Recommendation Models
Aug 13, 2023



Deep learning-based recommender models (DLRMs) have become an essential component of many modern recommender systems. Several companies are now building large compute clusters reserved only for DLRM training, driving new interest in cost- and time- saving optimizations. The systems challenges faced in this setting are unique; while typical deep learning training jobs are dominated by model execution, the most important factor in DLRM training performance is often online data ingestion. In this paper, we explore the unique characteristics of this data ingestion problem and provide insights into DLRM training pipeline bottlenecks and challenges. We study real-world DLRM data processing pipelines taken from our compute cluster at Netflix to observe the performance impacts of online ingestion and to identify shortfalls in existing pipeline optimizers. We find that current tooling either yields sub-optimal performance, frequent crashes, or else requires impractical cluster re-organization to adopt. Our studies lead us to design and build a new solution for data pipeline optimization, InTune. InTune employs a reinforcement learning (RL) agent to learn how to distribute the CPU resources of a trainer machine across a DLRM data pipeline to more effectively parallelize data loading and improve throughput. Our experiments show that InTune can build an optimized data pipeline configuration within only a few minutes, and can easily be integrated into existing training workflows. By exploiting the responsiveness and adaptability of RL, InTune achieves higher online data ingestion rates than existing optimizers, thus reducing idle times in model execution and increasing efficiency. We apply InTune to our real-world cluster, and find that it increases data ingestion throughput by as much as 2.29X versus state-of-the-art data pipeline optimizers while also improving both CPU & GPU utilization.
Systems for Parallel and Distributed Large-Model Deep Learning Training
Jan 06, 2023



Deep learning (DL) has transformed applications in a variety of domains, including computer vision, natural language processing, and tabular data analysis. The search for improved DL model accuracy has led practitioners to explore increasingly large neural architectures, with some recent Transformer models spanning hundreds of billions of learnable parameters. These designs have introduced new scale-driven systems challenges for the DL space, such as memory bottlenecks, poor runtime efficiency, and high costs of model development. Efforts to address these issues have explored techniques such as parallelization of neural architectures, spilling data across the memory hierarchy, and memory-efficient data representations. This survey will explore the large-model training systems landscape, highlighting key challenges and the various techniques that have been used to address them.
Hydra: A System for Large Multi-Model Deep Learning
Oct 23, 2021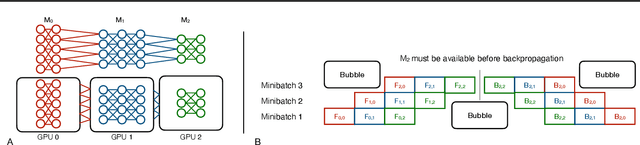

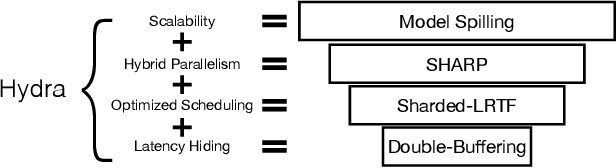
Training deep learning (DL) models that do not fit into the memory of a single GPU is a vexed process, forcing users to procure multiple GPUs to adopt model-parallel execution. Unfortunately, sequential dependencies in neural architectures often block efficient multi-device training, leading to suboptimal performance. We present 'model spilling', a technique aimed at models such as Transformers and CNNs to move groups of layers, or shards, between DRAM and GPU memory, thus enabling arbitrarily large models to be trained even on just one GPU. We then present a set of novel techniques leveraging spilling to raise efficiency for multi-model training workloads such as model selection: a new hybrid of task- and model-parallelism, a new shard scheduling heuristic, and 'double buffering' to hide latency. We prototype our ideas into a system we call HYDRA to support seamless single-model and multi-model training of large DL models. Experiments with real benchmark workloads show that HYDRA is over 7x faster than regular model parallelism and over 50% faster than state-of-the-art industrial tools for pipeline parallelism.
Model-Parallel Model Selection for Deep Learning Systems
Jul 14, 2021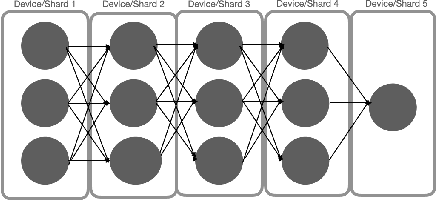
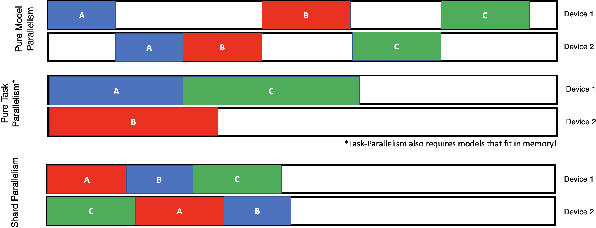
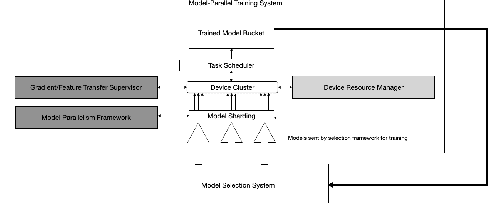
As deep learning becomes more expensive, both in terms of time and compute, inefficiencies in machine learning (ML) training prevent practical usage of state-of-the-art models for most users. The newest model architectures are simply too large to be fit onto a single processor. To address the issue, many ML practitioners have turned to model parallelism as a method of distributing the computational requirements across several devices. Unfortunately, the sequential nature of neural networks causes very low efficiency and device utilization in model parallel training jobs. We propose a new form of "shard parallelism" combining task and model parallelism, then package it into a framework we name Hydra. Hydra recasts the problem of model parallelism in the multi-model context to produce a fine-grained parallel workload of independent model shards, rather than independent models. This new parallel design promises dramatic speedups relative to the traditional model parallelism paradigm.